
 阅读时间大约7分钟(2455字)
阅读时间大约7分钟(2455字)
2025-11-25 1000小时人类第一视角数据集!UCSD最新开发Human0模型 机器人学会“举一反三”!
来源:具身智能大讲堂
“数据+训练+适配”的组合拳,把人类数据的价值榨到了极致。
作者:李鑫 出品:具身智能大讲堂
在机器人操控领域,有个长期悬而未决的难题:比起大语言模型动辄亿万级的训练数据,机器人操控模型的“食材”始终不够多,导致它们在真实场景里总是“认生”,这就是我们经常谈到的机器人缺少泛化能力,当我们换个物体、变个环境,机器人就容易手忙脚乱。

最近,加州大学圣地亚哥分校的团队拿出了一套新方案:他们把人类日常的第一视角数据拆分成“野生场景”和“任务导向”两类,像搭积木一样组合使用,成功推出了名为Human0的操控基础模型。这套方法不仅让机器人学会了听懂没见过的指令,还能通过极少演示快速掌握新技能。
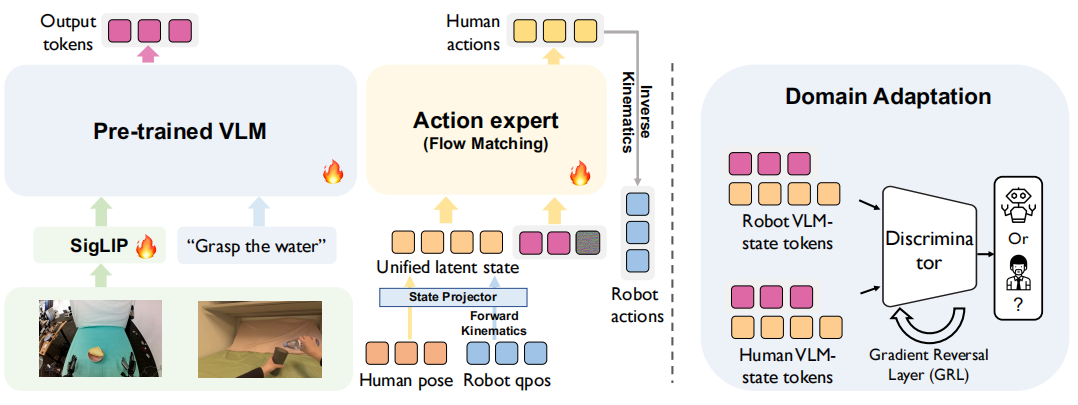
本文方法采用两阶段训练框架:(1)预训练阶段,以大规模“野生场景”人类数据与机器人数据为训练样本,所有数据均被映射至统一的“人类中心态-动作空间”;(2)任务后训练阶段,使用与任务目标对齐的人类及机器人演示数据进行微调。为弥合“具身差异”(即人类与机器人身体结构及运动机理的差异),研究团队引入域对抗判别器——该判别器以SigLIP视觉特征与动作-状态嵌入向量为输入,判断样本来源为人类数据还是机器人数据。通过梯度反转技术,此机制可促使策略网络的编码器学习“与具身无关的特征表示”,从而实现人类与机器人观测数据间的有效知识迁移。
1►新解法:三件套打通数据到能力的链路
团队没盯着单一问题死磕,而是搞了套“数据+训练+适配”的组合拳,把人类数据的价值榨到了极致。
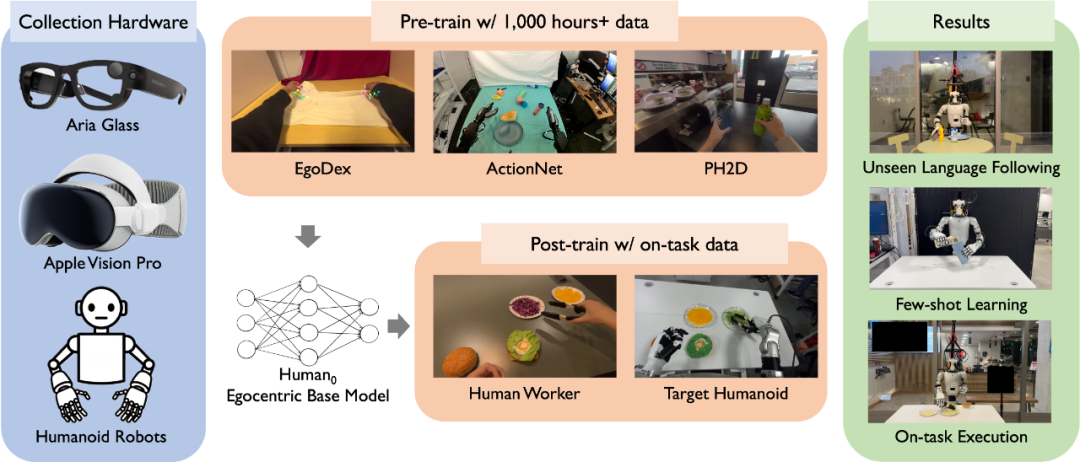
基于第一视角人类数据的大规模预训练与后训练方法。研究团队构建了一个大规模“人类-人形机器人物理交互数据集”(命名为PHSD),用于训练基础模型以学习第一视角下人类与机器人的行为模式。实验结果表明,Human0模型展现出多项优异性能,包括能精准响应机器人训练数据中未出现过的语言指令、具备少样本执行能力,以及在目标任务上的性能提升。
第一步:建个“超级数据集”PHSD
要让模型学好,先得有好数据。团队整合出的PHSD数据集,相当于给模型准备了“主食”和“配菜”:
“主食”是1000多小时的野生场景数据,来自EgoDex、ActionNet这些公开数据源。这些数据里有人类日常的各种动作——开瓶盖、叠衣服、切菜,能帮模型建立最基础的“动作直觉”。
“配菜”是20多小时的任务导向数据,专门针对机器人要做的活录制。比如让快餐店员戴着眼动仪做汉堡,让工人演示抓取零件,每段数据都和机器人的实际任务对齐,保证学了就能用。

研究团队开发的重定向软件套件,支持在“人类中心表征”与不同人形机器人之间进行动作重定向。图中展示了在MuJoCo仿真环境中,将同一人类动作重定向至不同人形机器人的过程。相关代码将对外开源。
更关键的是,团队给所有数据做了“统一翻译”:设计了一套“人类中心态-动作空间”,不管是人类的动作,还是Unitree H1、G1这些机器人的关节数据,都能通过逆运动学、手部重定向算法,转换成同一套参数。
就像不管说中文还是英文,都翻译成二进制让电脑懂,彻底解决了“身体不一样”的问题。
第二步:分阶段训练,先打基础再精修
数据准备好了,怎么教也有讲究。团队搞了“预训练+任务后训练”两阶段模式:
预训练阶段,主要用“野生数据”。模型先在1000多小时的人类动作里“泡着”,学怎么把视觉(看到的画面)、语言(听到的指令)和动作(该怎么动)对应起来。这时候会特意调整人类数据和机器人数据的比例,避免模型学偏,只认人类动作不认机器人动作。
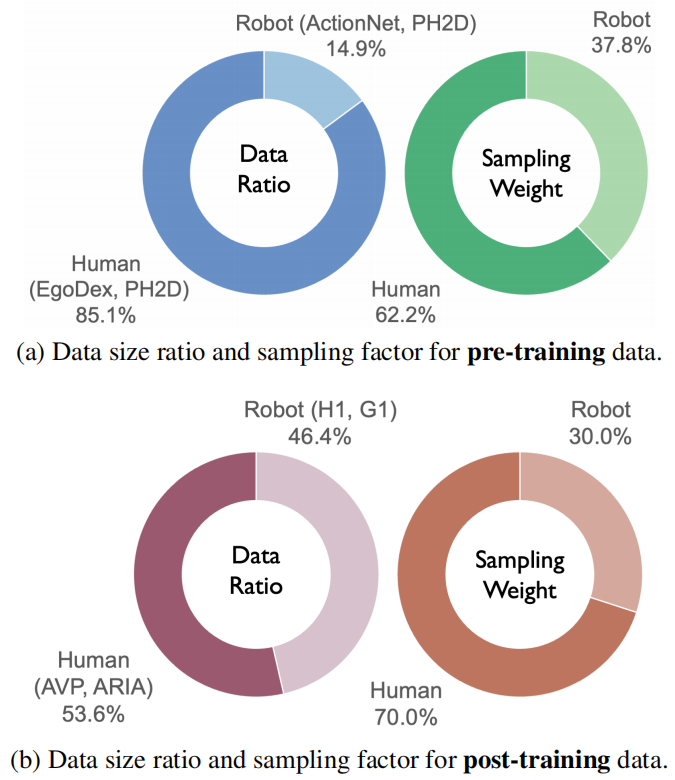
后训练数据的数据量占比与采样系数
任务后训练阶段,就聚焦具体任务了。比如要让机器人做汉堡,就用之前录的快餐店员数据来微调。这一步会多喂点人类数据——大概70%的采样权重,既能保留人类做汉堡的巧劲,又能快速适配机器人的机械结构,不会出现“学新忘旧”的情况。
第三步:让模型“分不清”人类和机器人
就算数据统一了,模型还是可能“耍小聪明”:偷偷记住人类数据里的细节(比如人类手的肤色)、机器人数据里的特征(比如金属关节),靠这些“捷径”判断该怎么动,而不是真的理解动作逻辑。这样一来,换个机器人或换个场景,模型就会“露馅”。
团队的办法是加个“域判别器”和“梯度反转层”:让判别器试着区分数据是来自人类还是机器人,同时用梯度反转层“捣乱”——每次判别器快分清的时候,就反转它的训练方向,逼着模型放弃那些“捷径”,去学真正通用的动作规律。
实验里能明显看到效果:没加这套机制时,一个简单的线性模型就能100%分清数据来源;加了之后,区分准确率跌到了50%左右,和瞎猜差不多,说明模型真的学会了“透过现象看本质”。
2►真本事:在机器人上实测的三大突破
这套方法好不好用,最终得看机器人的表现。

研究团队让机器人执行多项操控任务,以借助任务导向人类数据评估其少样本学习能力、语言指令跟随能力及鲁棒性。
团队在Unitree H1和G1两款人形机器人上,测了单目标抓取、多目标抓取、汉堡组装、倒水四个任务,还特意设置了“见过的场景”(分布内)和“没见过的场景”(分布外),结果Human0的表现超出了预期:
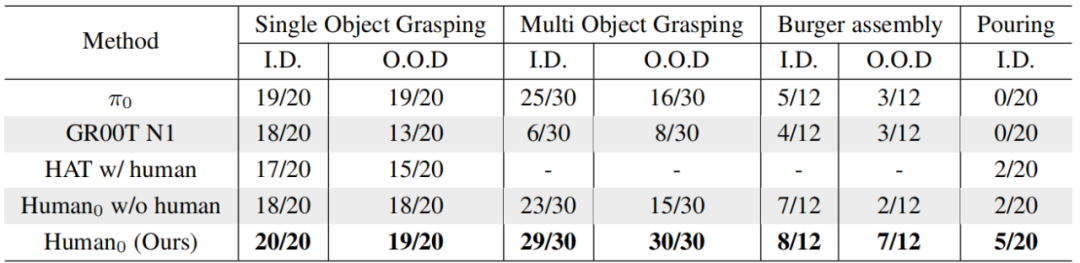
基准模型对比结果。在四项操控任务中,无论处于分布内(I.D.)还是分布外(O.O.D.)场景设置下,研究团队提出的方法在所有基准模型中均实现了最优性能。研究结果还表明,利用大规模人类数据进行训练可有效提升模型性能。
能听懂“没听过”的指令
之前的机器人模型,只能懂训练时见过的指令。但Human0不一样——它从人类数据里学了大量语言和动作的对应关系,就算指令没在机器人训练数据里出现过,也能照做。
比如多目标抓取任务里,让它“抓黄色芥末瓶”,这个指令只在人类数据里有,机器人从没练过,但它还是准确找到了瓶子;汉堡组装时,要它“用夹子夹马苏里拉奶酪”,奶酪和夹子的组合也是第一次见,它照样能完成操作。
学新活只需要1个演示
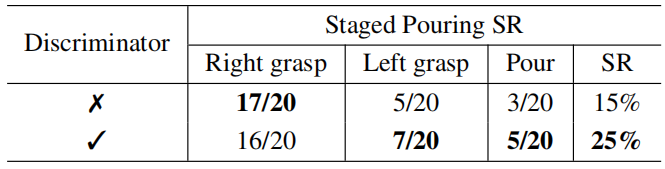
研究团队以倒水任务为对象,开展了域自适应技术的消融实验。倒水任务是一项具有挑战性的双手协同任务,可细分为3个阶段。文中报告的成功率(SR)为组合成功率。
对完全没接触过的任务,Human0也不用反复教。比如倒水这种需要双手配合的活,之前的模型没练过就完全不会,但Human0只看1个演示视频,就能有25%的成功率,虽然不算高,但已经比其他基线模型的0成功率强太多了。这意味着以后让机器人学新任务,不用录几十上百个演示,成本大大降低。
换场景也不会“懵”
汉堡制作时,用了没练过的红卷心菜、瑞士奶酪,成功率也从基线模型的25%涨到了58.3%。
3►为什么这很重要?
这篇研究不只是做出了一个好模型,更重要的是给行业提供了一套可复用的方法论:
从数据上,它明确了“野生数据打基础、任务数据做精修”的思路,解决了“量”和“质”的矛盾;从技术上,统一表征和域自适应的组合,打通了人类和机器人之间的“能力迁移通道”;从应用上,模型能懂新指令、学新活,意味着机器人不用再针对每个场景单独训练,落地速度会快很多。
现在团队已经计划开源PHSD数据集、模型权重和重定向工具,以后其他研究团队也能用上这套方法。或许用不了多久,我们就能在餐厅、工厂里,看到像人一样灵活又“聪明”的人形机器人了。
项目地址:https://xiongyicai.github.io/In-N-On/
论文链接:https://arxiv.org/pdf/2511.15704

推荐阅读





×
右键可直接复制图片