
 阅读时间大约10分钟以上(5778字)
阅读时间大约10分钟以上(5778字)
2025-06-27 谷歌RT-1模型—— 具身智能VLA模型在早期的重要探索
来源:豆包
高效的多任务机器人学习需要的高容量模型。
作者:陈康成 出品:机器觉醒时代
2022 年 10 月,谷歌 DeepMind 发布 RT-1 模型,其训练数据源自 13 台机器人持续 17 个月采集的超 13 万条任务片段。该研究开创性地将Transformer的应用向前推进 —— 将语言和视觉观测到机器人动作的映射视为一个序列建模问题,并利用Transformer学习这一映射。
能否借助多样化的机器人任务数据,训练出统一且强大的多任务骨干模型,使其具备对新任务、操作环境及物体的零样本泛化能力?这一目标面临两大核心挑战:数据集构建与模型设计。谷歌RT-1模型正是针对该命题的突破性探索。在RT-1模型的研究探索中,谷歌DeepMind 研究人员发现:
数据模型要实现优质泛化,必须构建兼具规模与广度的数据集,覆盖多样化任务与场景。同时,数据集中的任务需具备强关联性以支撑泛化,使模型能够发现结构相似任务间的内在规律,并通过创新性组合完成新任务。
模型架构设计的挑战在于——高效的多任务机器人学习需要的高容量模型。
一、RT-1工作原理
RT-1执行闭环控制,并以3Hz的频率持续输出动作指令,直至触发"终止"动作或达到预设时间步上限。
首先通过ImageNet预训练的卷积网络EfficientNet处理图像,该网络通过FiLM模块与指令的预训练嵌入向量进行条件调节;随后采用令牌学习器(tokenLearner)生成紧凑令牌集( set of tokens);最终由Transformer对这些令牌执行注意力计算,输出离散化动作令牌(action token)。

RT-1工作流程图
RT-1架构包含以下核心内容:

RT-1架构图
1)EfficientNet网络
RT-1通过将6 幅图像的历史记录输入一个基于ImageNet 预训练的 EfficientNet-B3模型来对其进行令牌化。
该模型接收分辨率为 300×300 的6幅图像作为输入,并从最终的卷积层输出一个形状为 9×9×512 的空间特征图。
为了包含语言指令,研究人员使用预训练的语言嵌入形式,让图像令牌化器以自然语言指令为条件,从而能够在早期提取任务相关的图像特征,并提升 RT-1 的性能。
EfficientNet是一种卷积神经网络(CNN),是高效的 “图像特征提取器”。它好比是提取画面特征的“图像翻译官”,专门用来从图像中提取特征,用于识别物体、分析场景等。
类似人类看照片时自动识别 “物体轮廓”,该卷积网络提前在 ImageNet(大规模图像数据集)上学过识别猫、车、杯子等物体,能从摄像头画面中快速提取所要识别物体的关键特征。
2)FiLM 模块
指令首先通过通用句子编码器(USE)进行嵌入。然后,将该嵌入用作输入,输入到恒等初始化的 FiLM层,这些 FiLM 层被添加到预训练的 EfficientNet 中,以调节图像编码器。
FiLM 模块好比是指令与图像的 “融合滤镜”。指令(比如 “把杯子拿到桌子上”)会先被转换成机器能懂的 “数字密码”(预训练嵌入向量)。FiLM 模块就像一个调节旋钮,用这个 “密码” 去调整图像特征:如果指令是 “拿杯子”,FiLM 会让卷积网络提取的特征更关注 “杯子的位置和把手”,忽略背景中的沙发。
3)TokenLearner(令牌学习器)
加入 TokenLearner后,将从预训练的 FiLM-EfficientNet层输出的 81个视觉令牌二次采样到仅剩8个最终令牌,然后这些令牌被传递到Transformer 层。
TokenLearner可类比成是特征的 “智能摘要工具”。卷积网络处理后的图像特征可能包含数万维数据(比如一张图拆成 1000 个小区域的特征),直接处理像 “读一本厚书”,效率很低。令牌学习器会自动挑选最重要的特征,把海量数据 “压缩” 成几十个关键 “令牌”(Token),类似从书中提取 “杯子、桌子、位置” 等关键词,扔掉无关细节(比如杯子上的花纹)。这样一来,数据量大幅减少,后续模型处理速度就像 “从读整本书变成看目录”,效率飙升。
4)Transformer
每幅图像产生的这8个令牌随后会与历史记录中的其他图像令牌拼接,形成总共 48 个令牌(并添加了位置编码),输入到 RT-1 的 Transformer 骨干网络中。该Transformer 是一个19M参数的,且仅包含解码器的序列模型,具有8个自注意力层,其输出是动作令牌。
Transformer可以看成是基于“关键词”的注意力决策者。Transformer 就像一个经验丰富的 “规划师”,它会分析压缩后的令牌(图像关键词)和指令密码,并最终输出机器人的动作执行指令。
5)其它
a. 动作令牌化(Action Tokenization)——为了对动作进行令牌化,RT-1中的每个动作维度都被离散化为256个bins。
动作维度包括:机械臂运动的七个变量(x, y, z, roll, pitch, yaw, 夹爪开合度)、底盘运动的三个变量(x, y, yaw)以及一个用于在三种模式(控制机械臂、控制底盘和终止任务片段)间切换的离散变量。
对于每个变量,研究人员将目标值映射到这256个bins中的一个,这些bins在每个变量的取值范围内均匀分布。
b. 损失函数—— 研究人员使用了标准的分类交叉熵目标函数和因果掩码。
c. 推理速度——一个需要在真实机器人上实时运行的模型的独特要求之一是快速且稳定的推理速度。
本工作中,人类执行指令的操作速度实测在2至4秒区间,研究人员希望模型的推理速度不应显著慢于此速度。根据实验,机器人至少需要3Hz的控制频率;并且在考虑系统其他延迟的情况下,模型本身的推理时间预算必须小于 100 毫秒。
研究人员采用了两种技术来加速推理:
通过使用TokenLearner,减少由预训练 EfficientNet 模型生成的令牌数量;
仅计算这些令牌一次,并在后续存在重叠的推理窗口中复用它们。
这两项技术将模型推理速度分别提升了2.4倍和1.7倍。
二、RT-1研究实验设置
1. 实验用机器人:Everyday Robots机器人 ,配置有7个自由度的机械臂、一个两指夹持器和一个移动底座。
2. 评估环境:2个真实办公室厨房环境 + 1个基于真实厨房模拟搭建的仿真虚拟环境。
3. 基线模型选择:Gato、BC-Z 和BC-Z XL。

备注:为了能在真实机器人上以足够高的频率运行 Gato,研究人员将原本接近12亿参数规模的Gato限制到3700万参数。(与RT-1的3500万参数相近)
除了原始 BC-Z 模型外,实验中还选取了一个参数量与 RT-1相近的、更大版本的 BC-Z XL作为基线模型。
4. 评估内容:研究人员通过3000 余次真实场景试验进行评估,以实验成功率衡量 RT-1模型在已训练指令上的执行性能、对未见指令/新任务的泛化能力、在含背景/干扰物场景中的鲁棒性以及在长时程任务中的表现。

1)已见任务性能—— 为评估模型在处理已见指令上的性能,评估了从训练集中采样的指令上的表现。然而,此评估仍涉及物体摆放位置以及设置的其他因素(例如一天中的时间、机器人位置)的变化,要求技能能够泛化到环境中现实存在的可变性。
在此评估中,总共测试了超过200 个任务:36 个抓取物体任务、35 个推倒物体任务、35 个竖直放置物体任务、48 个移动物体任务、18 个开关各种抽屉任务,以及 36 个从抽屉中取出物体和将物体放入抽屉的任务。
2)未见任务泛化性—— 为评估模型对未见任务的泛化能力,测试了21条未见的指令。
这些指令分布在不同的技能和物体上,确保了每个物体和每种技能在训练集中至少出现过一些实例,但它们将以新颖的方式组合。例如,如果“拿起苹果”这条指令被留出,那么训练集中仍存在其他包含苹果的指令。
3)鲁棒性—— 为评估鲁棒性,研究人员执行了30个真实世界任务以测试干扰物鲁棒性以及22个任务以测试背景鲁棒性。
背景鲁棒性通过在新的厨房(具有不同的照明和背景视觉效果)以及使用不同的台面(例如带图案的桌布)中进行评估测试。

鲁棒性评估场景的示例配置
干扰物鲁棒性评估场景(首行),从左至右:简单场景(0-5个干扰物)→中等场景(9个干扰物)→困难场景(9个干扰物+被遮挡物体);
背景鲁棒性测试场景(次行),从左至右:原始环境→带图案桌布→新厨房环境。
真实厨房中的现实场景(第三行),泛化级别从左至右:L1级→L2级→L3级;
备注:L1——指泛化到新的台面布局和照明条件;L2——在 L1 基础上,额外泛化到未见过的干扰物物体;L3——在 L2 基础上,额外泛化到全新的任务设置、新的任务物体或位于未见位置(如水槽附近)的物体。
4)长时程场景—— 这些场景每个都需要执行一系列技能序列。评估的目标是结合多个泛化维度,例如新任务、新物体、新环境,并在现实环境中测试模型的整体泛化能力。
这些评估包含在两个真实厨房中执行的15条长时程指令,每条指令需要执行包含大约10个独立步骤的技能序列,其中每个步骤的复杂度与训练指令大致相当。这些步骤是通过 SayCan 系统从高层级指令自动分解得到,例如“你会如何扔掉桌子上的所有物品?”
三、RT-1关键问题探索
1. 关键问题汇总
1)RT-1 能否学会执行大量指令,并能否以零样本方式泛化到新任务、新物体和新环境?
2)能否通过整合异构数据源(例如模拟数据或来自不同机器人的数据)来进一步突破RT-1模型的性能极限?
3)RT-1在长时程机器人场景中的泛化表现如何?
4)RT-1泛化指标如何随数据量和数据多样性的变化而变化?
5)RT-1模型设计中有哪些重要且实用的决策,它们如何影响性能和泛化?
2. 关键问题逐个验证
1)RT-1 能否学会执行大量指令,并能否以零样本方式泛化到新任务、新物体和新环境?
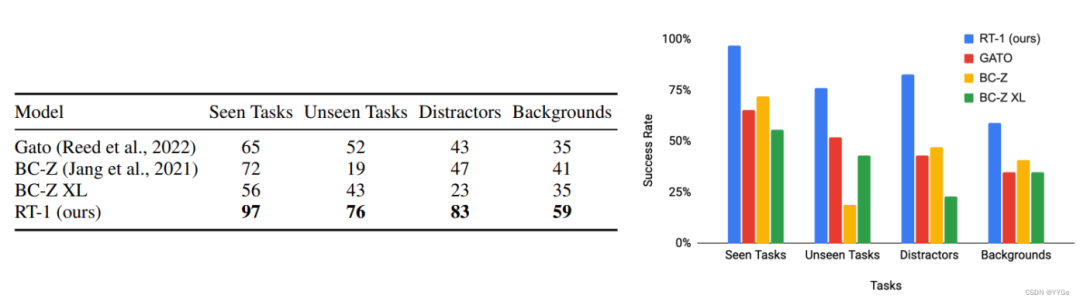
结果上表所示:在每个评估类别中, RT-1 的性能均显著优于之前的模型。
在已见任务上,RT-1 能够成功执行超过 200 条指令中的 97%,比BC-Z高出25%,比Gato高出32%。
在未见任务上,RT-1 展现了对新指令的泛化能力,成功执行了 76% 的从未见过的指令,比次优基线模型高出 24% 。
在干扰物和背景鲁棒性方面,RT-1成功执行了 83% 的干扰物鲁棒性任务和59% 的背景鲁棒性任务,分别比次优基线模型高出 36% 和18%。
总体而言,RT-1 具有很高的综合性能,同时展现出较强泛化能力和鲁棒性。
对现实指令的泛化
办公室厨房环境与训练环境存在显著偏移。根据泛化程度的不同,对这些场景中的任务进行了L1级至L3级的三级分类。最终实验结果显示:
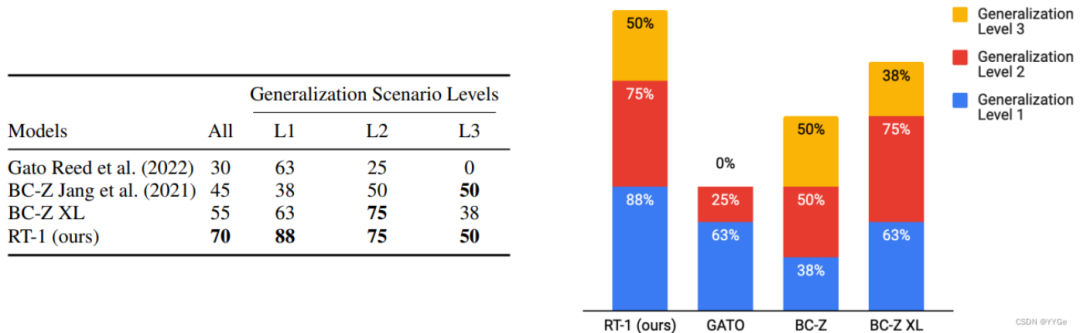
RT-1在L1-L3级别上的泛化性都是最佳的。
Gato在L1级别泛化尚可,但在更困难的泛化场景(L2, L3)中性能显著下降。
BC-ZXL版本在 L2 级别表现较好,在L3级别优于Gato,但仍不及 RT-1。
BC-Z在L3基本的泛化能力与RT1相当,但是在L1与L2级别表现相对较差。
2)能否通过整合异构数据源(例如模拟数据或来自不同机器人的数据)来进一步突破RT-1模型的性能极限?
a. 引入模拟数据
该组实验使用了所有的真实演示数据,但也包括提供了额外的模拟数据,其中包含机器人从未在真实世界中见过的物体。具体来说,指定了不同的泛化场景:
具有真实物体的已见技能:训练数据包含该指令的真实数据;
具有模拟物体的已见技能:训练数据包含该指令的模拟数据;
具有模拟物体的未见技能:训练数据包含该物体的模拟数据,但无论在模拟还是真实环境中,都没有描述使用该物体执行该技能的指令示例(例如,“将模拟物体移动到苹果附近”,即使机器人只在模拟中练习过拿起该模拟物体,而从未练习过将其移动到其他物体附近)。

实验结果表明:对于RT-1 来说,与仅使用真实数据相比,加入模拟数据不会损失性能,在一定的情况下,反而有助于性能的提升。
具有真实物体的已见技能:加入模拟数据后,性能从92%降至90%,影响很小。
具有模拟物体的已见技能:加入模拟数据后,性能有显著提升,从23%提升至87%。
具有模拟物体的未见技能:加入模拟数据后,性能有显著提升,从7%提升至33%。
b. 引入不同形态机器人的数据
除了RT-1数据集之外,引入Kuka数据集。Kuka数据包含在 QT-Opt 中收集的所有成功样本,对应于 209,000 个任务片段。其中,机器人无差别地抓取箱中的物体。
为了测试RT-1是否能有效吸收这两种截然不同的数据集,评估了模型在“Classroom eval”任务上和“Bin-picking eval”任务上的性能。
两个数据集之间的主要差异:
收集数据的机器人在外观和动作空间上不同,而且它们部署的环境在外观和动力学特性上也不同。
此外,QT-Opt 数据呈现出完全不同的动作分布——它是由一个强化学习(RL)智能体收集的,这与RT-1数据集中存在的人类演示截然不同。
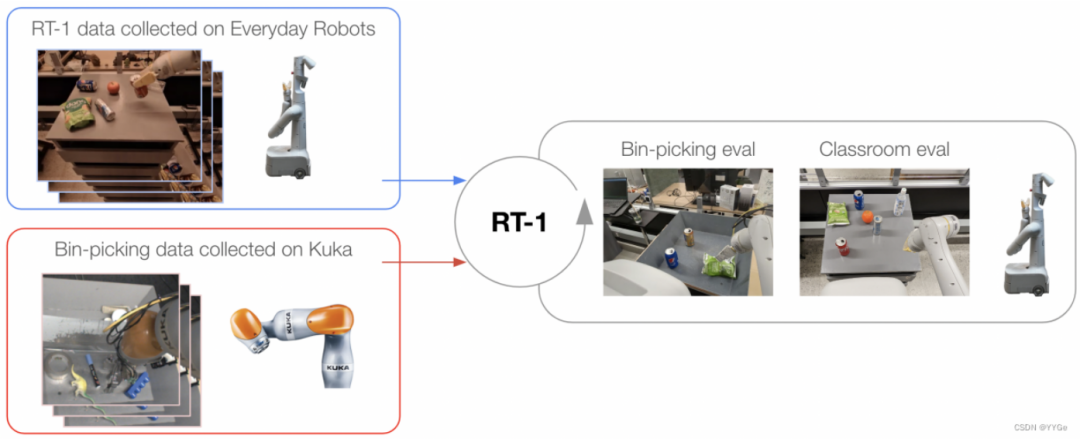
RT-1 使用来自两个机器人平台的数据进行训练

实验结果显示:
在RT-1 中加入来自 QT-Opt 的Kuka 数据,对“Classroom eval”任务的性能影响极小,但在“Bin-picking eval”任务上的泛化能力提升了近 2 倍。
在“Classroom eval”任务上,基于混合数据训练的模型,相比仅依靠RT-1数据训练的模型,在成功率上有2%的下降。
在“Bin-picking eval”任务上,基于混合数据训练的模型的成功率为39%,而仅使用 RT-1 数据训练的模型成功率为22%。
仅使用Kuka数据训练的RT-1在 Everyday Robots(EDR)机器人上执行“Bin-picking eval”任务的成功率为 0,这也从一定程度上证明了将技能从另一种机器人形态迁移过来是困难的。
RT-1 可以通过观察其他机器人的经验来获取新技能,这给研究者们提供了一个有价值的研究方向:结合更多机器人数据集来增强机器人的能力。
3)RT-1在长时程机器人场景中的泛化表现如何?
在两个不同的真实厨房环境中(Kitchen1和Kitchen2)执行RT-1和基线模型。相比Kitchen1 ,Kitchen2是一个更具挑战性的泛化场景。评估分为规划成功率和执行成功率两项内容。
实验结果显示:
1)在Kitchen1场景中,除原始 SayCan外,所有模型的规划成功率均为87%;而执行成功率,RT-1表现最佳,达到67%。
1)在Kitchen2场景中,除原始 SayCan外,所有模型的规划成功率均为87%;而执行成功率方面,使用Gato无法完成任何长时程任务, BC-Z能够达到13%的成功率,RT-1依然可以达到67%的成功率。
综合来看,RT-1从 Kitchen1 到 Kitchen2,其操作性能并未出现明显下降情况。
备注:在Kitchen1场景中,由于SayCan 评估使用的提示词略有不同,因此其规划成功率较低。
4)RT-1泛化指标如何随数据量和数据多样性的变化而变化?
该实验对比RT-1在缩减数据集规模(数据百分比)与数据集多样性(任务百分比)时的性能、泛化能力及鲁棒性变化。
等比例缩减数据集:通过裁剪数据量最大任务的数据,构建任务多样性相同但规模更小的数据集,限制每任务样本上限为200例(保留51%数据)、100例(37%数据)、50例(22.5%数据)。
窄化数据集:移除数据量最少的任务,保留97%总数据但仅75%任务。
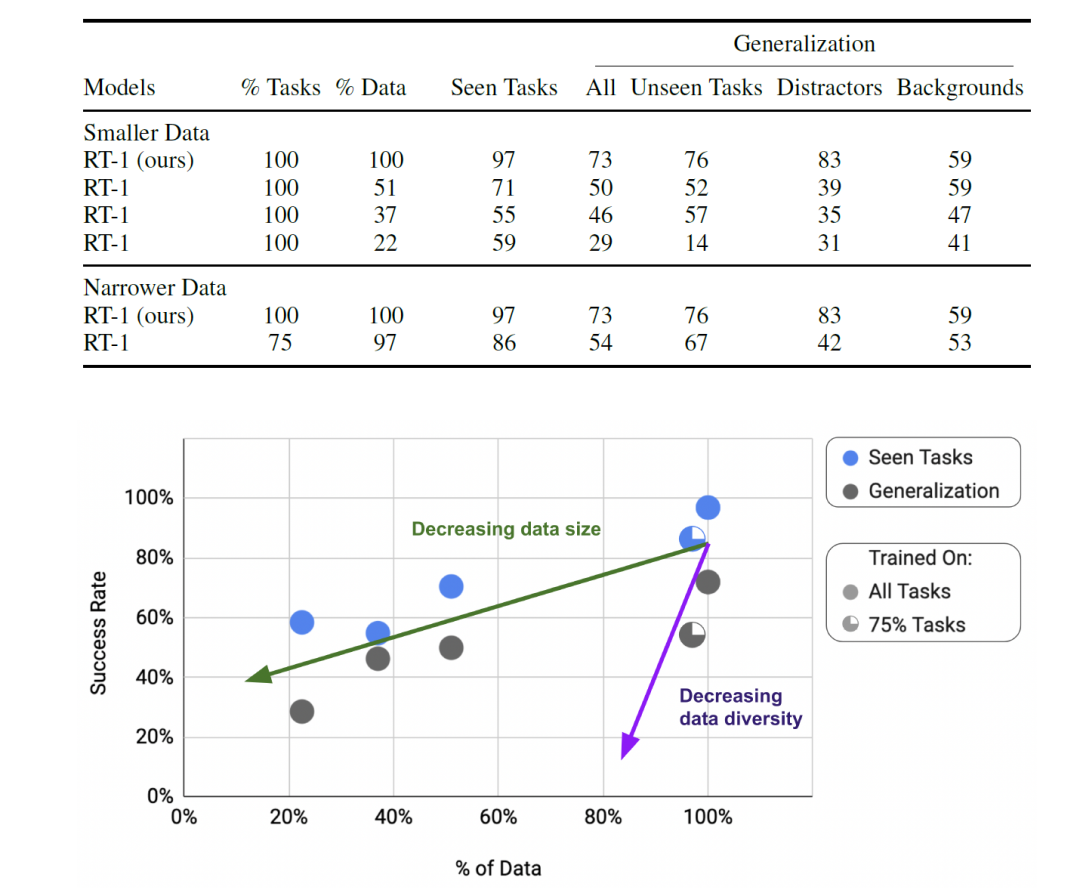
RT-1在已知任务、未见任务泛化、干扰物与背景鲁棒性上的数据消融实验结果
实验结果显示:数据多样性对性能与泛化能力的影响高于数据量。
数据集缩减结果:模型性能呈普遍下降趋势,泛化能力下降更为显著;
数据集窄化结果:模型性能急剧下降,泛化能力衰退尤为剧烈。事实上,在保留97%数据情况下移除25%任务,其泛化性能降幅相当于直接减少49%数据量。
核心结论:数据多样性比数据量更为关键。
5)RT-1模型设计中有哪些重要且实用的决策,它们如何影响性能和泛化?
为解析RT-1模型的性能增益来源,研究人员针对其核心设计展开系统性消融研究,验证以下假设:
a.模型容量与表达能力:通过调整模型规模(如参数量)及架构变更(如移除Transformer模块)验证;
b.动作表示的有效性:通过切换为连续动作空间(正态分布假设)及取消自回归动作条件机制验证其对多模态动作分布的建模能力;
c.ImageNet预训练初始化的必要性:对比随机初始化权重验证预训练价值;
d.历史观测信息的作用:通过截断历史帧序列验证时序建模收益。
每组实验从四个关键维度(已见任务性能、未见任务泛化能力、推理速度、干扰物/背景鲁棒性)进行量化对比。
实验结果表明:
在保持ImageNet预训练的同时减小模型规模,由此导致的性能在训练任务和泛化任务上均有所下降,但下降幅度不如其他消融实验大;
移除Transformer组件则对已见任务、未见任务和抗干扰物能力产生了一致但较小的负面影响;
用更标准的连续高斯分布替换了模型中按维度离散化的动作表示后,导致了性能的显著下降;
使用的动作的自回归条件建模,并未带来性能提升,并且使推理速度减慢了一倍以上;
ImageNet预训练对于模型的泛化性和鲁棒性尤为重要,由于ImageNet数据集庞大且视觉多样性丰富,移除它会使未见任务的性能下降33%;
移除历史观测主要影响对干扰物的泛化能力。
四、局限性与未来展望
1.局限性
尽管RT-1 在多项关键指标上表现突出:以 97% 成功率执行超 700 条指令,在新任务、物体与环境的泛化能力上超越已发布基线模型;能有效融合模拟环境与异构机器人形态的数据,且在不削弱原任务性能的前提下增强新场景适应性;还可在SayCan框架中完成长达50步的长时程任务 —— 但该模型仍存在一定局限性。
RT-1 的训练数据虽覆盖大规模操作任务,但主要针对灵巧度要求不高的操作场景;
RT-1是一种模仿学习方法,继承了该类方法固有的挑战,例如,可能无法超越演示者的性能水平。
RT-1对新指令的泛化仅限于先前见过的概念组合,尚无法泛化到前所未见的全新动作。
2. 未来展望
谷歌DeepMind计划继续扩展 RT-1能够支持并泛化到的指令集。另外,希望通过开发允许非专家通过定向数据收集和模型提示来训练机器人的方法,从而更快地扩展机器人技能的数量。
虽然当前版本的RT-1对干扰物物体已经相当鲁棒,但其对背景和环境的鲁棒性可以通过大幅增加环境多样性来进一步改善。另外,他们还希望通过可扩展的注意力机制和记忆模块来提高RT-1 的反应速度和上下文保持能力。

推荐阅读





×
右键可直接复制图片