
 阅读时间大约8分钟(2814字)
阅读时间大约8分钟(2814字)
2025-12-15 英伟达重磅成果!无遥操、无真机数据!人形机器人仅凭仿真开门,比人类还快31.7%!
来源:豆包
研究团队在IsaacLab仿真平台中,构建了大规模的程序化生成管道,从物理和视觉两个维度进行全方位随机化。
作者:李鑫 出品:具身智能大讲堂
当人形机器人能完成后空翻、武术动作时,一个看似简单的日常任务——开门,却长期困扰着业界。这个需要精准感知、接触控制与全身协调的动作,成为检验机器人自主能力的"试金石"。如今,英伟达联合加州大学伯克利分校、卡内基梅隆大学等机构的研究团队,终于攻克了这一难题。

研究团队推出的DoorMan系统,仅凭RGB视觉输入,就能让人形机器人在真实世界中灵活应对各种类型的门,不仅成功率超越人类操作员,完成速度更是快出23.1%-31.7%。
1►三大核心技术:破解Sim-to-Real迁移难题
DoorMan的成功,得益于一套"教师-学生-自举"学习框架,以及大规模的仿真随机化技术,从根本上解决了视觉迁移、长时序训练和部分可观测性三大核心挑战。
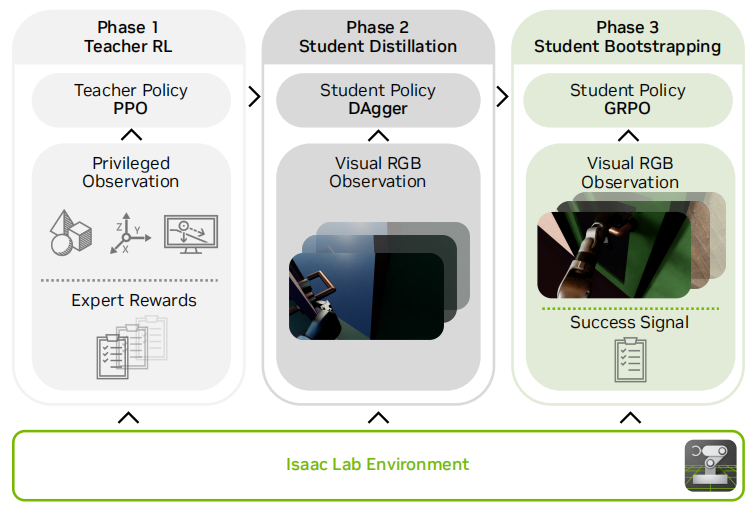
DoorMan 训练流程。所有阶段均在 IsaacLab 中交互式完成
1. 教师-学生蒸馏:从特权观测到纯视觉感知
研究团队采用了经典的教师-学生蒸馏范式,但进行了针对性优化。在仿真环境中,"教师"策略可以获取人类无法直接观察到的"特权观测"——包括机器人与门的相对位置、手部与门把手的姿态关系、手部接触力数据等。借助这些信息,教师策略通过近端策略优化(PPO)算法,在分阶段奖励机制的引导下,快速掌握开门的核心技能。

而"学生"策略则完全模拟真实世界的约束,仅依靠RGB图像和本体感受数据进行决策。为了让学生能继承教师的能力,研究团队使用DAgger算法进行交互式蒸馏:将视觉编码器提取的图像特征与本体感受特征融合,通过LSTM网络捕捉时序信息,再经MLP输出关节角度指令。这种方式相比传统的行为克隆,能更好地覆盖学生的输入分布,确保在纯视觉条件下依然能精准复现教师的操作逻辑。
值得注意的是,整个策略运行频率达到50Hz,采用的神经网络架构兼顾了性能与效率,确保机器人能实时响应环境变化。同时,系统基于预训练的全身控制器构建,无需从零开始学习腿部运动,大大降低了训练复杂度。
2. 分阶段重置探索:解决长时序训练瓶颈
开门这类长时序任务的训练,很容易陷入"难以推进到后期阶段"的困境。例如,机器人可能学会了接近门,却始终无法精准抓住门把手;即使抓住了,也可能因旋转方向错误或身体平衡控制不当而失败,进而导致策略"遗忘"已掌握的技能。

阶段重置探索方案概述:进入新阶段时,仿真快照会被缓存至缓冲区;任务重置时,通过从缓冲区加载数据,环境会随机重置到之前的某个阶段。
为解决这一问题,研究团队设计了分阶段重置探索策略。他们将开门任务分解为六个连续阶段:走向门、预抓取、抓取、开门、门摆动、穿过门。当机器人成功进入下一个阶段时,系统会缓存此时的仿真快照(包括机器人姿态、门的状态等)。在训练重置时,环境会以一定概率随机加载之前缓存的中间阶段快照,而不是每次都从初始状态开始。
这种设计相当于给训练过程"搭梯子",让策略能更频繁地接触到任务的后期阶段,显著提升了长时序信用分配的效率。实验显示,当缓存大小为100时,教师策略在1700次迭代内就能覆盖所有阶段;而没有缓存时,策略甚至无法进入抓取阶段,训练直接失败。
3. GRPO微调:弥补部分可观测性缺口
纯视觉感知必然面临部分可观测性问题——例如门把手被遮挡、相机角度偏移等情况,都会导致学生策略无法获取关键信息。为了让策略具备自我改进能力,研究团队在蒸馏之后加入了GRPO(Group Relative Policy Optimization)微调阶段。
GRPO是一种无价值函数的PPO变体,通过分组轨迹得分估计基线,能有效稳定长时序行为。在微调过程中,系统仅使用二元成功信号(是否成功开门)和简单的正则化奖励(如关节速度惩罚、动作平滑性惩罚),引导学生策略自主发现补偿策略。实验发现,经过GRPO微调后,学生策略会主动调整身体姿态,确保门把手始终保持在相机视野中,或通过调整末端执行器姿态来维持可见性——这些行为都是教师策略从未展示过的,完全是策略自主学习的结果。
4. 大规模仿真随机化:构建真实世界的"数字孪生"
要实现从仿真到现实的无缝迁移,关键在于让仿真环境足够多样化,覆盖真实世界的各种可能情况。研究团队在IsaacLab仿真平台中,构建了大规模的程序化生成管道,从物理和视觉两个维度进行全方位随机化。

用于训练 DoorMan 的程序化生成门,涵盖门板设计、锁存机制、照明、材质等多种属性。每个并行环境均基于一组独特的门参数进行训练,最后一张图展示的是无材质的门。
物理随机化涵盖了5种门类型(包括旋转把手推门、旋转把手拉门、推杆门等),并对门的尺寸、把手位置、铰链阻尼、把手阻力矩等关键参数进行随机采样。特别地,系统还模拟了真实的门锁机制,精准还原了开门瞬间的动力学突变。
视觉随机化则更为全面:使用基于物理的渲染(PBR)材料库随机生成表面纹理,加载5233种穹顶光纹理模拟不同时间、不同场景的光照条件,同时轻微随机化相机的内参和外参,模拟机器人运动时相机的自然抖动。这些设置完美复现了真实世界中光照变化、材质差异等复杂情况,为视觉迁移提供了坚实基础。
值得强调的是,仿真环境并未刻意复刻任何真实场景,所有用于测试的真实门都是策略从未见过的,这确保了测试结果的客观性和策略的泛化能力。
2►实测性能:超越人类操作员的自主开门能力
为了全面验证DoorMan的性能,研究团队在仿真和真实世界中进行了多维度测试,不仅与人类操作员进行直接对比,还通过消融实验验证了各核心模块的必要性。
1. 真实世界表现:成功率与效率双超人类
测试采用Unitree G1人形机器人,配备7自由度三指灵巧手,仅使用Intel RealSense D435i相机的RGB输出(禁用深度功能),策略推理运行在搭载RTX 4090 GPU的工作站上。人类操作员分为专家(3个月以上全职经验)和非专家(1天以内经验),使用VR头显和操纵杆进行远程控制,与自主策略使用相同的全身控制器。

所有开门任务的平均性能:左图为成功率(数值越高越好);右图为任务流畅度(以完成开门任务的耗时衡量,数值越低越好)。
测试结果显示,DoorMan在真实世界中的成功率达到83%,超过专家操作员的80%和非专家的60%;在任务完成效率上优势更为明显——比专家快23.8%,比非专家快31.7%。从定性表现来看,人类操作员常常难以准确判断门把手的弹簧力和门的铰链阻力,容易出现操作节奏混乱、身体失衡等问题;而DoorMan能精准控制施力大小和身体姿态,始终保持平稳的开门速度,展现出更优的操作流畅性。
在三种不同类型的门上,DoorMan均表现稳定:最简单的旋转把手推门任务成功率最高,而难度最大的反向拉门任务也能保持80%以上的成功率,充分证明了其泛化能力。
2. 消融实验:核心模块的关键作用
为了验证各技术模块的必要性,研究团队进行了系统的消融实验:
•视觉随机化的影响:完全不进行视觉随机化时,任务成功率仅为5%-20%;仅使用纯色随机化(无纹理)时,成功率提升至65.8%-70%;而加入100%纹理随机化和光照随机化后,成功率达到81%-86%。这表明高保真的视觉随机化是实现Sim-to-Real迁移的关键。

打通人形机器人像素到动作策略迁移的仿真到现实之门
•GRPO微调的价值:蒸馏后的初始学生策略成功率仅为50%-70%,经过GRPO微调后,学生策略成功率提升至80.8%-85.8%,基本接近教师策略的水平,证明了微调阶段对弥补部分可观测性缺口的重要作用。

DoorMan 训练进度:(a) 学生策略的 GRPO 自举优化;(b) 不同阶段重置缓冲区大小下的教师策略探索。
•分阶段重置的效果:当缓存大小为100时,教师策略能在1700次迭代内覆盖所有阶段;缓存大小为10时,需要4000次以上迭代;无缓存时则无法完成训练。这充分说明分阶段重置能显著提升长时序任务的训练效率。
3►结语与未来:
DoorMan的核心价值在于证明了:通过大规模仿真随机化和高效的强化学习框架,纯视觉驱动的人形机器人能够实现复杂的长时序操作任务,且性能可以超越人类远程操作。未来,研究团队计划减少对任务特定奖励工程的依赖,利用大容量行为克隆教师,进一步提升策略的通用性,并将该框架扩展到更多日常全身交互任务中。
论文地址:https://arxiv.org/pdf/2512.01061

推荐阅读





×
右键可直接复制图片