
 阅读时间大约9分钟(3451字)
阅读时间大约9分钟(3451字)
2025-09-26 学会快慢思考的VLA大模型:下一站会与世界模型融合吗?
来源:机智视界
将这种算力增长变为可管理及可优化,是当前具身智能大模型能够实际部署与达成落地的核心挑战。
出品:机智视界
01
“快慢思考”理念的提出
《思考,快与慢》,这是由诺贝尔经济学奖得主丹尼尔·卡尼曼写的一本畅销书。在书中作者首次提出了快慢思考组合,从心理学的角度揭示了人类高效决策的思维模式。
我们的大脑,由“快思考”和“慢思考”两套认知系统组合而成,其中:“快思考”主导了我们日常生活中约95%的事情,我们能毫不费力,凭直觉或习惯完成工作,比如识别微表情、选择早餐、系鞋带等;约5%的事情由“慢思考”处理,比如初学驾驶、探寻一个新地方、学习一门外语等,“慢思考”需要我们保持专注与逻辑,过程耗时且慢。
我们的大脑会根据事物的复杂度或熟悉度,自主切换快思考与慢思考。初学驾照的新手在行驶变道时往往表现得“犹豫不决”,这是由“慢思考”的理性决策、小心判断所致;当新手熟能生巧、驾轻就熟之后,便会在“快思考”主导下,毫不费劲地完成观察后视镜、打转向灯、转动方向盘等一系列操作了。
备注:快慢思考脑示意
02
大语言模型(LLM)的“快思考”与“慢思考”
以DeepSeek大语言模型为例,笔者演示如何模拟人脑进行“快思考”与“慢思考”。
例子:笔者想知道最近一周深圳的天气情况,为即将出差做准备。于是,笔者给DeepSeek发消息:“请告诉我最近一周深圳的天气情况”。此类问题属于日常问答,无须AI进行深度思考或推理,仅须上网搜索并整理信息,于是笔者激活DeepSeek的“联网搜索”功能,并关闭“深度思考”。
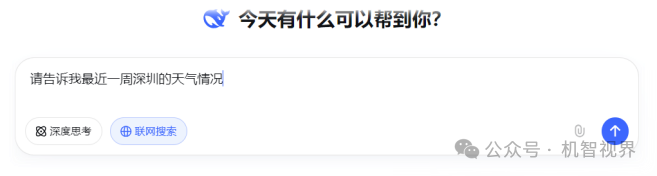
DeepSeek很快便给出深圳最近一周的天气预报以及出行活动建议。这就是一种AI大模型模拟人脑进行“快思考”的简单应用。
备注:让AI模拟快思考
接着,笔者需要准备一份出差报告,报告要求体现专业性和深度分析。此类问题笔者希望用到AI大模型的深度思考与推理能力,于是我激活了DeepSeek的“深度思考”功能:
于是DeepSeek开启拟人化“慢思考”过程,整个思维链CoT(Chain of Thought)清晰可见,耗时约7秒的思索之后,最终给笔者输出了一份颇有专业度&实用价值的出差报告。

备注:让AI模拟慢思考
03
VLA大模型如何学会快慢思考
接下来,笔者将围绕当前具身智能领域广泛采用或重点探索的视觉-语言-动作模型(Vision-Language-Action Model, VLA),与各位读者共同探讨。
首先,说明VLA的基本概念及技术渊源;其次,解析VLA底层架构如何支撑“快思考”与“慢思考”的双重能力;最后,系统总结这两种机制在VLA中的实现路径与协同流程。
1. VLM和VLA,一个字母之差,但截然不同
VLM(Vision Language Model):视觉-语言大模型,其核心功能是感知与规划,无须与物理世界进行交互,可理解为仅有大脑。
VLA(Vision Language Action Model):视觉-语言-动作大模型,其核心能力是感知、规划与执行,须与物理世界进行交互,不仅有大脑,还有小脑及身体。
VLA最终要落地到执行端,需要对身体进行控制;而VLM却不需要,它就像一个活在缸中的大脑,只需要完成思考和交流。VLM和VLA存在以下关系:
VLM是VLA的基础
绝大多数VLA模型都是以VLM模型为基础开始预训练的。
通过VLM模型,具身智能先学会视觉与语言之间的关联(“这是什么?”)和语义理解(“为什么?”)。
接下来才是在真实的物理世界中对动作数据进行关联与调整,这一步将教会VLA模型如何将概念理解、高级指令等(VLM模型的输出)映射为具体的机器人动作(怎么做?)
VLA是VLM的“具身化”扩展
VLA是VLM在物理世界中的身体扩展(例如:拥有一个身体,有“手、脚”)。VLM提供了大脑思考能力,而VLA则拥有了与现实环境交互并执行任务的能力。
2、解析支撑快慢思考的VLA模型底层架构
谷歌是首个发布VLA大模型的公司,将视觉(Vision)、语言(Language)输入直接映射成机器人动作(Action),其关键创新点在于将所有模态信息如视觉、语言、动作都转化成“一种语言”即Token序列。在VLA模型中的实现“快思考”与“慢思考”的方式主要有以下几种:
分层架构
这是最直接的实现方式,采用两个相对独立的子系统进行分工协作。
慢系统(S2)是一个大型的视觉语言模型,输入图像、语言指令,进行深度语义理解、场景分析、任务分解、宏观规划,输出全局性、概念性的任务计划或高级指令。
快系统(S1)则是一个动作策略模型,输入来自慢系统(S2)的任务计划或高级指令,将其转化为具体的、底层电机控制命令,输出高频、连续的动作指令。
特点:结构清晰,但两个子系统之间往往存在通信延迟和误差累积。
嵌入式架构
将快系统嵌入到慢系统中。通过对“慢系统”(VLM,视觉语言模型)进行主体改造,当图像、指令输入VLM模型之后,由模型的前几层进行深度语义理解和任务规划(即“慢思考”),模型的后几层被设计成直接输出高频动作(即“快思考”)。
特点:将执行模块直接嵌入VLM模型,快慢思考无缝衔接,避免独立子系统间的切换。
混合专家架构
这是一种基于MoE(Mixture of Expert,混合专家)思想的架构。
模型内部有多条专用处理通道(类似不同专家),由一个路由器负责根据输入任务的复杂度,动态决定激活哪条通道(使用哪个专家)。
特点:按需分配算力,保证性能且效率最大化,但须评估设计、训练难度。
基于解析,笔者总结快慢思考的本质是一种理念,并非一种固定架构。
3、基于不同“快慢”架构的VLA大模型举例
目前,采用上述不同快慢思考协作架构的VLA大模型包括:
Figure AI自研端到端VLA大模型Helix:分层架构,采用快系统(S1)和慢系统(S2)两个独立子系统,其中S2使用7B参数的视觉语言模型进行语义理解,S1则专门负责200Hz的高频动作控制。
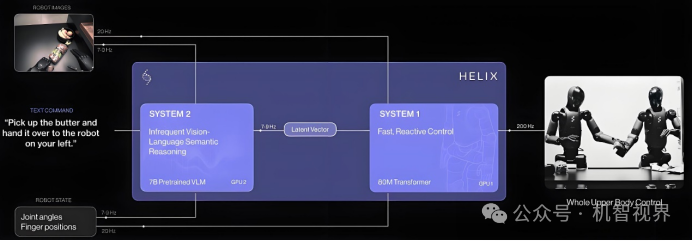
备注:Figure AI端到端VLA大模型Helix系统架构
北大与港中文FiS-VLA、智平方推出GOVLA开源版:嵌入式架构,将快速执行模块嵌入预训练视觉-语言模型(VLM)中,实现快慢系统一体化,克服分层架构带来的延迟和误差,提高资源利用率。
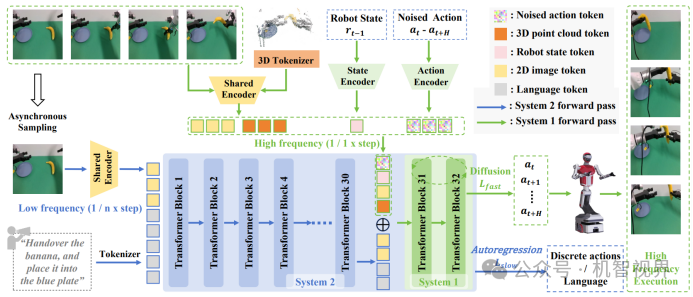
备注:北大与港中文FiS-VLA框架(来自FiS-VLA论文)
智元通用具身启元大模型Genie Operator-1:混合专家架构,由VLM + MoE(混合专家)组成,其中Latent Planner(隐式规划器,泛化的动作理解能力)和Action Expert(动作专家,精细的动作执行能力)是MoE的关键组成。
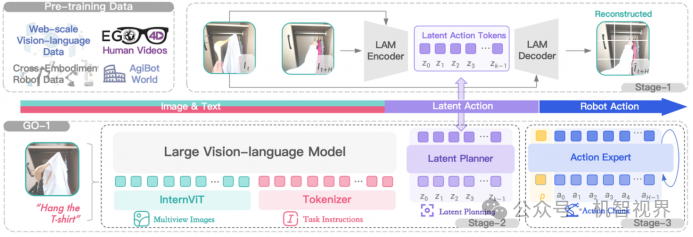
备注:智元GO-1大模型采用VLM+MoE架构(来源智元官网)
4、快慢系统的实现路径与工作协同
快慢思考架构让AI拥有了像人一样的两种能力:一种是直觉反应,一种是深度思考。它不仅让机器人在做决策和执行任务时更加高效与可靠,还能更好地适应陌生或复杂的环境。
具体来说,机器人可以根据当前情况自主判断——是应该立刻行动,还是先想好步骤再行动。这样一来,它不仅更容易成功完成任务,也大大减少了因盲目行动导致的安全风险。
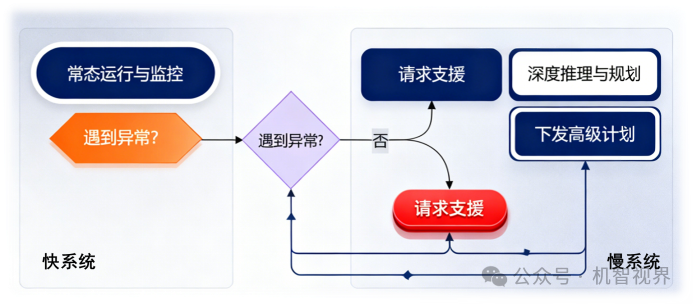
备注:快慢系统的实现路径与工作流程
常态由快系统主导:机器人90%以上的日常操作由高效、低能耗的“快系统”完成,保证流畅性和实时性。
异常触发慢系统:当快系统遇到其无法处理的异常、未知或高难度任务时,它会向慢系统发送“求助”信号。
慢系统提供高级指导:慢系统被“激活”,接管处理。它并不直接生成底层动作,而是输出一个高级的、抽象的计划(例如:“步骤一:定位苹果;步骤二:规划无碰撞路径;步骤三:执行抓取”)。
快系统执行计划:这个高级计划被下发给快系统,快系统将其转化为具体的、实时的电机控制指令来执行
交还控制权:任务完成后,控制权再度交还给快系统,慢系统进入“待机”状态以节省能耗。
04
由快慢双系统架构引发的算力担忧
以Figure AI的VLA大模型Helix为例:其慢系统(S2)使用7B参数的视觉语言模型进行语义理解;快系统(S1)输出200Hz的高频动态控制。
从存储角度看:
模型参数通常以32位浮点数(FP32) 存储,那么7B模型的纯参数大小约为:7,000,000,000×4字节 =28 GB。为了高效推理,通常会采用半精度(FP16) 或 BF16,此时模型大小约为14 GB。
这意味着要仅仅是把Helix的慢系统(S2)模型加载起来,就至少需要一张显存大于16GB的显卡,意味着它无法在低端设备上运行,只能部署在高性能嵌入式平台(如Jetson Orin)或边缘显卡(如RTX 4090)上。
从模型能力角度看:
7B规模是模型开始展现出强大推理、理解和生成能力的门槛,但也只能属于“入门级”强大模型。对于动辄700亿(70B)参数的超大模型,我们来估算一下它的算力需求:
生成一个token所需的基础计算量约为 2 * 参数数量
对于70B模型,单次推理的计算量约为 2 * 70B = 140 GFLOPs
这意味着,处理一个输入,S2需要完成1400亿次浮点运算。
从硬件选型角度看:
考虑到GPU标称算力(如100 TFLOPS)通常是理论峰值。实际应用中,由于内存带宽、模型架构等因素限制,能达到其30%-60%就已非常高效。

备注:机器人算力平台(来自英伟达网站)
加上模型的延时及频率要求、处理多模态数据增加的计算负担、双系统调度开销,以及训练这些模型需要大规模数据集(例如,OpenVLA使用了97万条真实世界机器人轨迹进行预训练),双系统架构确实导致了算力需求的激增。
总结:笔者认为如何将这种算力增长变为可管理及可优化,是当前具身智能大模型能够实际部署与达成落地的核心挑战。
05
未来展望:
会快慢思考的VLA与世界模型的融合
在谈及具身智能商业落地所面临的核心挑战时,宇树科技王兴兴曾一针见血地指出:“当前最棘手的问题是具身智能模型,不够泛用性,实用性还有待更大的提升。”这句话直面了行业当前最真实的困境。
回看文中讨论过的几类大模型——LLM(大语言模型)、VLM(视觉语言模型)和VLA(视觉语言动作模型),它们功能相近却又各有侧重,的确容易令人混淆。
这也引发出一个更深层的思考:这些模型最终会走向统一吗?具身智能领域是否会出现一个真正意义上的“大一统模型”,能够彻底打通感知、认知与行动之间的屏障?
在探索“大一统模型”的道路上,智能汽车公司似乎比人形机器人公司走得更快一步,尤其是在自动驾驶这一领域。理想汽车在2024年7月5日的智驾发布会上,正式推出了其全新的自动驾驶技术架构。该架构创新性地融合了视觉语言模型(VLM)、视觉语言行动模型(VLA) 及世界模型(World Model)于一体。

备注:全场景智能驾驶(来自理想汽车官网)
笔者坚信,在技术演进过程中,各个发展阶段诞生的具身智能模型将不断融合,终将统一于一个具备完全泛化能力的架构之中——或许,我们可以暂且将这一终极形态,归于“世界模型”的构想之下。
(备注:世界模型能预测未来、理解因果,并进行反事实推理,但它不是一个特定的算法,而是一个目标、一种能力)

推荐阅读





×
右键可直接复制图片