
 阅读时间大约10分钟以上(4874字)
阅读时间大约10分钟以上(4874字)
2025-10-28 五校联合发布!DeSa2VA 框架破解多模态分割模态鸿沟!
来源:豆包
杭叉、中力、井松。
作者:李鑫 出品:具身智能大讲堂
随着基础模型技术的持续发展,计算机视觉分割领域的范式正发生关键转变,从传统 “任务专用” 模式逐步向 “可提示、可迁移” 的统一框架演进。其中,SAM、SAM-2 等基础分割模型已实现点或像素提示下的零样本分割,多模态大语言模型(MLLM)更进一步将语言上下文融入视觉处理流程,为分割任务赋予更强语义理解能力。
然而,技术融合过程中仍存在核心瓶颈:MLLM 输出的高维隐藏状态与 SAM-2 依赖的点级提示在模态上存在天然鸿沟,这一问题导致动态视觉信息与静态语义相互缠绕,直接削弱了分割、问答等下游任务的精度与效率,成为制约技术进一步突破的关键障碍。
此前,Sa2VA 等研究提出 “以语言引导分割” 的思路,但该方案存在 [SEG] 标记语义稀疏、文本理解能力弱、缺乏细粒度引导等痛点。在此基础上,研究人员探索出 “先解耦、再对齐、后融合” 的技术路线,为突破模态鸿沟提供了新方向。
近日,来自中山大学、兰州大学、合肥工业大学、香港大学和新加坡国立大学的联合研究团队,针对这一行业难题展开攻关。受 “语言驱动分割 + 模态显式解耦” 理念启发,团队成功研发出 DeSa2VA(Decoupled Semantic-Aware Visual Augmentation)—— 一种面向基础分割模型的解耦增强提示框架。
据了解,DeSa2VA 通过多步骤技术设计实现性能突破:首先将文本标签转化为 SAM-2 可解释的点级提示并生成监督掩码,借助像素级交叉熵与 Dice 混合损失完成文本 - 视觉对齐预训练;随后通过双线性层结构,将 MLLM 隐藏状态显式解耦为富语义文本表征与细粒度视觉表征;在动态掩码融合环节,以预测文本 / 视觉掩码与真实标注的 “三重监督” 协同引导 SAM-2 生成掩码,最终显著提升图像、视频分割及视觉问答任务的准确性与鲁棒性。
该研究成果的核心价值体现在三大方面:
一是提出解耦增强提示新范式,将 MLLM 生成的注释显式拆分为 “文本 / 视觉” 两类富语义表征,以极低训练开销充分利用多模态信号;
二是构建文本 - 视觉对齐训练机制,通过文本标签转点级提示、生成监督掩码,结合像素级交叉熵与 Dice 损失,系统训练 SAM-2 产出 “文本支撑” 的分割掩码;
三是设计双线性层与动态掩码融合方案,并行学习模态特定表示,经卷积精炼后以 “三重监督” 注入 SAM-2,有效提升掩码精度与场景级静 / 动态理解能力。
目前,该研究成果的相关论文预印本已以 “Decoupled Seg Tokens Make Stronger Reasoning Video Segmenter and Grounder” 为题发表于 arXiv 平台(论文编号:2506.22880),其中党吉圣担任第一作者,吴旭东、王笔美、吕宁、陈佳钰、赵竟雯、刘怡初、刘冀钊、李俊成、王腾为共同作者。
1►SAM-2 提速提效 模态差距成多模态融合关键瓶颈
近年来,分割方法的快速发展,尤其是基础模型(foundation models)的出现,已深刻地改变了计算机视觉领域的格局。Segment Anything Model(SAM)首次引入了可提示分割(promptable segmentation)的概念,使模型能够通过点或像素级提示(point or pixel prompts),以零样本(zero-shot)的方式分割未见过的目标对象,其背后采用了类似链式思维机制(chain-of-thought mechanism)的推理流程。这一范式模糊了传统意义上分割(segmentation)与识别(recognition)之间的界限。在此基础上,SAM-2进一步实现了更快的推理速度、更高的精度以及更强的多维数据处理能力,从而将可提示分割的应用范围扩展到了视频级任务(video-level tasks)。
与此同时,多模态大语言模型(Multimodal Large Language Models, MLLMs)的兴起进一步推动了分割任务的精细化发展。诸如 Sa2VA和 MemorySAM 等方法,将 MLLM 与分割模型进行融合:一方面利用语言特征来引导分割过程(language-driven segmentation),另一方面通过分割线索来增强语言理解能力(enhance language understanding)。然而,一个关键的挑战依然存在:SAM-2 本质上依赖于基于点的提示(point-based prompts),而 MLLMs 输出的是高维的隐藏状态(high-dimensional hidden states)。如何弥合这种模态差距(bridge the modality gap),使分割模型能够有效理解并利用语言模型生成的信号,成为提升分割精度与效率的关键问题。
Sa2VA 通过在多模态大语言模型(MLLM)中联合编码图像–文本输入来应对这一挑战。与分割相关的表征被标记为 [SEG] 标记,并输入至 SAM-2,以引导掩码生成(mask generation),并实现对静态/动态内容的场景级理解(scene-level understanding)。尽管 Sa2VA 在图像与视频分割任务以及图像与视频问答任务中表现出色,但其有效性仍受到三个关键限制的阻碍:i) 语义信息不足(Insufficient Semantic Information)。[SEG] 标记缺乏丰富的语义内容,限制了 MLLM 输出与 SAM-2 视觉能力之间的对齐。ii) SAM-2 的文本理解有限(Limited Textual Understanding in SAM-2)。SAM-2 缺乏针对文本任务的显式训练,导致视觉提示与文本语义之间存在不对齐。iii) 缺乏细粒度视觉引导(Absence of Fine-Grained Visual Guidance)。[SEG] 标记仅提供高层提示,限制了解码器生成精确分割掩码的能力。
2►突破模态差距:DeSa2VA 提升 SAM-2 分割能力
为了解决这些限制,本文提出了 DeSa2VA(Decoupled Semantic-Aware Visual Augmentation),一种新的框架,用于在增强基于提示的特征学习的同时对上下文信息进行解耦。不同于现有方法(如 InternVL 和 SAM-2),本文的方法显式地将视觉和文本模态进行解耦,以提升提示质量。通过分别处理模态特定特征(modality-specific features),分割模型能够更好地理解语言与视觉线索,从而获得更准确、更鲁棒的预测。具体而言,该框架采用一种双线性层结构(dual-linear-layer architecture),用于从 MLLM 输出中解耦文本和视觉信息。两个并行的线性层分别学习模态特定表征:一个捕获基于文本的注释,另一个提取视觉线索。这些层生成独立的隐藏状态,随后经过卷积处理并传递给 SAM-2,以引导掩码生成(见图 1)。
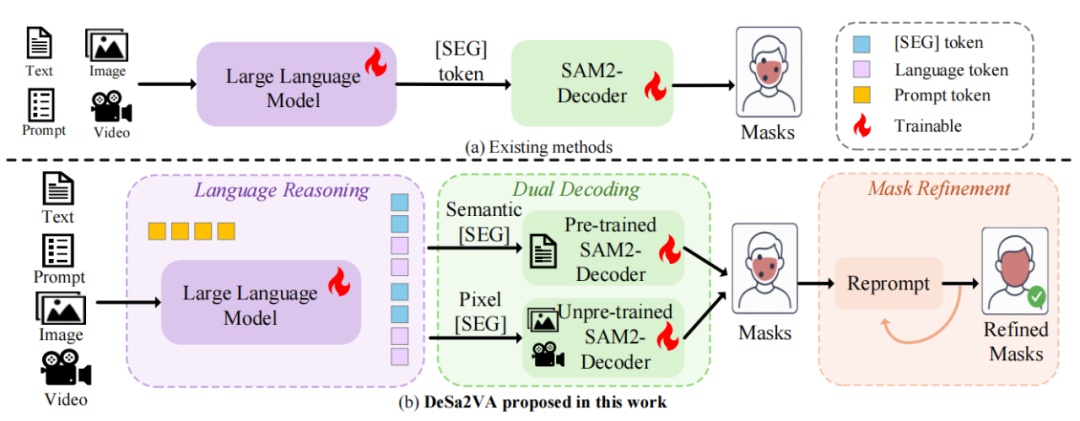
图 1:本文提出的 DeSa2VA 的创新点。(a) 基线模型。(b) 研究团队的模型引入了解耦增强提示模块(decoupling-enhanced prompt module),将信息解耦为文本和视觉线索,以增强分割模型的提示能力。同时,研究团队引入了文本理解预训练,使 SAM-2 能够处理解耦后的文本信息。
为确保训练的稳定性,文本标签被转换为 SAM-2 可解释的点级提示(point prompts),并与图像像素结合以生成监督掩码。模型通过最小化预测掩码与真实掩码之间的像素级交叉熵损失(pixel-wise cross-entropy loss)和 Dice 损失(dice loss),学习文本与视觉的对齐关系。在预训练阶段之后,于解耦阶段提取并优化模态特定的表示。仅需极少量的额外训练,这些解耦后的特征即可支持下游任务(如视觉问答、参考分割等)。
总结而言,本文的主要贡献如下:
• 团队提出了一种新的解耦策略,将 MLLM 生成的标注解耦为相互独立且语义丰富的文本/视觉表征,从而以极低的训练开销高效利用多模态信号。
•团队引入了一种文本–视觉对齐训练方法,使文本标注与视觉特征对齐,并通过监督损失训练 SAM-2 生成与文本相关的掩码。
•团队的方法在分割和视觉问答任务上取得了当前最优的结果,消融实验进一步验证了其稳健的泛化能力。
3►DeSa2VA的具体研究方法
1. 总体思路与框架
DeSa2VA 以“显式解耦”为核心,将多模态大模型输出的混合语义拆分为两条可控子空间:文本子空间与视觉子空间。两路表征在同维潜在空间内完成对齐与融合,再输入分割模型的解码器生成掩码。该设计针对“MLLM 高维语义”与“SAM2 点/掩码提示”之间的模态差距,提供了一条结构化、可训练的桥接路径。
2. 模态解耦模块
来自多模态大模型的隐藏状态经两条并行线性层分别映射为文本表征与视觉表征,统一到相同维度与形状以便后续融合;另设第三条线性层专门处理真实文本,用于训练分割模型的文本理解能力。这样既保留模态差异,又保证可在统一空间内进行前向与反向传播。
3. 对抗与互信息双约束
为让两路表征真正“可分可用”,训练中引入两类约束:
·基于梯度反转层的模态判别对抗,将解耦模块视作生成器、模态判别器视作判别方,通过最小化与目标模态分布的 Jensen–Shannon 散度,使文本与视觉表征分别落入近似正交的子空间。
·基于 CLUB 的互信息最小化,对文本表征与视觉表征间的互信息给出可优化的上界并最小化,在概率密度空间去相关,确保统计独立。
训练采用交替优化:周期性更新变分分布以收紧上界,再冻结它优化解耦模块,获得稳定收敛与有效解耦。
4. 文本理解预训练
为避免简单把语言信号“硬塞”进分割模型导致的错配,DeSa2VA 增设文本理解预训练。将数据集中的真实文本转换为 SAM2 可解释的点级提示,与编码器提取的像素特征联合输入解码器,生成文本掩码,以像素级交叉熵与 Dice 损失监督。得到的文本解码器在主训练阶段可按需冻结,用于服务解耦与跨模态对齐。
5. 文本理解预训练
训练时为文本与视觉各自建立独立监督链路:视觉分支以真实视觉掩码监督视觉预测;文本分支以由文本与像素联合生成的参考文本掩码监督文本预测;末端再将两路预测掩码进行融合,并与真实掩码计算最终损失。视觉损失、文本损失与最终掩码损失三者联合,既避免模态混淆,又增强跨模态协同。
6. 自反馈稠密提示
针对 seg_token 稀疏提示难以细化的问题,引入自反馈稠密提示:先用初始提示生成掩码,再将该掩码作为稠密提示回注模型、保持其他输入不变进行一次精炼。实验证明,单次自反馈即可带来接近多次迭代的收益,几乎不增加推理时延与参数量,同时显著提升图像与视频场景的分割质量。
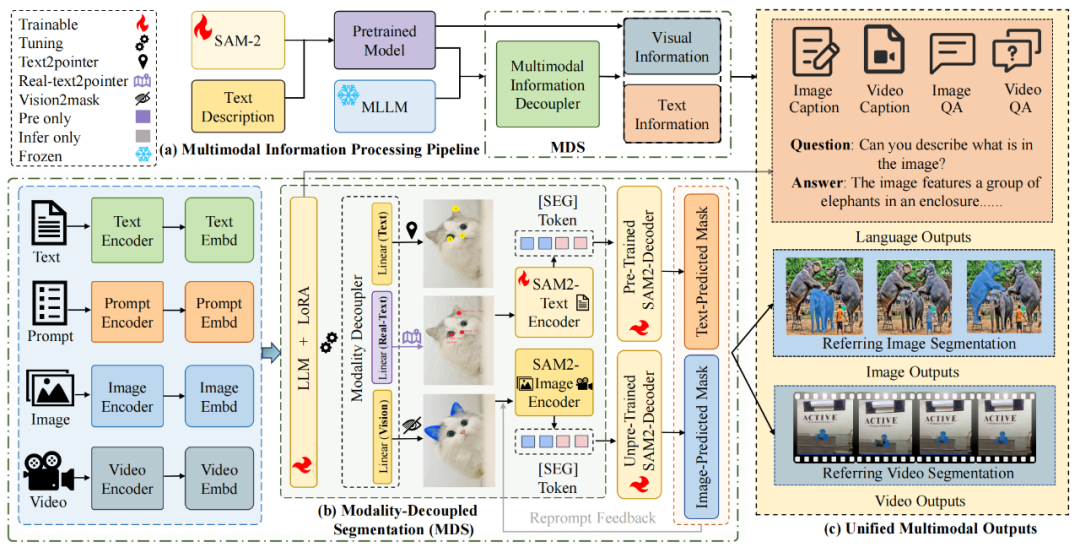
图 2:本文提出的 DeSa2VA 模型结构:(a) 在预训练阶段,团队让 SAM-2 学习将语义标签通过文本编码映射为点级特征;(b) 在主框架中,团队将多模态大语言模型(MLLM)的输出分离为视觉流和文本流,分别由未经训练的 SAM-2 解码器与预训练的文本解码器进行处理;(c) 最终,两个解码器生成的掩码被融合以得到最终输出掩码,同时由 MLLM 生成的问题—答案信息直接输出。
4►DeSa2VA:图像 / 视频分割与问答性能双优新模型
1. 实现细节
研究团队的框架在以往设计的基础上进行了增强,通过结合来自大语言模型(LLM)的标注数据与特定标签信息,实现了跨模态训练与理解。具体而言,研究团队使用 InternVL2.5_4b 生成文本问答对(question–answer pairs),以实现交互式语义建模,并为分割模型提供潜在语义信号。SAM-2 被用作核心分割模型,它接收来自多模态大语言模型输出的解耦单模态信息(文本与视觉流),并通过数据集中提供的文本标注进行文本理解预训练。
团队在四个任务数据集上对模型进行训练,涵盖图像与视频的问答与分割任务,总计约 110 万组图文/视频文本样本。其中,图像分割部分使用 RefCOCO、RefCOCO+ 和 RefCOCOg 数据集;视频分割部分使用 MeVIS、Ref-DAVIS17 与 ReVOS 数据集。为保持模型的问答能力,研究团队额外使用了 LLaVA 1.5 的 6.65 万条数据与 ChatUniVi 的 1 万条数据。此外,还引入 Glamm_data 与 Osprey-724k 数据集,以增强细粒度图文对齐能力并进行大规模基础训练。
2.定量结果
图像/视频分割任务。表 1 展示了在多个分割基准上的性能对比结果。采用所提出的解耦策略后,研究团队的模型在 RefCOCO、RefCOCO+ 和 RefCOCOg 数据集上分别取得了 82.6、77.8 和 79.2 的成绩,相较于基线模型 Sa2VA 分别提升了 3.7、6.1 和 5.1 个百分点。这一显著提升得益于研究团队将语言模型的隐藏信号显式迁移至分割模型,并通过线性对齐层更好地融合文本特征,从而强化了解码器的训练效果。
在视频分割基准 MeVIS、Ref-DAVIS17 和 ReVOS 上,研究团队的模型分别获得了 46.7、76.1 和 70.1 的分数,较 Sa2VA 也有小幅提升。通过将视觉与文本模态显式解耦,分割模型能够更有效地处理异构输入,从而在图像与视频分割任务中均实现了更优性能。
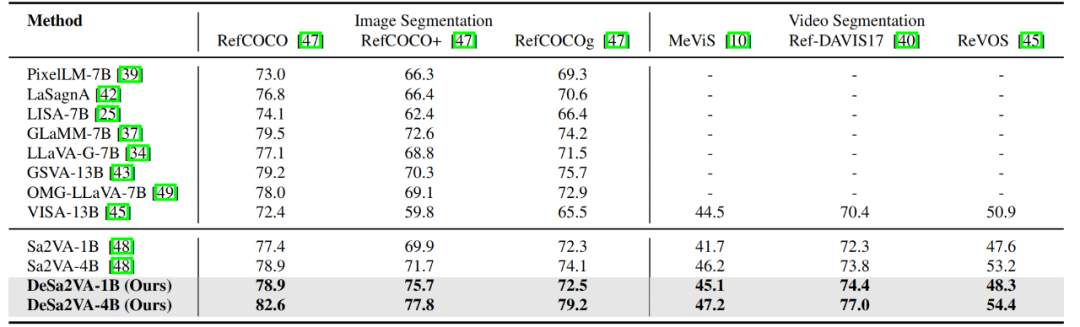
表 1: 图像/视频分割任务性能对比结果。无论采用 1B 还是 4B 模型规模,研究团队的 DeSa2VA 均在图像与视频分割任务上全面超越基线模型。
图像/视频问答任务。如表 2 所示,采用解耦策略并在 LLaVA-1.5(665K)数据集上训练的 4B 模型,在图像问答基准 SEED-Bench上取得了 73.3 的成绩;在视频问答基准 Video-MME上取得了 50.4 的成绩,与基线模型 Sa2VA 的表现相当。
这一结果与研究团队解耦算法的设计目标一致——通过将语言模型的隐藏输出进行解耦与迁移,从而增强分割模型的特征理解与掩码生成能力,而不会干扰语言模型本身的理解与推理过程。由于问答任务仍由语言模型主体负责,解耦策略在保持语言理解能力不变的同时,显著优化了与分割相关的部分。
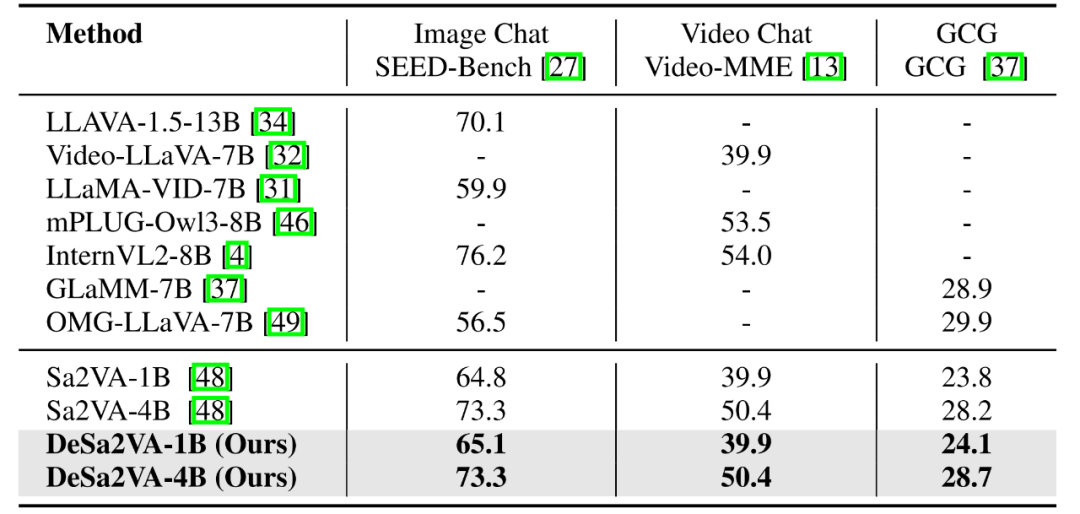
表 2:不同方法在问答任务与 GCG 任务上的结果对比。
GCG 验证集结果。在 Grounded Caption Generation (GCG) 任务中,研究团队评估了模型在图像与文本对齐方面的能力。区域定位精度通过分割掩码的平均交并比(mIoU)进行衡量;文本生成准确性则通过 BLEU 与 CIDEr 指标进行验证。同时,研究团队引入了跨模态召回率(cross-modal recall)来评估短语与掩码之间的对应一致性。
如表 2 所示,在采用信息解耦与增强提示后,研究团队的 1B 与 4B 模型分别取得了 24.1 与 28.7 的得分,均优于基线模型。这表明 DeSa2VA 在复杂场景中具备稳定的跨模态关联能力,能够同时实现高质量的分割与文本生成表现。该实验结果进一步验证了多模态解耦与增强提示机制在细粒度图文对齐任务中的有效性。
3. 定性结果
图 3 展示了研究团队模型在视觉问答(VQA)与语义分割(Semantic Segmentation)任务上的联合表现。实验使用来自网络的真实图像,并通过研究团队的统一框架进行处理,实现了视觉推理与像素级分割的同步生成。结果显示,模型能够根据用户文本查询中的语义线索自适应调整分割区域,体现出对语言提示的动态响应能力。这种“理解文本、感知图像、协同生成”的一体化推理能力,充分体现了 DeSa2VA 框架在跨模态理解与视觉语义联动方面的优势。

图 3:问答与分割结果展示。左侧为输入图像及模型生成的准确文本描述,右侧为对应的分割结果,展示了模型在满足语义问答的同时,具备精确完成分割任务的能力。
5►结语与未来:
研究团队提出的DeSa2VA 框架,有效解决了现有视频分割与 grounding 模型中动态视觉与静态语义纠缠、SAM-2 文本理解不足等问题。框架通过文本预训练将文本标签转为点提示并优化,以线性投影解耦 MLLM 隐藏状态为文本 / 视觉特征子空间,再经动态掩码融合与三重监督提升性能。同时在在 110 万组样本上训练,图像分割、视频分割及问答任务均超 Sa2VA 等基线,GCG 任务也验证其细粒度图文对齐能力,为多模态视觉任务提供高效解决方案。
后续研究团队计划通过时间解耦策略,进一步优化模型对视频动态序列信息的处理能力,减少跨任务训练中的干扰,从而在保持图像分割精度的同时,提升视频分割任务的表现,推动多模态视觉模型在时序相关任务中的适配性与稳定性。
论文链接:https://arxiv.org/abs/2506.22880
开源地址:https://github.com/longmalongma/DeSa2VA

推荐阅读





×
右键可直接复制图片