
 阅读时间大约7分钟(2610字)
阅读时间大约7分钟(2610字)
2025-05-08 全面突围!AI芯片与机器人“大脑”如何实现协同设计?
来源:文心一言
AI芯片是具身智能实现实时感知、决策与执行闭环的核心算力基座,其自主可控性直接关系国家人工智能战略安全。
作者:余柯 出品:机器人产业应用
AI芯片是具身智能实现实时感知、决策与执行闭环的核心算力基座,其自主可控性直接关系国家人工智能战略安全。当前AI芯片在具身智能领域,起到的作用至关重要,从算力需求到低功耗设计,以及软硬件协同,国产AI芯片正实现技术-场景-生态的全面突围,本文我们将从政策背景、国产芯片突围路径、大模型与芯片协同优化等方面进行简析。
01
政策背景:国产AI芯片上升为国家战略
AI芯片是具身智能实现实时感知、决策与执行闭环的核心算力基座,其自主可控性直接关系国家人工智能战略安全。北京、深圳等城市已将AI芯片列为核心技术攻关方向,政策支持力度空前。
•北京:发布《具身智能科技创新与产业培育行动计划(2025-2027年)》,明确提出研制高性能具身智能芯片,覆盖云端推理与端侧低功耗场景,目标到2025年实现国产AI芯片在推理端替代率达30%。
•深圳:通过《人工智能先锋城市行动计划》,重点支持端侧芯片算力与模型适配能力提升,推动轻量化模型与芯片协同优化。
目前,一线城市通过技术攻关和产业链协同,构建自主可控的AI芯片生态,突破国际技术封锁。
02
AI芯片的在具身智能领域的关键作用
三大核心作用
2.1
算力需求:从通用到精准定制
具身智能需实时处理视觉、语音、运动等多模态数据流(如机器人每秒处理数十GB环境信息),传统通用芯片(如CPU)因算力分散、延迟高(通常>50ms)难以满足需求。国产芯片通过异构计算架构实现算力定向释放:
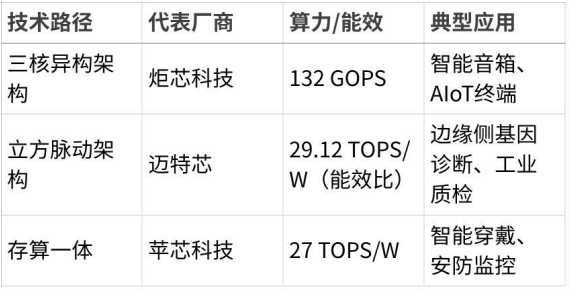
技术亮点:
•炬芯科技ATS362X:通过“CPU+DSP+NPU”三核分工,定向优化音频处理能力(如声纹识别延迟<10ms),算力达132 GOPS,支持智能音箱实时交互。
•迈特芯立方脉动架构:能效比达29.12 TOPS/W(是传统GPU的3倍),专为大语言模型边缘部署设计,带宽利用率75%,可加速基因序列分析效率50%。
2.2
低功耗设计:突破“能耗墙”
具身智能终端(如无人机、服务机器人)需在有限电池容量下维持高性能运行。传统芯片因频繁数据搬运导致能耗高(如GPU功耗常超50W),国产技术通过存算一体与模型优化实现突破:
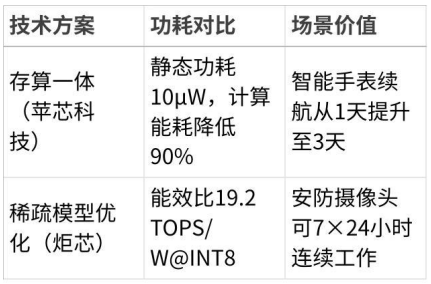
典型案例:
•苹芯科技PIMCHIP-S300:基于SRAM的存算一体设计,将数据存储与计算合二为一,减少90%的数据搬运能耗,使智能手表心率监测功耗从5mW降至0.5mW。
•炬芯MMSCIM NPU:通过算法压缩技术(如权重剪枝),在安防监控场景中实现毫瓦级运行功耗,支持4K视频流实时分析。
2.3
软硬协同:生态破壁之战
国产芯片需打破国际巨头(如英伟达CUDA)的生态垄断,通过工具链兼容与开放生态加速场景落地:

实践成效:
• 寒武纪Neuware平台:通过自动转换工具,将CUDA代码迁移至国产芯片的周期从3个月缩短至1个月,助力工业机器人算法快速迭代。
• 英特尔OpenVINO:在智能工厂场景中,通过模型压缩与量化技术,使端侧芯片算力需求降低40%,响应速度提升至毫秒级。
技术-场景-生态的三重突围:
国产AI芯片正以精准算力分配(异构架构)、超低功耗设计(存算一体)、开放工具链(生态兼容)三大能力,推动具身智能在消费电子、工业制造等场景加速渗透。随着技术成熟与生态完善,国产芯片有望在5年内实现端-边-云全栈自主化,成为全球AI竞赛的核心竞争力。
03
国产芯片的突围路径
3.1
技术路线分化
国产AI芯片技术路线呈现差异化布局:
燧原科技专注ASIC专用架构,以高能效推理芯片见长,但需应对算法快速迭代的适配压力;
苹芯科技凭借SRAM介质突破存算一体技术,在端侧低功耗场景与华为、海康威视形成产业协同;
希姆计算则押注RISC-V开源架构开发云端大算力芯片,亟待破解场景落地不足与生态兼容性难题。
三大路径分别瞄准推理加速、边缘计算与云端训练赛道,形成错位竞争的技术矩阵。
3.2
系统级适配与场景深耕
AI芯片系统级适配加速场景渗透,京深两地形成差异化突破路径:
北京依托"大小脑模型"协同框架,推动芯片与多模态算法深度适配,实现复杂模型的高效部署与资源动态调度;
深圳聚焦工业场景,通过端侧芯片与轻量化模型协同优化,将工业机器人响应速度提升40%,破解实时控制与能耗平衡难题。
二者分别从算法集成度与场景颗粒度切入,构建起"云端-边缘"联动的适配体系,为智能制造、智慧城市等垂直领域提供定制化算力底座。
04
大模型与芯片协同优化:端侧智能的黄金搭档
要让“聪明”的大模型跑在机器人、手机等端侧设备上,就像让大象在茶杯里跳舞——既要保持模型的理解能力,又要控制功耗、延迟和成本。芯片与大模型的协同优化正是破解这一难题的关键,以下是三大典型案例:
4.1
高通 × 阿加犀:端侧大模型“瘦身术”
产品:人形机器人“通天晓”
芯片:高通QCS8550处理器(手机级芯片改造)
技术亮点:
•模型压缩:将百亿参数的大模型(LLM)压缩至端侧可运行版本,内存占用降低80%,功耗控制在5W以内(相当于手机玩游戏时的耗电)。
•多模态融合:通过芯片内置的AI引擎,同时处理摄像头画面(视觉)、麦克风指令(语音)和关节传感器数据(动作),实现“听懂指令→规划动作→执行操作”全流程端侧完成,响应延迟<200毫秒(比云端传输快10倍)。
场景价值:
在汽车工厂中,“通天晓”能根据工人语音指令(如“把零件运到A区”),自主避障导航、搬运物料,单机成本仅3万元(传统工业机器人方案的1/5)。
4.2
英特尔“大小脑融合”:算力灵活拼装
方案:CPU(小脑)+ GPU(大脑皮层)+ NPU(脑干)三合一架构
落地产品:人形机器人“领航者2号”
协同逻辑:
•CPU(运动控制“小脑”):负责关节电机控制、平衡调节等实时任务,延迟<1毫秒。
•GPU(大模型“大脑皮层”):运行20B参数模型,解析复杂指令(如“检查流水线第三工位的螺丝是否松动”)。
•NPU(感知“脑干”):处理摄像头/雷达数据,实时构建环境3D地图,功耗仅2W。
效果对比:
传统方案(纯CPU+云端模型)
•成本:15万元/台
•功耗:60W
•任务响应:2秒
英特尔方案
•成本:8万元/台
•功耗:25W
•任务响应:0.3秒
4.3
面壁智能 × 加速进化:
小模型也有大智慧
突破点:全球首个端侧多模态大模型机器人
硬件配置:
•芯片:定制NPU(峰值算力16 TOPS)
•模型:MiniCPM-V 2.6(8B参数,手机可运行)
技术魔法:
•视频理解“快进键”:模型通过芯片硬件加速,能实时解析摄像头画面(如识别“桌上的水杯还剩半杯水”),处理速度达120帧/秒(接近人眼视觉)。
•记忆瘦身术:将模型运行时内存占用压缩到6GB(相当于同时打开3个微信+1个王者荣耀),可在机器人本地存储千条操作指令。
实测表现:
•听到“帮我拿药”指令后,3秒内完成:
a.识别药瓶位置(视觉)
b.规划抓取路径(决策)
c.控制机械臂精准抓取(执行)
•全程无需联网,功耗相当于一个LED台灯(15W)。
4.4
为什么这很重要?
传统AI机器人需要把数据传到云端处理,就像每次思考都要打电话问专家:
•费钱:云端算力成本每小时超10元
•费时:网络延迟导致反应慢(如摔倒后要2秒才能调整姿势)
•危险:断网时立刻“变傻”
通过芯片与大模型协同优化,相当于给机器人装上了“本地大脑”:
•成本从特斯拉汽车级别降到五菱宏光级别
•反应速度从树懒(秒级)提升到猎豹(毫秒级)
•应用场景从工厂扩展到家庭、医院、灾难救援
05
未来展望:从“算力追随”到“生态主导”
国产AI芯片正从“算力追随”迈向“生态主导”,需以技术创新、生态重构、政策协同三轨并进。
技术上,依托存算一体、Chiplet封装及硅光子技术突破算力瓶颈;
生态上,华为昇腾以软硬开源构建自主体系,海光信息借兼容CUDA/X86推动生态迁移;
政策上,京深产业集群加速“芯片-算法-场景”闭环,目标2030年全栈国产化。
未来,随着RISC-V架构适配与国产Chiplet标准突破,中国将形成覆盖设计、封装、框架的完整生态,实现从技术突围到生态主导的跨越。

推荐阅读





×
右键可直接复制图片