
 阅读时间大约7分钟(2417字)
阅读时间大约7分钟(2417字)
2025-09-19 为什么VLA能叠毛巾,却插不进一个插头?解读具身智能的重大补全
来源:深蓝具身智能
为什么VLA能叠毛巾,却插不进一个插头?
出品:深蓝具身智能

上述动图,来自今天要介绍的这项工作的视频演示。
TA-VLA按下插座按钮,将充电器插入插座,最后再拔下插座上的充电器的密集操作任务……
有意思的是~按钮并没有完全被按下,第一次也没有精准插入,可见:
1、团队非常务实,敢于将不完美的一面展示给大家看(小编开玩笑~);
2、可见TA-VLA模型在精细控制上,还有改进空间。
言归正传:众所周知,机器人接触密集型操作(例如按下插座的钮按,然后将充电器插入插座以及拔下插座上的充电器等),都需依赖扭矩等力信号反馈来判断任务状态并实现闭环控制。
但,现有的VLA模型(例如RDT、等)都没有整合此类物理反馈数据。
这导致了一个鲜明的能力反差:它们虽能依靠视觉规划完成“叠毛巾”等几何任务,却难以执行“插插头”这类需要精细力控的操作。
其根本原因在于,仅凭RGB视觉和语言指令无法构建闭环的力感知-动作循环,而真正的物理交互恰恰依赖于这种持续的力量反馈与实时调节(比如插个插座)。
基于此背景,由BAAI智源研究院、清华大学人工智能产业研究院以及南洋理工大学合作提出的Torque-aware VLA模型(TA-VLA),通过将关节扭矩信号深度融合至VLA架构,为物理反馈与VLA的融合奠定了方法论基础。
所以,今天我们就来聊聊TA-VLA。
——具有“体感”的具身智能。
研究成果说明
接下来我们对TA-VLA的核心研究成果进行详细解读。
动作-扭矩扩散模型的设计
论文通过多组实验对比,最终得到动作-扭矩扩散模型:
(1)首先在输入数据的选择上,包含:
RGB视觉、文本指令、本体关节角度q、关节扭矩
(2)然后基于模型,视觉编码器采用PaliGemma-3B,语言编码器采用BERT-base
(3)解码器模块是TA-VLA的核心设计部分:
在解码器上融合扭矩信息,效果收益最高;
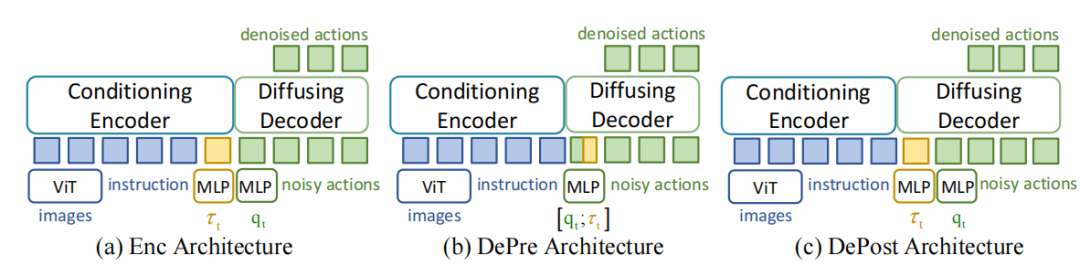
▲图1|设计了3中嵌入扭矩信号的架构来说明编码器融合扭矩最好:(a)Enc Arch:拼接图像、文本、关节扭矩,然后输入到编码器 (b)DePre Arch: 将关节扭矩和本体关节角度拼接后输入到解码器 (c)DePost Arch: 将前置动作和关节扭矩拼接后输入到解码器,(b)(c)效果都好于(a),并且(c)好于(b)©️【深蓝具身智能】编译
将整个扭矩历史整合为单一token输入到解码器中是最优的扭矩历史信息的处理方式;
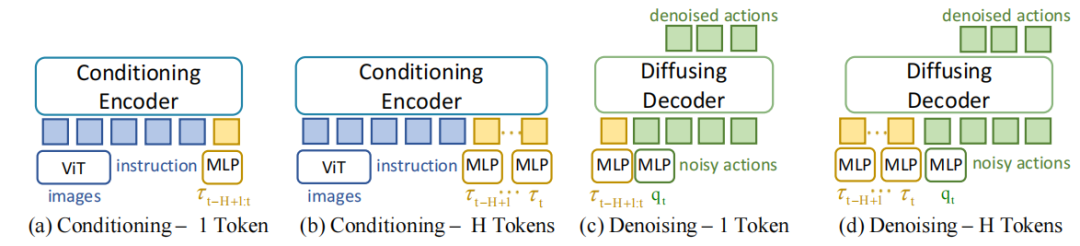
▲图2|设计了4中嵌入历史扭矩信息的架构来说明将整个扭矩历史整合为单一token输入到解码器中是最优的扭矩历史信息的处理方式:(a)和(b)都在编码器中嵌入扭矩历史信息,(a)是整合成单一token嵌入,(b)是每一帧对应一个token;(c)和(d)都在解码器中嵌入扭矩历史信息,(c)是整合成单一token嵌入,(d)是每一帧对应一个token;(c)(d)效果均好于(a)(b),且(c)效果好于(d)©️【深蓝具身智能】编译
那如何将历史扭矩整合成单一token呢?
将10帧历史扭矩数据进行扁平化处理并拼接,形成一个140维的单一token,再将该token输入到MLP中;
联合动作-扭矩扩散去噪,平衡动作生成精度与扭矩预测精度,从而最小化损失来得到最优动作和扭矩。
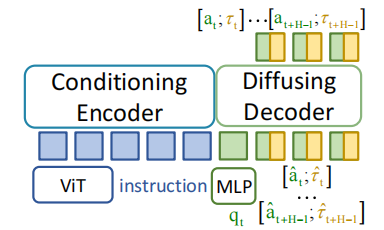
▲图3|TA-VLA的动作-扭矩扩散架构©️【深蓝具身智能】编译
具体的联合去噪步骤:
① 动作块: 未来 H 步 (如 H=10) 的关节动作序列, 维度为 H x 14 (14 对应机械臂 14 个关节的角度/速度);
② 扭矩块: 未来 H 步的关节扭矩序列, 维度为 H x 14 (与动作块的关节一一对应);
③ 联合 token: 通过 “维度拼接” 将与合并为 H x 28 的矩阵 (每一行包含对应时间步的 “动作+扭矩” 信息), 形成 “时空耦合的物理序列”。
损失计算:
通过联合优化动作精度和扭矩预测精度,, 其中,为动作去噪损失,为扭矩去噪损失,为权重因子
(4)输出数据:输出最终动作序列,用于机器人控制;同时输出预测的扭矩序列。
VLA融合扭矩信息的几个关键性发现
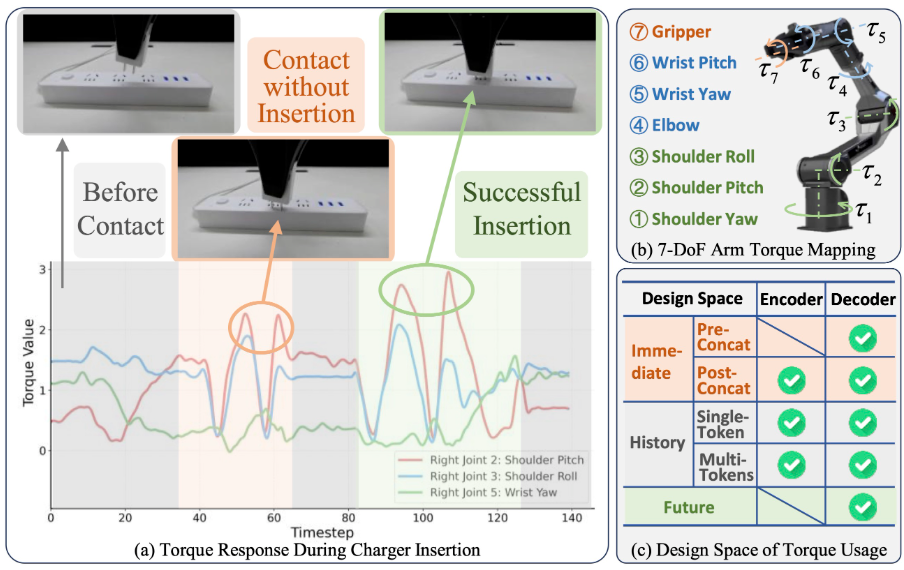
第1个发现:扭矩能否反馈外力情况,它们是存在映射关系的?
末端外力到关节扭矩是存在映射关系的,只要精确建立内部动力学模型,通过 “实测扭矩与预期扭矩的偏差”,就能在没有外部力传感器的情况下反向推断末端执行器是否接触、接触力的大小与方向等状态信息。
论文设计的动力学模型如下:

上述公式:其中是实际观测到的关节扭矩,是预期扭矩,是作用于末端执行器的外部力量, 它们可以通过雅可比矩阵的转置建立等式。
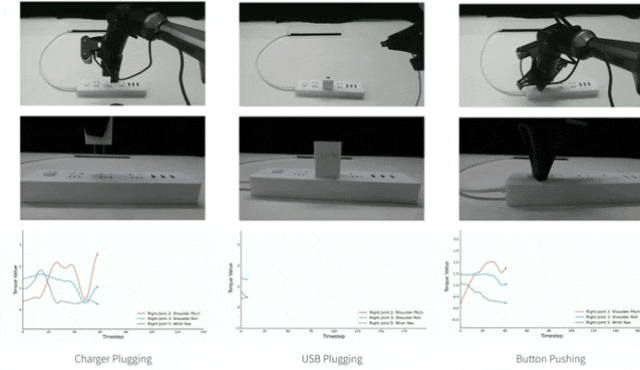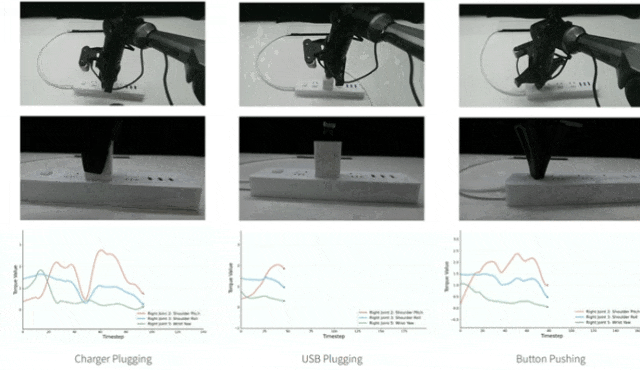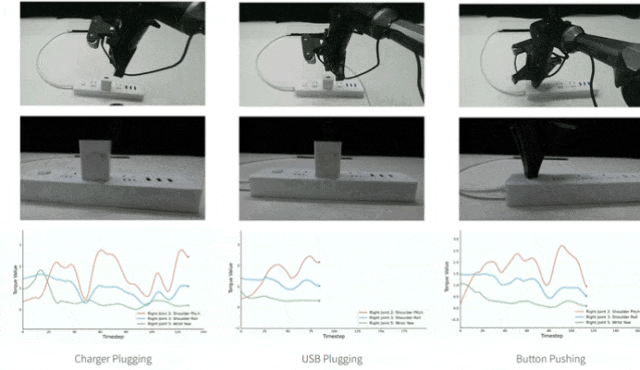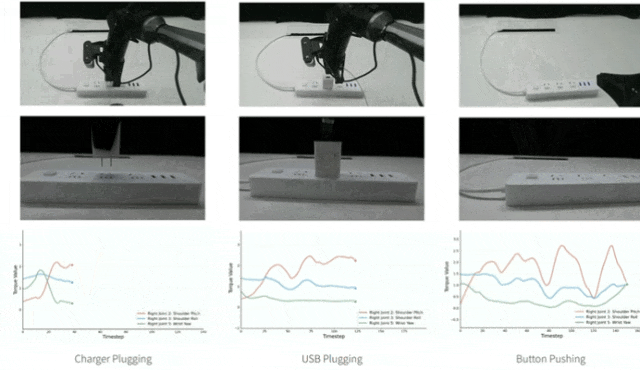
第2个发现:在解码器上融合扭矩信息比编码器上效果更好,为什么呢?
一是因为扭矩与关节角度在输入上对齐程度最高:
因此在解码器中整合可以更好的利用两者的相关性来增强本体感受。论文中通过归一化HSIC分析了几种模态之间的相关性,发现扭矩信号与关节角度的相关性显著高于其他模态 :
扭矩 vs. 关节角度:HSIC值=0.75(强相关性)
扭矩 vs. 图像/语言:HSIC值=0.25(弱相关性)
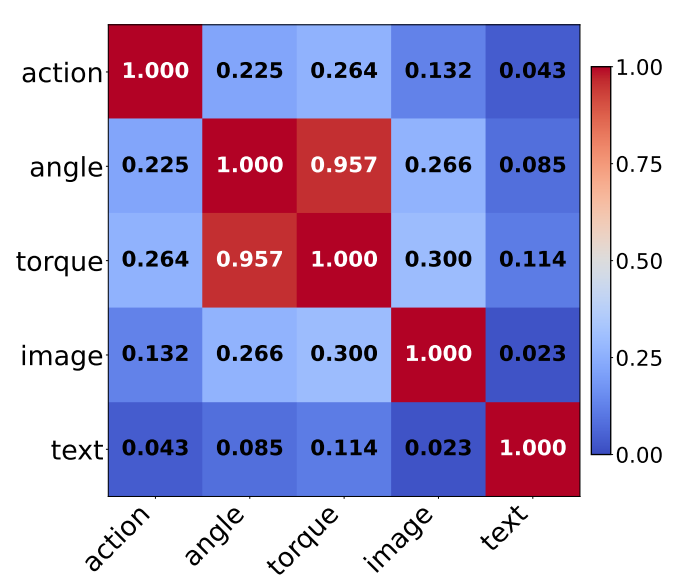
▲图4|不同模态输入token在隐藏状态上的归一化HSIC值©️【深蓝具身智能】编译
二是因为解码器敏感性更高:
原因是解码器设计目标是捕捉输入的细微变化(用于精准动作生成),而编码器则侧重于处理粗粒度的视觉-语言上下文信息。
论文中通过在编码器和解码器中加入随机噪声的方式进行实验,对解码器输入添加噪声后,Button Pushing任务成功率从5/20降至0/20,而对编码器添加噪声后仅使成功率从5/20降至 4/20,证明解码器对输入变化更敏感,能更好利用扭矩的细微变化。

▲图5|在编码器和解码器中加入随机噪声的结果©️【深蓝具身智能】编译
第3个发现:为什么说将整个扭矩历史整合为单一token输入到解码器中是最优的扭矩历史信息的处理方式?
因为解码器在预训练阶段已学习了固定的输入模式:
如果采用多token拆分(例如:历史的每一帧扭矩对应1个token)就会增加输入序列长度,从而破坏了预训练时的输入结构。因此说将整个扭矩历史信息整合到单一的token中输入到解码器中是最优的扭矩历史信息处理方式。
论文中分别在编码器上采用单一token和多token、编码器上采用单一token和多token进行实验,可以发现Button Pushing和Charger Plugging2项任务中,编码器上采用单一token的方式整合历史扭矩的效果最好,证明单一token 整合既能保留历史信息,又能维持架构稳定性。
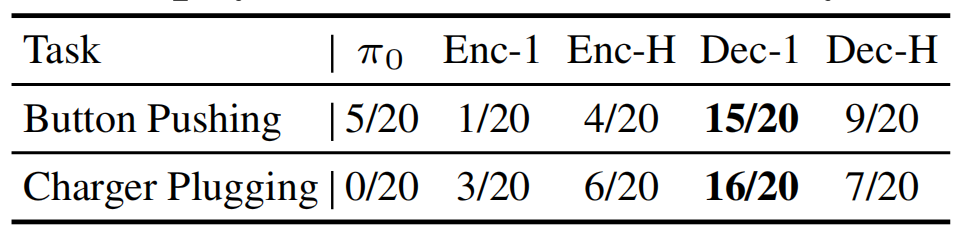
第4个发现:扭矩和动作之间是否存在因果关系,预测扭矩如何辅助任务?
从第1个发现可以知道,扭矩是能反馈外力信息的,然而外力信息和动作存在动力学关系,所以扭矩预测可以进一步干预动作的生成:
TA-VLA是基于联合动作-扭矩扩散的模型,核心是在动作生成的同时预测未来扭矩,它的目标是平衡动作生成精度与扭矩预测精度,从而最小化损失来得到最优动作和扭矩:
, 其中,为动作去噪损失,为扭矩去噪损失,为权重因子。
核心实验结果
文章设计的实验环节如表格所示:
接触密集型任务

常规任务

Cross Embodiment

在5项高频接触任务和5项常规任务中,每项任务均评估了20次试验的成功率。
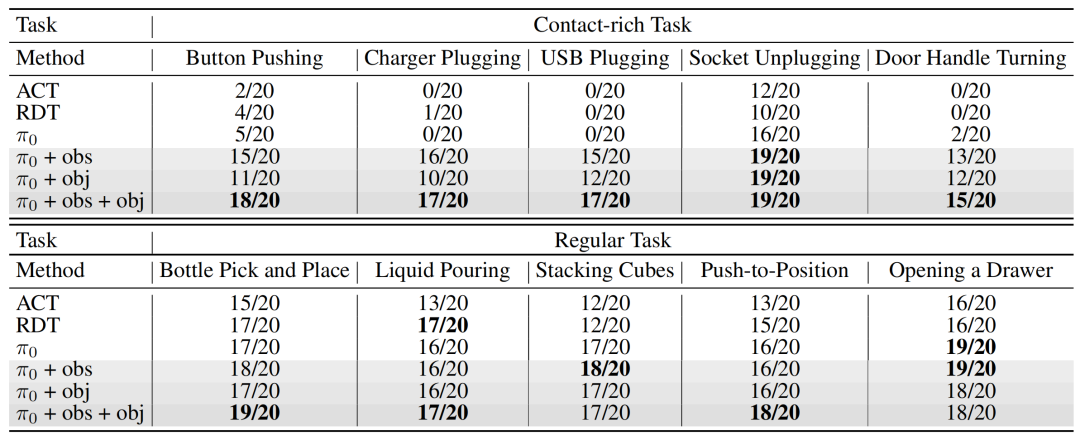
▲图6|TA-VLA的方法及其变体始终优于基线方法,尤其在高频接触任务中表现突出。©️【深蓝具身智能】编译
总结
TA-VLA仅通过在解码器上进行扭矩历史的单token聚合编码与动作-扭矩联合扩散生成,就达到了在接触密集型任务中远超传统VLA模型的成功率(如充电器插入任务成功率提升50%以上),带来了无需外部力传感器即可实现精准物理交互的优势。

推荐阅读





×
右键可直接复制图片