
 阅读时间大约8分钟(3183字)
阅读时间大约8分钟(3183字)
2025-11-26 高校数采进入生死竞速!如何抢占具身智能数据战“最后的窗口期”?
来源:豆包
来自物理世界的多模态交互数据,已成为驱动范式跃迁的“新石油”。
作者: 李文泉 出品:机器人产业应用
在人工智能的浪潮奔涌向“具身智能”新纪元的当下,数据,特别是来自物理世界的多模态交互数据,已成为驱动范式跃迁的“新石油”。对于高校而言,2025年并非建设“数采工厂”的生死大限,但无疑是抢占下一代人工智能数据战略制高点的最佳、也可能是最后的窗口期。
此时,高校“数采工厂”的内涵已发生根本性演变:它不再是传统的数据标注车间,而是必须升级为融合真实物理交互、多模态数据采集与处理的“具身智能数据反应堆”。其紧迫性在于,一旦领先企业已验证工业级数据生产的规模化与盈利模型,高校将彻底丧失先发优势与构建独特生态位的机遇。
核心要点
• 战略窗口期
• 高校的升维竞争战略
• “数据反应堆”的深远意意义
01
战略窗口期:三大动因解析为何2025-2026年是关键抉择点

1. 技术拐点已至:数据需求从“量”到“质”的范式革命
大模型技术正经历从“纯虚拟”向“具身化”的历史性演进。这一“具身化”跃迁,使得过去依靠互联网爬取获得的文本、图像等“平面数据”捉襟见肘。训练一个能在复杂现实环境中工作的智能体(如家庭服务机器人、),需要的是多模态时序同步数据:不仅是高清视频,还包括高精度三维点云、多维力/力矩传感信息等。这类数据的采集、校准、清洗和标注,技术复杂度极高,成本呈数量级增长。这远非单个实验室零散采集所能胜任。这个技术拐点,催生了对专业化、体系化“数据反应堆”的刚性需求。
2. 政策红利明确:数据要素市场格局初现,标准制定者将主导未来
国家数据局等高层次机构已开始发布高质量数据集典型案例,此举标志着国家层面正在积极规范和引导数据要素市场的发展。在此窗口期,那些能够率先建立起高质量、高可信度数据生产流程的机构,将极有可能深度参与甚至主导未来具身智能数据在格式、质量、安全、隐私和伦理等方面的国家标准乃至国际标准的制定。
3. 产业需求爆发:专业化分工加速,数据供应链壁垒正在形成
下游产业的迫切需求是最强大的驱动力。工业、医疗、家庭服务等领域对具身智能解决方案的渴求,正强力倒逼上游数据供应链的成熟与专业化。帕西尼感知的“超级数据工厂”宣布其年产上亿条数据的目标,以及国家层面推动的“白虎数据集”等标杆项目,都清晰地表明:一个专业化、工业化的数据生产市场正在形成。高校若不能迅速建立起与之对标甚至更具前瞻性的能力,将被排除在核心数据供应链之外。
02
高校的升维竞争战略:从“数据工厂”到“数据反应堆”的三大差异化路径
面对企业在资本、效率和市场化速度上的压倒性优势,高校的胜算绝不在于进行一场“数据吨位”的军备竞赛。
其不可替代的核心竞争力,在于聚焦并放大其在数据生产的“质”(可信可靠与科学价值)、“序”(基础架构与标准规范)与“源”(前沿场景与交叉学科源泉)上的独特优势。这一定位需要通过以下三大差异化路径来实现:
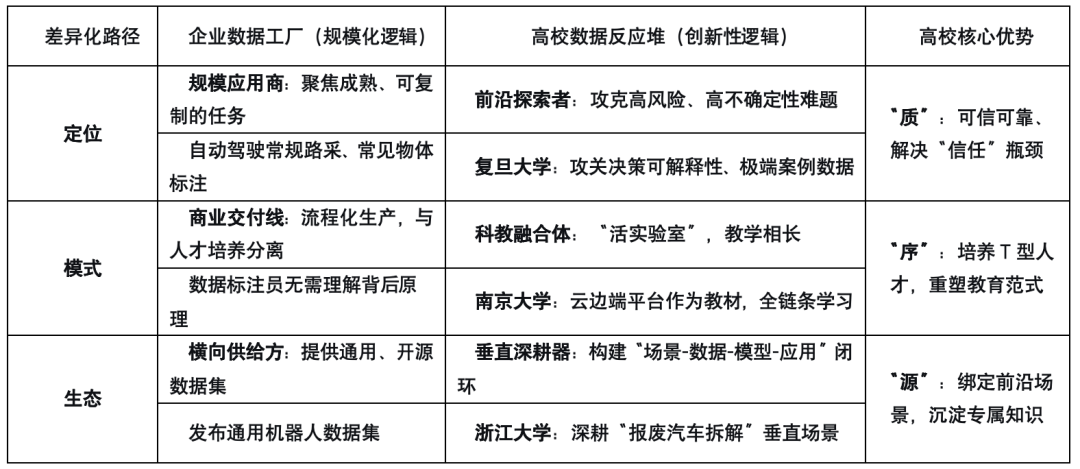
1. 定位差异:深耕“无人区”——前沿探索者 vs. 规模应用商
企业的商业逻辑天然驱使它们聚焦于需求明确、场景成熟、可快速复制和规模化的数据生产任务,例如自动驾驶的常规路采数据、常见物体的图像标注数据。其核心追求是成本的降低和交付效率的提升。
高校的使命则要求它成为探索数据“无人区”的先锋。它应主动攻克那些高风险、高不确定性、短期内看不到商业回报,但对长远技术发展至关重要的前沿数据采集难题。
复旦大学“可信具身智能研究院”将“数据引擎”作为其五大支柱方向之一,其雄心不在于生产海量通用数据,而是要解决具身智能的“信任”瓶颈。例如,如何采集和构建能验证智能体决策可解释性的数据集?如何设计实验来获取智能体在极端 corner case下的失败数据,并以此提升系统的鲁棒性?这些研究产出的是“数据的标准与方法论”,是为整个行业构建可信赖的基石,其战略价值远高于单一的数据集本身。
2. 模式差异:打造“活实验室”——科教融合体 vs. 商业交付线
企业的数据工厂是高度流程化的生产车间,其运作模式与人才培养体系是相对独立的。一个数据标注员无需理解数据背后的机器人学原理。
高校的“数据反应堆”则必须是一个巨大的、沉浸式的“教学相长”的实验场。它将数据生产的全过程,无缝嵌入到人才培养和科学研究中。
南京大学“具身智能联合创新实验室”所构建的云边端一体化平台,其本身就是一部活的教材。学生在这里不仅要学习如何编写算法,更要亲手部署和校准传感器阵列,理解不同材质表面对触觉数据的影响,设计数据采集协议以最小化通信延迟,并最终在云端训练和评估模型。这个过程培养的是贯通软硬件、兼具理论深度与工程实现能力的T型人才。
这种深度融合的、以真实数据生产全过程为核心的教学模式,是任何商业机构无法提供也无法复制的核心教育价值,也是高校人才培养范式的根本性变革。

3. 生态差异:构建“创新闭环”——垂直深耕器 vs. 横向供给方
企业的商业模式倾向于提供相对通用的、开源的数据集,以满足最广泛的市场需求。其数据与最终特定场景的模型优化之间,关系往往是松散的、一次性的。
高校的最大优势在于其能够深度绑定特定前沿场景,构建“场景-数据-模型-应用”的快速迭代闭环。这种闭环能在垂直领域内形成深厚的知识积累和数据壁垒。
浙江大学与天奇股份的联合实验室,其目标并非生产所有工业机器人都能用的通用数据,而是聚焦于“报废汽车拆解”这一极其复杂和不确定的特定场景。研究人员需要深入拆解现场,针对生锈螺栓的强力拧卸、线束的视觉识别与柔性抓取等具体任务,设计专用的数据采集方案。随后,用这些“专而精”的数据训练模型,再将模型部署到现场机器人上进行测试,产生的失败案例又形成新的数据,用于模型的迭代优化。
这个持续的、紧密的闭环,不仅催生了针对性的技术解决方案,更在此过程中沉淀了一套关于该垂直领域的、独一无二的、极具科学价值和商业价值的专用数据集与知识体系。这是高校科研产生深远影响的绝佳模式。
03
“数据反应堆”的深远意义:重塑高校在智能时代的核心功能
投资建设这样一个“数据反应堆”,其回报将远超一个科研平台本身,它将成为重塑高校在智能时代核心功能的战略支点。
1. 重塑人才培养范式:从“算法工程师”到“智能体架构师”
它培养的不再是仅会调参的算法工程师,而是能理解物理世界约束、能设计传感系统、能处理多模态信号、能将抽象任务转化为具体数据需求的“智能体架构师”。这是数字世界与物理世界融合背景下,对未来工程师的根本性重塑。
2. 赋能前沿科研攻关:从“追随热点”到“开创方向”
它能为机器人学、认知科学、人工智能等学科提供独一无二的、高质量的专属数据集。拥有这些数据集,高校研究者就能提出独一无二的科学问题,而非只能在企业开源的数据集上做追随性研究。这将是从“发表论文”到“定义研究方向”的关键一跃。
3. 掌握标准与规则的话语权:从“参与者”到“仲裁者”
通过在数据可信度、安全性、伦理审查等方面建立严苛的内部标准,高校有望成为行业信赖的“数据质量认证中心”。未来,当社会讨论具身智能的伦理边界时,高校基于其严谨数据和研究得出的结论,将成为制定公共政策和行业规范的重要依据,从而占据道德和学术的制高点。
4.打造产学研融合“引力中心”:从“项目合作”到“生态共生”
一个先进的、充满活力的“数据反应堆”将成为最强的“创新磁石”。它将吸引的不是寻求短期项目合作的企业,而是渴望与高校共同定义未来、开展前瞻性探索的行业领袖。双方的关系将从简单的“甲方-乙方”升级为“创新共同体”,共同投资于不确定的未来,共享知识产权,共育高端人才。
04
避免“数据空心化”,争做“规则共商者”
展望未来,如果高校在此轮以具身智能为代表的数据基础设施竞争中行动迟缓或彻底缺位,将面临致命的“数据空心化”危机。这意味着,最具价值的、反映世界最新动态的、驱动核心算法迭代的“活数据”的生产资料,将高度集中于少数巨头企业手中。高校的研究将不得不依赖于企业开放的、经过商业和隐私过滤的、带有固有偏见的“二手数据”。这不仅会丧失科研的自主性与前瞻性,更将在根本上动摇人才培养的独立性与批判性思维。
因此,当前行动的紧迫性与核心,不在于焦虑地观望企业入场后是否还有生存空间,而在于必须以时不我待的紧迫感,抢在企业形成不可撼动的数据垄断之前,充分利用高校独有的学术公信力、跨学科整合能力以及对顶尖人才与青年的吸引力,快速建立起在数据质量、标准制定和前沿探索上的权威与领导力。
当企业全面主导应用市场时,高校的理想角色不应是落寞的旁观者或无力的竞争者,而应是基础科学问题的提出者与探索者、核心数据标准与伦理规范的共同制定者、以及能够驾驭整个软硬件复杂系统的顶尖人才的摇篮。
总而言之,2025-2026年,是高校为即将到来的具身智能时代,奠定其不可或缺的数据基石与创新地位的“最后”也是最佳的机会。这不仅关乎一时的科研产出,更关乎在未来智能社会中,高校能否继续扮演知识创新灯塔与社会责任守护者的关键角色。

推荐阅读





×
右键可直接复制图片