
 阅读时间大约8分钟(3086字)
阅读时间大约8分钟(3086字)
2025-12-29 北大重磅推出ManualVLA模型!长程精细任务成功率直线飙升!
来源:豆包
该模型在乐高组装和物体重排等长时程任务中,平均成功率比现有最佳方案高出32%。
作者:李鑫 出品:具身智能大讲堂
当我们对着一堆乐高积木想要拼出复杂造型,或是需要把杂乱的物品按指定方式摆放时,大脑会自然地拆解步骤、规划动作,先拼哪个部件、先放哪个物品,每一步都有清晰的逻辑。但对机器人来说,这种需要长期规划的复杂任务一直是巨大挑战。
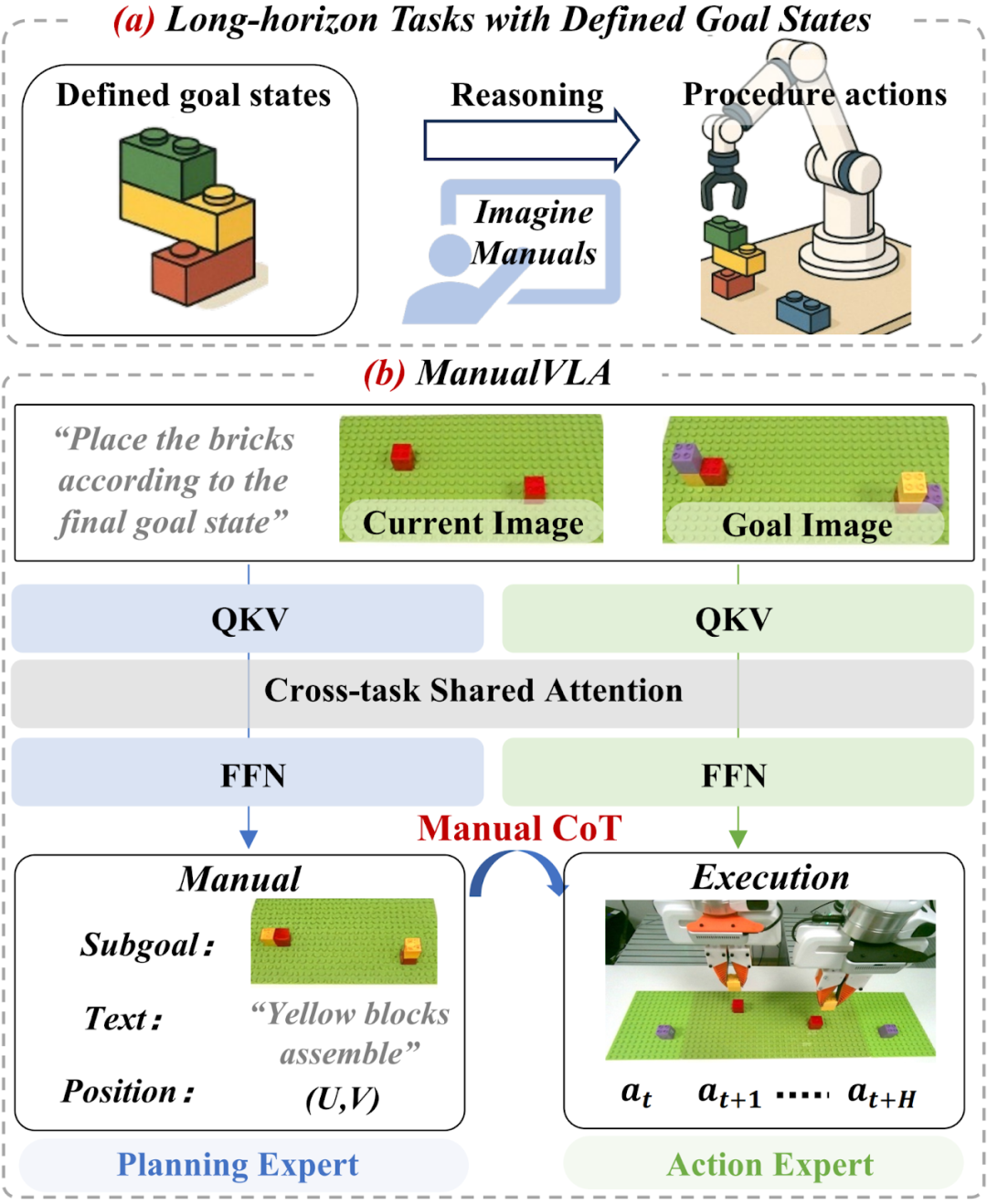
ManualVLA模型概述。(a) 具有预定义目标状态的长时程任务(如乐高组装或物体重排)对智能机器人构成重大挑战,这类任务不仅要求机器人能够构想流程手册,还需基于该手册执行精确操作。(b) 为解决这类任务,研究团队提出了 ManualVLA—— 一种基于混合 Transformer(MoT)架构构建的统一视觉 - 语言 - 动作(VLA)模型。该模型通过设计的手册链式思维(Manual Chain-of-Thought)机制,实现了多模态手册生成与动作生成的协同工作。
近日,北京大学联合香港中文大学、至简动力的研究团队提出了一种名为ManualVLA的VLA模型,成功让机器人具备了类似人类的"规划-执行"能力。该模型在乐高组装和物体重排等长时程任务中,平均成功率比现有最佳方案高出32%,目前该研究成果已发表在arxiv预印本上。
1►ManualVLA模型给机器人配"规划师"和"执行者"
近年来,基于互联网规模预训练的VLA模型在机器人场景理解和简单操作中表现亮眼,能够在实验室外的环境中展现出一定的泛化能力。但当面对需要明确目标状态的长时程任务时,这些模型就显得力不从心了。
以乐高组装为例,机器人不仅要精确按照最终造型完成拼接,还要在整个过程中协调长期规划与精细操作,同时适应真实世界中的各种变化。现有方案要么依赖大量人类演示视频或手工编写的操作手册,导致泛化能力不足;要么直接将感官输入映射到动作,缺乏中间的推理环节,难以应对复杂任务的步骤拆解。
人类之所以能轻松完成这类任务,核心在于能够从最终目标反向推导中间过程,将复杂任务分解为连贯的子目标步骤。研究团队正是看到了这一点,提出了一个关键问题:能否让VLA模型也具备这种能力,从"要做什么"(what)推导出"该怎么做"(how),将预设的最终目标转化为一系列可执行的精确步骤?
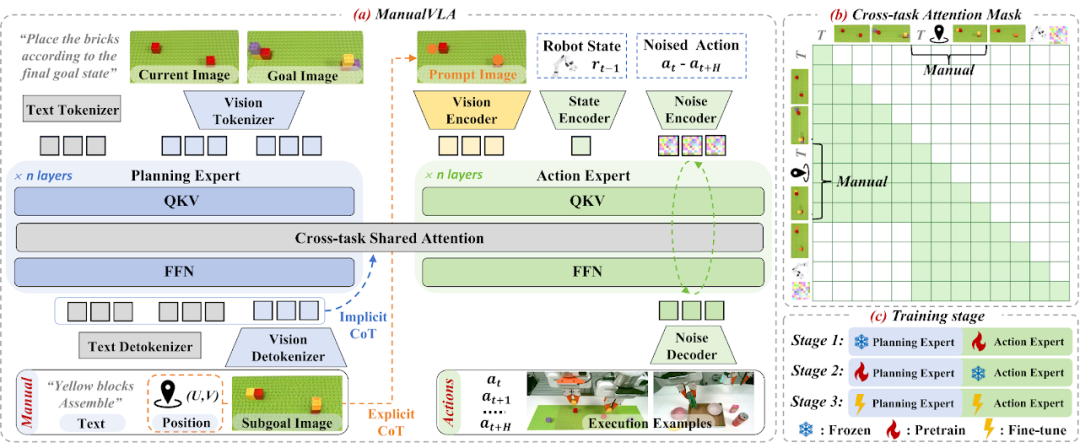
(a)为完成具有明确目标状态的长时程任务,研究团队提出了 ManualVLA—— 一种基于混合 Transformer(MoT)架构构建的统一视觉 - 语言 - 动作(VLA)模型。该框架包含两个专家模块:负责生成多模态操作手册的规划专家,以及负责预测精确动作的动作专家。规划专家对人类指令、当前场景图像和最终目标图像进行处理,生成包含下一步图像、位置信息和子任务指令的中间操作手册。研究团队引入了显式链式思维(CoT)推理过程,其中每个位置指示器都作为视觉提示,嵌入到动作专家的观测信息中。(b)结合跨任务共享注意力机制与设计的注意力掩码,生成的操作手册令牌还被用作动作生成的条件信号,实现了能够有效引导动作专家的隐式链式思维(CoT)推理过程。(c)ManualVLA 采用三阶段训练策略,使规划专家与动作专家实现对齐,从而达成高效协同工作。
为了解决这个问题,研究团队设计了ManualVLA模型,其核心架构基于混合Transformer(MoT),通过"规划专家"和"动作专家"的协同工作,实现了多模态操作手册生成与动作执行的有机统一。
2►双专家架构:分工明确,协同高效
ManualVLA的架构设计模拟了人类完成复杂任务的思维模式,将整个过程拆分为"规划"和"执行"两个核心环节:
•规划专家:负责将最终目标转化为中间操作手册。这个手册可不是简单的文字说明,而是包含了子目标图像(展示下一步该达成的状态)、目标位置提示(精确到像素级的(U,V)坐标)和文本指令(说明该操作的核心任务)的多模态信息集合。通过这种方式,规划专家为后续动作提供了清晰的"执行蓝图"。
•动作专家:基于规划专家生成的操作手册,生成精确的机器人控制信号。它不仅能利用手册中的位置坐标信息,还能通过潜在表示获取隐式指导,确保动作的准确性和连贯性。
3►ManualCoT推理:让每一步动作都有依据
为了让动作专家能充分利用规划专家生成的手册,研究团队提出了Manual Chain-of-Thought(ManualCoT)推理过程,包含显式和隐式两种推理方式:
•显式推理:将规划专家预测的目标位置坐标叠加到当前场景图像上,形成提示图像,直观地告诉机器人"该操作哪个物体"以及"放到哪里",相当于给机器人一个视觉导航标记。
•隐式推理:在模型的潜在空间中,操作手册作为动作建模的条件信号,先明确"操作对象",再指定"放置位置",最后提供"预期效果",形成连贯的逻辑链条,引导机器人做出合理动作。
4►数字孪生工具:解决数据匮乏难题
训练规划专家需要大量的中间步骤数据,但手动收集这类数据成本极高。为此,研究团队基于3D高斯溅射技术开发了高保真数字孪生工具包,能够自动生成训练所需的操作手册数据。
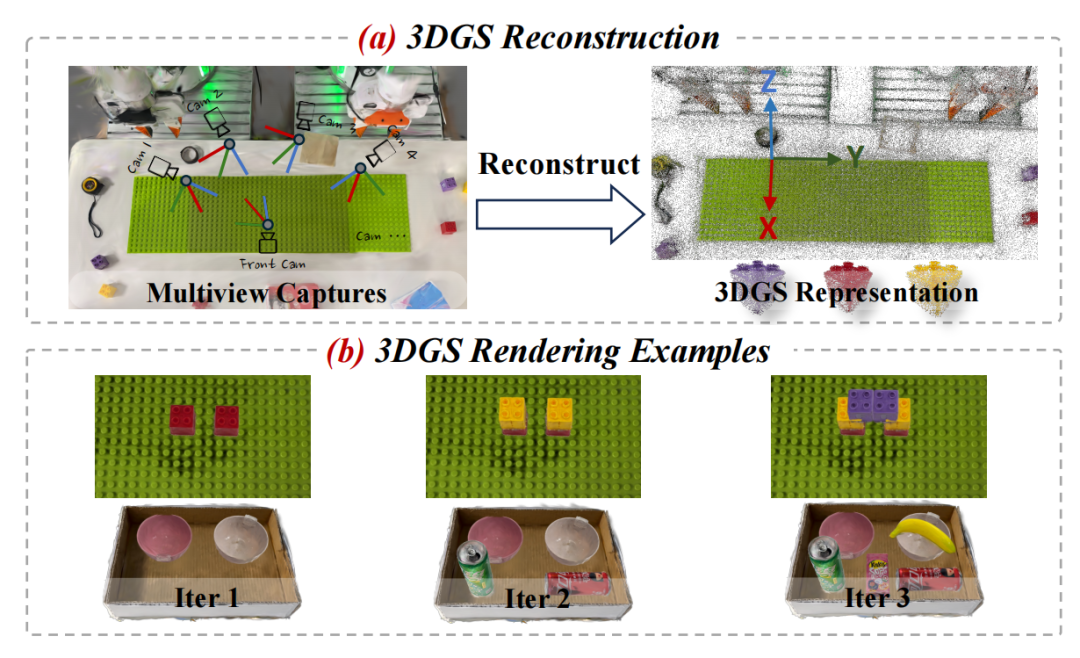
数字孪生示例。(a)研究团队先重建 3D 高斯溅射表示,随后将其分解为乐高基板和单个积木块。(b)研究团队通过迭代方式将积木块放置在基板上,或把物体放置到盒子中。
这个工具包首先通过多视角拍摄重建出乐高积木、放置板等物体的3D资产,然后在虚拟环境中迭代放置物体,自动生成每个中间步骤的照片级真实图像、位置信息和文本描述。通过这种方式,无需人工标注就能为每个任务生成超过10000帧的高质量训练数据,大幅降低了数据收集的负担。
5►实测表现:成功率碾压现有方案,泛化能力突出
研究团队在双机械臂Franka平台上进行了三项核心任务测试:2D乐高组装、3D乐高组装和物体重排,同时与π₀、π₀.₅、FAST、CoT-VLA等多种主流VLA模型进行了对比。
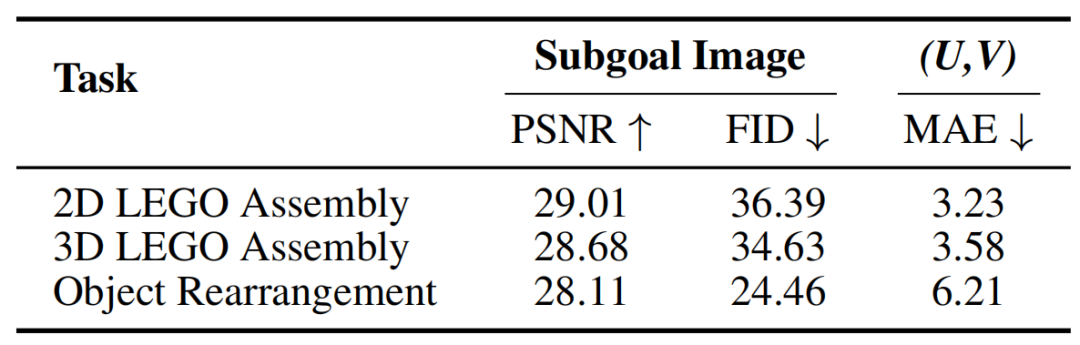
ManualVLA 在三项下游任务中子目标图像及(U,V)坐标生成的定量结果
核心任务表现亮眼
在2D乐高组装任务中,ManualVLA的最终成功率达到85%,而最强的分层基线模型仅为60%;在3D乐高组装任务中,ManualVLA以65%的成功率大幅领先于基线模型的35%;在物体重排任务中,它的成功率也达到65%,超过基线模型15个百分点。
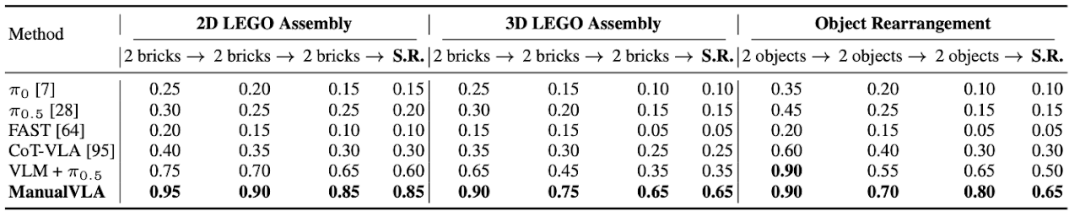
ManualVLA 与基线模型的对比。研究团队采用 20 个未见过的测试目标状态,报告了完整长时程任务的操作成功率(S.R.),同时补充报告了关键中间步骤的成功率。
从中间步骤的表现来看,现有基线模型往往在任务初期表现尚可,但随着步骤推进,误差不断累积,成功率大幅下降。而ManualVLA通过合理的任务拆解和精确的动作控制,在整个任务过程中都保持了稳定的高成功率,展现出强大的长时程任务处理能力。
泛化能力经得起考验
除了在标准场景下的优异表现,ManualVLA还展现出了出色的泛化能力。当面对未见过的物体形状、背景环境和光照条件时,它的性能仅出现小幅下降:在2D乐高组装任务中,背景变化时成功率从85%降至65%,形状变化时降至60%,光照变化时降至70%,而对比基线模型在这些情况下的性能下降更为明显。
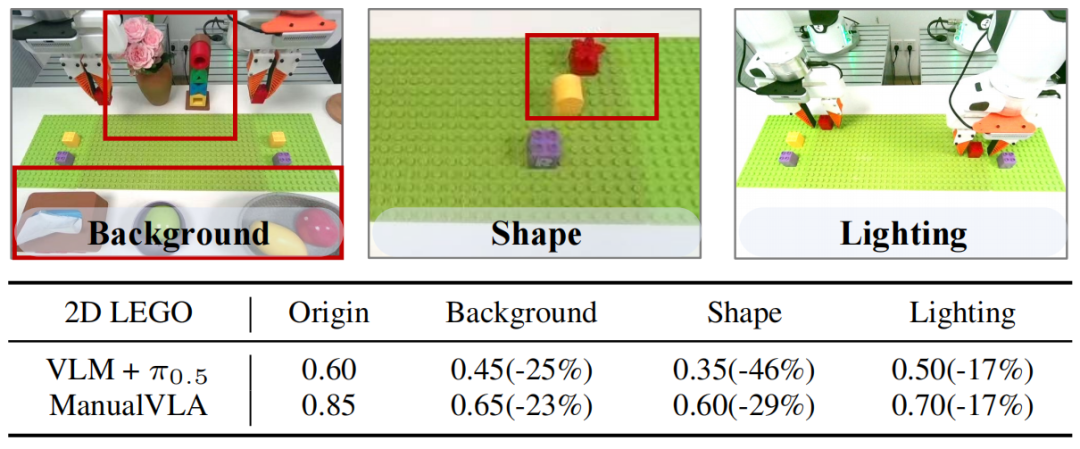
泛化性。研究团队在背景、物体形状和光照条件变化的情况下,通过 20 次滚动测试,报告了每项任务的平均成功率及性能下降比例。
这得益于数字孪生工具包提供的多样化训练数据,以及ManualCoT推理机制带来的鲁棒性,让模型能够适应真实世界中的各种变化。
通用任务同样胜任
在RLBench基准测试的10项通用操作任务中(包括关盒子、关笔记本电脑、扫地入箕、浇花等),ManualVLA平均成功率达到70%,分别比π₀和CoT-VLA高出7%和11%,在扫地入箕、取出雨伞等需要精确动作的任务中表现尤为突出,证明它不仅擅长长时程复杂任务,在常规操作任务中也具备很强的竞争力。
6►技术细节:三阶段训练,兼顾效率与性能
ManualVLA采用三阶段训练策略,确保规划专家和动作专家能够协同工作并达到最佳性能:
1.动作专家预训练:在包含40万条轨迹的大规模跨载体数据集上进行预训练,让动作专家掌握基本的操作技能,训练目标为预测噪声与真实噪声的均方误差。
2.规划专家预训练:使用数字孪生工具包生成的数据集训练规划专家,让其学会生成高质量的多模态操作手册,采用交叉熵损失函数进行监督。
3.联合微调:收集100条真实场景下的演示数据,对整个模型进行联合微调,让规划专家和动作专家更好地协同工作,最终损失函数为规划损失和动作损失之和。
7►结语与未来:
ManualVLA的核心突破,在于让机器人具备了从最终目标反向推导操作步骤的能力,通过多模态操作手册和链式推理,将复杂任务拆解为可执行的中间步骤,解决了长时程任务中规划与执行脱节的关键问题。
不过尽管ManualVLA模型任务表现出色,但目前仍存在一些局限性尚未被解决,比如在乐高组装任务中偶尔会出现积木放置错误,在物体重排任务中面对大旋转角度时可能失败。这些问题主要源于训练数据中极端情况的缺失,未来可以通过扩充这类场景的数据来改进。
从更长远来看,研究团队希望进一步提升模型的通用性,让其能够处理更多类型的复杂任务,同时优化模型效率,降低计算成本,推动通用机器人在日常生活和工业场景中的实际应用。
论文链接:https://arxiv.org/abs/2512.02013
项目地址:https://sites.google.com/view/maunalvla

推荐阅读





×
右键可直接复制图片