 阅读时间大约6分钟(2264字)
阅读时间大约6分钟(2264字)
2025-10-30 黄仁勋GTC 2025演讲:一场关于虚拟超级GPU、物理AI与机器人、量子计算、AI工厂的豪赌!
来源:英伟达
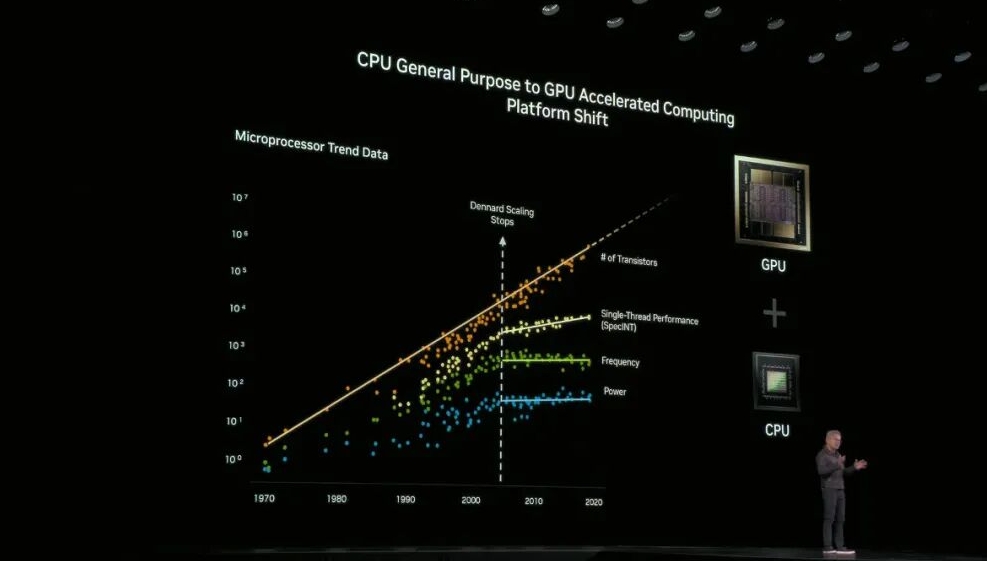
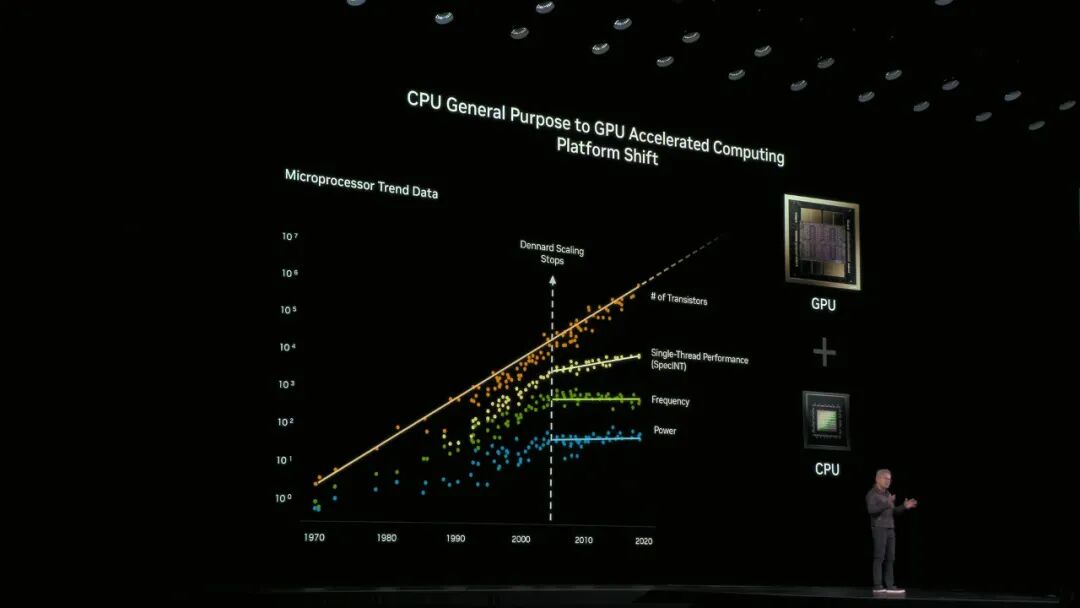
摩尔定律已正式终结,晶体管数量的增长已无法带来同等的性能与功耗优化。
作者:李鑫 出品:具身智能大讲堂
2025 年 10 月 29 日,NVIDIA 在华盛顿特区举办 GTC 大会,创始人兼 CEO 黄仁勋在主题演讲中明确表示,摩尔定律已正式终结,晶体管数量的增长已无法带来同等的性能与功耗优化。
黄仁勋在演讲中披露,Blackwell 架构已在亚利桑那州实现全面投产,未来六个季度相关业务规模预计达 5000 亿美元。他对此解释:“现在 AI 模型足够强大,客户愿意为它们付费,这证明计算基础设施建设具备经济合理性。” 大会当天,NVIDIA 股价上涨近 5%,收于 201.03 美元。
1►“Extreme Co-Design” 解决方案 推理性能提升10倍
针对算力供给问题,英伟达提出 “Extreme Co-Design” 解决方案,即打破 GPU 独立单元限制,通过系统级整合来提升效能。黄仁勋介绍,Blackwell 架构通过 NVLink-72 互联结构,将 72 颗 GPU 整合为虚拟超级 GPU,推理性能较上一代提升 10 倍,Token 生成总拥有成本(TCO)实现行业最低。

黄仁勋表示:“Hopper 架构全生命周期出货量 400 万颗,Blackwell 预计发货量将达 2000 万颗。” 他同时确认,下一代 Vera Rubin 架构已进入推进阶段,配合研发的 CPO 硅光子技术,将针对性解决数据中心带宽与能耗问题。

黄仁勋强调:“过去十年算力提升十万倍,2012 年深度学习爆发后,每四到五年完成一次技术变革,这种积累并非偶然。”
2►英伟达物理 AI 聚焦自动驾驶、工业与机器人、能源三大方向
黄仁勋在演讲中明确界定 “物理 AI” 为 “AI 技术与物理世界深度交互的应用形态,核心是通过数字孪生、实时感知与自主决策,实现对实体系统的精准控制与效率优化”,并披露自动驾驶、工业与机器人、能源三大核心落地方向。
作为物理 AI 最成熟的应用场景,黄仁勋重点发布 NVIDIA DRIVE AGX Hyperion 10 参考级量产平台,该平台集成 14 个 800 万像素高清摄像头、9 个毫米波雷达、1 个 128 线激光雷达及 12 个超声波传感器,搭载两台基于 Blackwell 架构的 DRIVE AGX Thor 计算单元,单平台算力达 1000 TFLOPS,可并行运行自动驾驶与座舱娱乐双堆栈系统。

合作落地方面,黄仁勋宣布四方合作协议:Stellantis 将基于该平台生产 L4 级自动驾驶出租车,2026 年先行交付 5000 辆接入 Uber 运营网络,2027 年实现 10 万辆车队规模化部署。

同时,Aurora 与大陆集团将集成该平台至无人驾驶卡车方案,计划 2027 年完成物流场景商业化落地。针对技术适配性,黄仁勋特别指出:“DRIVE Thor 芯片针对视觉语言模型优化,能在暴雨、强光等极端环境下保持 99.9% 的目标识别准确率,这是物理 AI 应对复杂现实场景的核心能力”。

工业与机器人领域,英伟达正聚焦Isaac 机器人开发平台 与 IGX Thor 边缘 AI 平台构建云端训练边缘执行的链路。目前机器人初创公司 Figure已基于Isaac平台构建 Helix 视觉 - 语言 - 动作(VLA)模型,该模型采用分层式 “大小脑” 架构,可实现对象泛化识别、上半身毫米级精准控制及双机协同作业,无需依赖云端算力即可独立完成仓储分拣、设备检修等任务。迪士尼则利用 Isaac Sim 仿真环境,训练主题公园服务机器人在人流密集场景中实现路径动态规划与游客交互。

针对工业边缘场景,新一代 IGX Thor 平台的核心参数同步公布:与上一代 IGX Orin 相比,集成 GPU 形态算力提升 8 倍,独立 GPU 形态算力提升 2.5 倍,接口连接性实现翻倍,支持在边缘端无缝运行 70B 参数级大语言模型与视觉语言模型。
在清洁能源领域,黄仁勋重点介绍与 General Atomics 及国际核聚变研究机构联合开发的 AI 驱动数字孪生反应堆,该项目基于 NVIDIA Cosmos 世界模型平台构建,整合 DIII-D 核聚变装置的 20 万次等离子体放电数据进行训练。
3►开源cuOpt决策优化平台 量子计算较传统方案效率提升200倍
本次大会上,黄仁勋正式宣布开源cuOpt 决策优化平台,该平台基于 CUDA-X 加速库开发,支持 Python、C++ 双语言接口,内置 200 + 预设优化算法模块,可覆盖物流路径规划、生产排程、资源调度等 12 类实体行业场景。
黄仁勋提出 “三级贡献体系”:基础用户可调用 API 接口实现场景适配,企业开发者能提交行业定制化算法模块,核心合作伙伴可参与平台核心代码迭代。
此外黄仁勋同步公布了 “cuOpt 开发者计划”,英伟达计划未来三年投入 2 亿美元设立专项基金,支持高校、初创企业基于该平台开发行业解决方案。

在商业生态方面,NVIDIA 向诺基亚支付 10 亿美元战略投资,双方联合推出ARC 电信计算平台,该平台采用 “Grace CPU+Blackwell GPU+ConnectX-9 网卡” 硬件架构,集成 AI-RAN 无线接入技术,可将基站负载处理能力提升 5 倍,同时将工业场景下设备间通信时延控制在 5 毫秒以内。
在生命科学领域,黄仁勋披露,礼来公司将投资 8 亿美元部署NVIDIA DGX SuperPOD 超级计算机和AI工厂,该系统搭载 1024 块 Blackwell B100 GPU,采用 NVLink-72 互联技术,总算力达 3.2 EFLOPS(FP16 精度),专门用于药物研发与基因分析,预计该系统将于明年1月正式上线。

为布局下一代计算技术,黄仁勋在 GTC 2025 演讲中正式宣布推出CUDA-Q 量子计算开发平台与NVQLink 量子互联架构。CUDA-Q 平台核心功能包括:支持量子电路设计、模拟与优化全流程开发,兼容 IBM Qiskit、Google Cirq、Rigetti Forest 等主流量子编程框架,可实现 “量子算法 - 经典算力” 无缝衔接。

关于 NVQLink 量子互联架构,黄仁勋在演讲中确认其技术路径为 “光量子通信链路”,核心作用是实现 GPU 与量子处理器(QPU)的直接连接。该方案数据传输速率达 10 Gbps,延迟控制在 1 微秒以内,较现有基于传统以太网的量子 - 经典通信方案效率提升 200 倍。
黄仁勋在演讲中明确表示:“未来五年,我们将聚焦‘量子 - 经典混合计算’的实用化,2028 年前实现 50 量子比特级处理器与 GPU 的无缝协同”,该目标将为物理领域复杂问题求解提供算力支撑”。
4►数据中心向 AI 工厂转型,三大核心硬件产品发布
黄仁勋在 GTC 2025 演讲中提出 “数据中心向 AI 工厂转型” 理念,将其定义为 “AI 时代核心生产单元”,核心产出是经模型训练生成的有价值 Token,标志计算设施从资源供给者向价值创造者跨越。
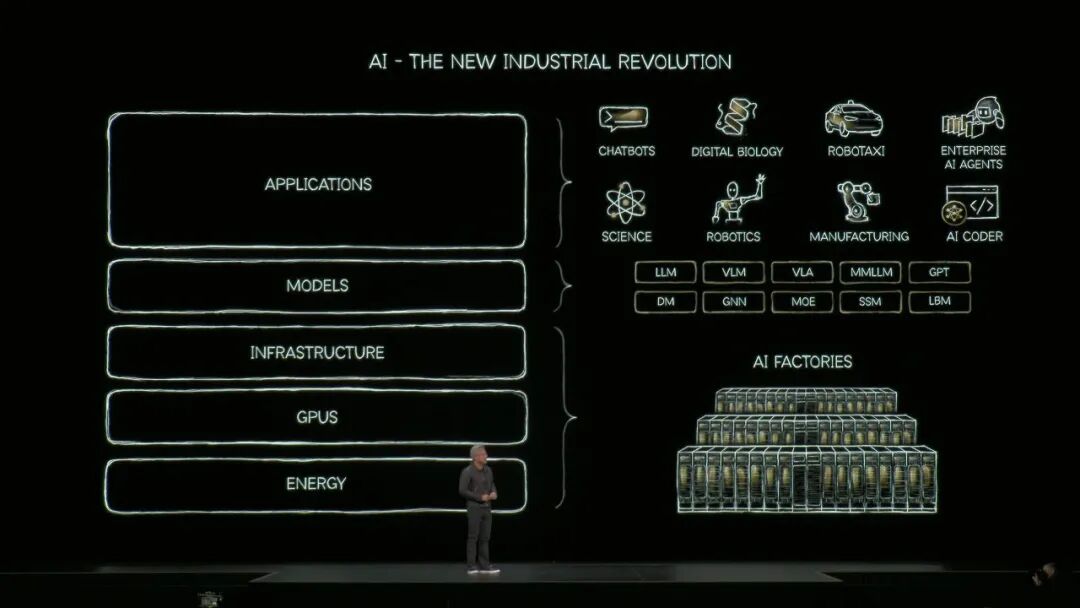
为支撑转型,NVIDIA 推出Omniverse DSX 数字孪生平台,整合 CUDA X 生态与物理仿真引擎,支持西门子等伙伴协同设计吉瓦级 AI 工厂的算力布局、电力及冷却系统,可通过微米级仿真规避建设瓶颈。黄仁勋披露该平台可为 1 吉瓦级工厂年增数十亿美元营收,目前弗吉尼亚州已启动相关研究中心。

为配合Omniverse DSX 数字孪生平台,英伟达发布了三款全新的硬件产品。

BlueField-4 DPU集成的专用 KV 缓存加速引擎可将模型长对话处理延迟降低 60% 以上。
ConnectX9 Super NIC作为新一代智能网卡,其单端口吞吐量突破 400Gb/s,支持 RDMA over TCP/IP 协议与 AI 流量优先级调度。
Spectrum-X 以太网交换机,采用自研的 Dragonfly+ 拓扑架构,可支持超 2048 个 GPU 节点的无阻塞互联。其集成的 AI 流量感知引擎能自动识别模型训练、推理等不同场景的数据流特征,动态分配带宽资源,彻底消除大规模分布式训练中的 “通信墙” 问题。

推荐阅读





×
右键可直接复制图片