
 阅读时间大约5分钟(1888字)
阅读时间大约5分钟(1888字)
2025-05-14 我们离真正的具身智能大模型还有多远?
来源:文心一言
具身智能基础模型呈现出一定的智能涌现,才有可能实现真正的端到端具身智能大模型。
作者:李鑫 出品:具身智能大讲堂
今年2月Figure AI发布Helix VLA大模型引发行业深度关注,我们不由得思考一个问题,我们离真正的具身智能大模型还有多远?
1► 具身智能大模型(VLA)的基本概念
具身智能大模型,即Vision-Language-Action(VLA)大模型,是一种能够让机器人通过理解环境和语言指令,并通过执行模块输出为动作的先进技术。这种模型的核心在于其集成了视觉、语言理解和动作执行的能力,使得机器人能够像人一样,在接收到指令后,理解环境,做出决策,并执行相应的动作。
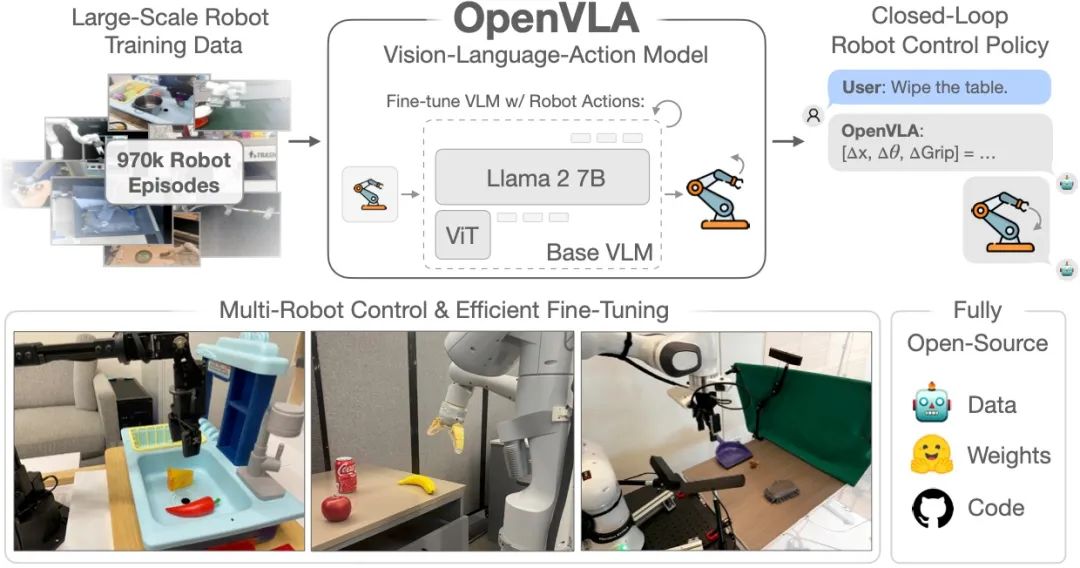
VLA大模型的出现,标志着机器人技术从简单的自动化操作向更高级的智能化操作迈进。传统的机器人往往只能执行预设的、固定的任务,而VLA大模型则赋予了机器人更多的灵活性和自主性,使其能够在复杂多变的环境中做出合理的决策。
2► VLA大模型的分层与端到端模式
在VLA大模型的发展过程中,业界形成了两种主要的技术路径:分层模式和端到端模式。
(一)分层模式
分层模式将VLA大模型的执行过程分为三个独立的步骤:接收并理解语音和图像输入、根据接收的信息做推理决策、根据决策生成动作指令并控制机器人运动。这三个步骤分别由不同的模型完成,形成了一个相对独立但相互协作的系统。
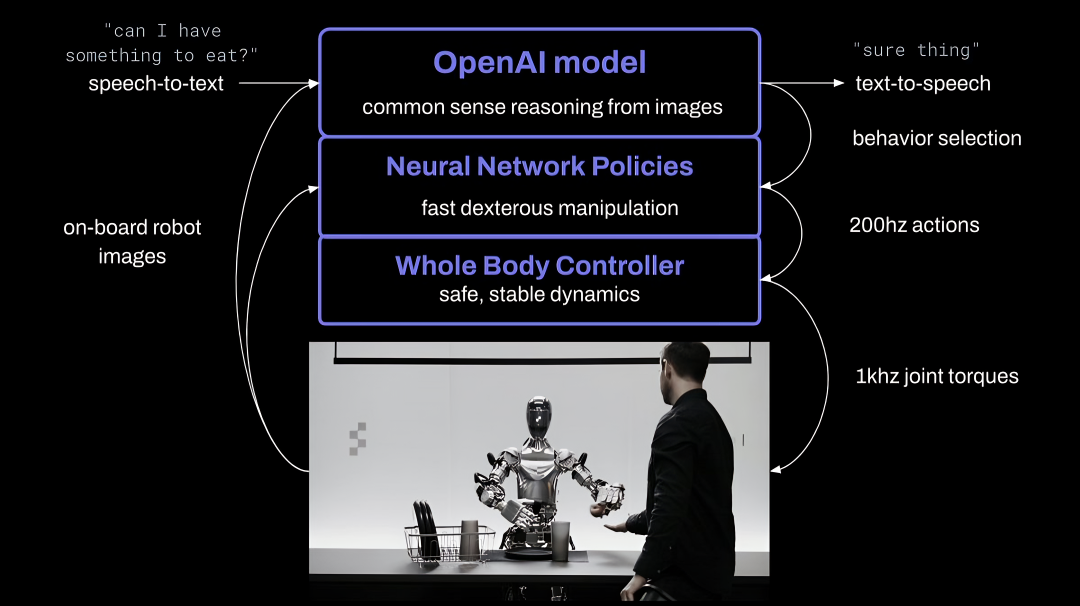
分层模式的优点在于其结构清晰,每个模型可以独立地进行优化和升级,从而提高了系统的可扩展性和可维护性。然而,这种模式的缺点也显而易见,即不同模型之间的接口和数据传递可能会成为系统的瓶颈,导致整体性能的提升受到限制。
(二)端到端模式
与分层模式不同,端到端模式将VLA大模型的执行过程集成在一个单一的模型中。这个模型能够同时处理语音和图像输入、进行推理决策,并生成动作指令控制机器人运动。
端到端模式的优点在于其反应速度快、易于实现智能涌现,并且能够通过规模化训练来降低系统的整体成本。然而,这种模式的实现难度较高,需要大量的训练数据和复杂的算法支持。此外,由于目前机器人实际单一场景的训练数据量有限,且数据获取难度极高,因此端到端模式在短期内难以实现商业化落地。
3► 训练端到端大模型的难点
尽管端到端模式优势明显,但目前训练出好用的端到端大模型仍面临很多挑战。
(一)数据量差距巨大
相较于VLM大模型亿条级别的数据量,目前机器人实际单一场景的训练数据量仅仅在千条和万条级别,差距百倍。这种数据量的不足,严重限制了机器人模型的学习能力和泛化能力。
(二)数据获取难度极高
机器人训练数据的获取难度远高于互联网上的语料数据。目前,主要有三种数据获取模式:真实数据遥操采集、虚拟生成数据和真人数据映射。然而,这三种模式都存在各自的局限性。
真实数据遥操采集:目前动捕设备一套价格在几十万区间,初创企业如果要靠动捕设备遥操采集数据,成本非常高。

虚拟生成数据:虽然可以通过虚拟仿真技术生成数据用于机器人训练,但目前难以解决sim-to-real gap问题。即虚拟仿真数据训练出的机器人在实际环境中表现不佳,特别是在涉及柔性物体的场景中。

真人数据映射:UMI 和 DexCap(斯坦福机器人团队)等正在探索真人数据映射(即采集真实人的数据,通过某种映射关系转化为机器人数据),但目前还处于早期阶段,技术尚不成熟。此外,真人数据映射也面临着数据毒性和泛化性不足的问题。
(三)机器人本体方案未收敛导致数据难以复用
由于目前市场上存在多种不同的机器人本体方案,不同方案之间的数据难以复用。例如,用特斯拉本体采集的数据很难给智元的机器人来训练,因为本体方案不同。这种数据不通用性,进一步加剧了机器人训练数据的稀缺性。
4► 目前产业界的解决方案
面对上述难点,产业内的头部企业正在积极探索解决方案,以希望在未来实现真正的端到端具身智能大模型。
(一)努力收集数据,实现单一场景下的泛化
目前,各家企业都在自己的方案上努力收集数据,试图在单一场景下实现一定程度的泛化。通过不断积累和优化数据,逐步提高机器人模型的学习能力和适应能力。

这种策略虽然短期内难以实现端到端大模型的全面落地,但可以为未来的技术突破奠定坚实的基础。
(二)预训练+后训练(强化学习)的模式
Deepseek范式通过预训练+后训练(强化学习)的模式,并导入高质量数据,来降低大模型的算力和数据量需求。虽然目前这种范式对具身智能大模型来说基本要素还不具备,但学界和工业界都在积极探索这一方向。通过模仿学习达成0-1的突破,再通过强化学习实现1-10的提升,逐步逼近真正的端到端具身智能大模型。
(三)Figure Helix大模型的启示
Figure发布的Helix大模型采用了一种准分层架构,结合开源的VLM大模型和Transformer架构的动作策略快系统,实现任务的执行能力。
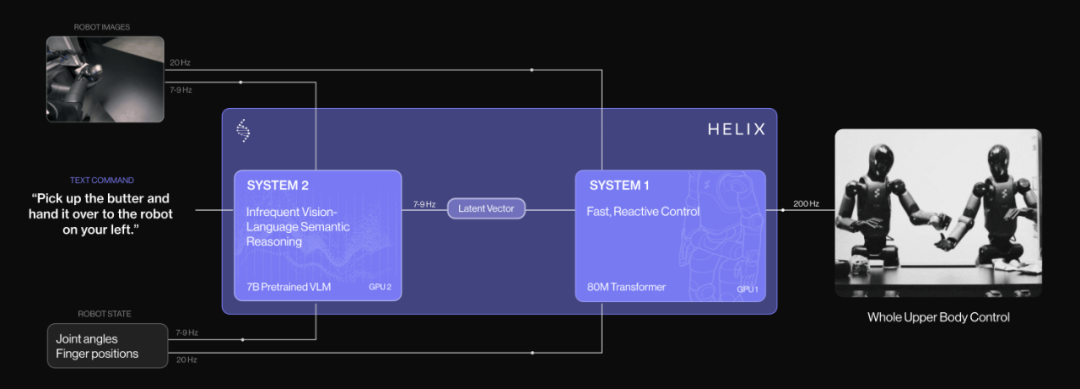
虽然Helix还存在一些局限性,如纯模仿学习、无法处理突发情况等,但其成功之处在于能够快速适应市场需求,并在数据量有限的情况下达到较好的泛化水平。这为未来的具身智能大模型发展提供了一定的启发。
5► 结语与未来:
目前产业内普遍认为,我们离真正的具身智能大模型还有一定的距离。但随着技术的不断进步和数据的不断积累,这一距离正在逐步缩小。未来3-5年后,当市场上有足够多的人形机器人数据,并且硬件方案逐步收敛,具身智能基础模型呈现出一定的智能涌现,才有可能实现真正的端到端具身智能大模型。

推荐阅读


×
右键可直接复制图片