
 阅读时间大约6分钟(2101字)
阅读时间大约6分钟(2101字)
2025-12-31 导航成功率 70.7%!上海人工智能实验室提出DualVLN,重新定义机器人视觉语言导航
来源:豆包
让机器人像人类一样,结合视觉信息和语言指令自主导航。
作者:Alex 出品:具身智能大讲堂
当你向机器人下达“去拿桌上的水杯”这样的指令时,它需要完成一系列复杂操作:看懂语言指令、识别周围环境、规划移动路线、避开动态障碍物,最后精准抵达目标。这就是视觉语言导航(VLN)的核心任务——让机器人像人类一样,结合视觉信息和语言指令自主导航。
近年来,随着大型视觉语言模型(VLM)的崛起,机器人导航的智能化水平大幅提升,但一个根本矛盾始终存在:模型越强大,思考越慢;而现实世界需要的是快速、流畅且安全的实时行动。
近期,来自上海人工智能实验室的研究团队提出了 DualVLN,以“慢思考、快行动”的双系统架构破局,它模仿人类思维模式,将高层的语义推理与底层的运动控制解耦,让机器人既能深思熟虑地规划长远路径,又能敏捷灵活地应对突发障碍。这套方案不仅在多项权威基准测试中刷新纪录,更在真实环境中展现出应对复杂场景的超强能力,为机器人从实验室走向现实生活铺平了道路。
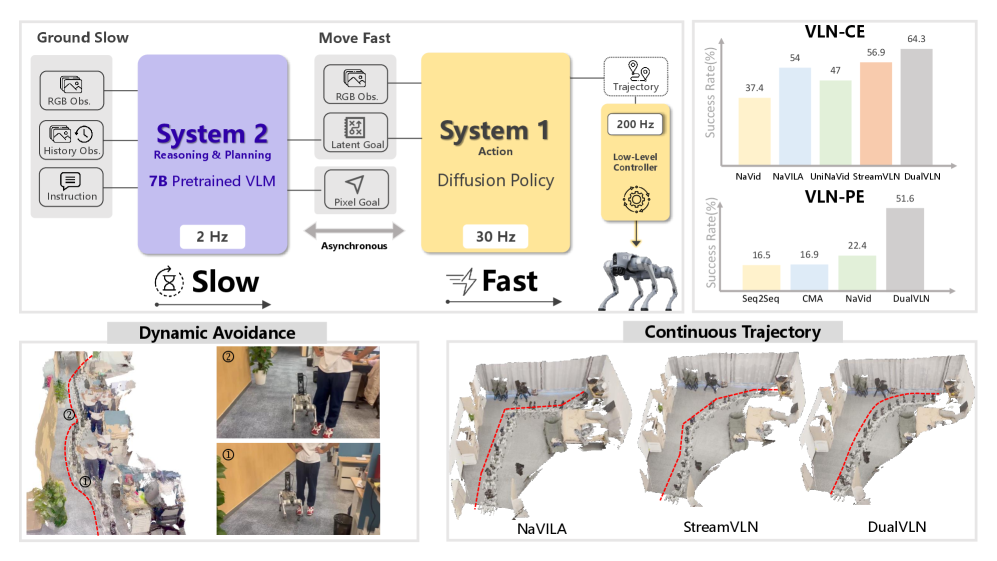
提出的双系统框架将高层推理与低层控制分离
1►DualVLN的双核分工:一个定方向,一个管执行
DualVLN的核心创新,在于解耦了高层语义推理与低层运动控制,打造出两个各司其职又协同工作的系统:慢速思考的System 2和快速行动的System 1。这两个系统异步运行,既保证了导航的准确性,又兼顾了实时性。
System 2是基于VLM模型Qwen-VL-2.5构建的全局规划器,它的核心任务是根据语言指令和视觉信息,锁定距离当前位置最远的、可见的目标点——这个点就是机器人下一步要抵达的“航点”。比如指令是“去阳台”,它会在图像中找到阳台的位置,标记出一个二维像素坐标,作为前进的方向指引。
如果机器人的视角太高或太低,目标点可能会被遮挡;如果机器人面朝错误方向,目标点甚至不在视野范围内。这时,System 2会自动执行“左转15度”“低头15度”等离散动作,调整到最佳视角后,再确定目标点。这个设计解决了“看不到目标就无法规划”的难题,让机器人的决策更灵活。

System 1是一个轻量级的扩散变换器策略模型,它的核心任务是把System 2给出的像素目标,转化为平滑、连续的运动轨迹。
System 1的工作,离不开两个关键的“输入信号”。一是System 2提供的显式像素目标,也就是图像中标记的航点;二是通过“潜在查询”提取的隐性潜在特征——这些特征来自VLM的隐藏层,包含了语言指令、历史轨迹等丰富的语义信息。
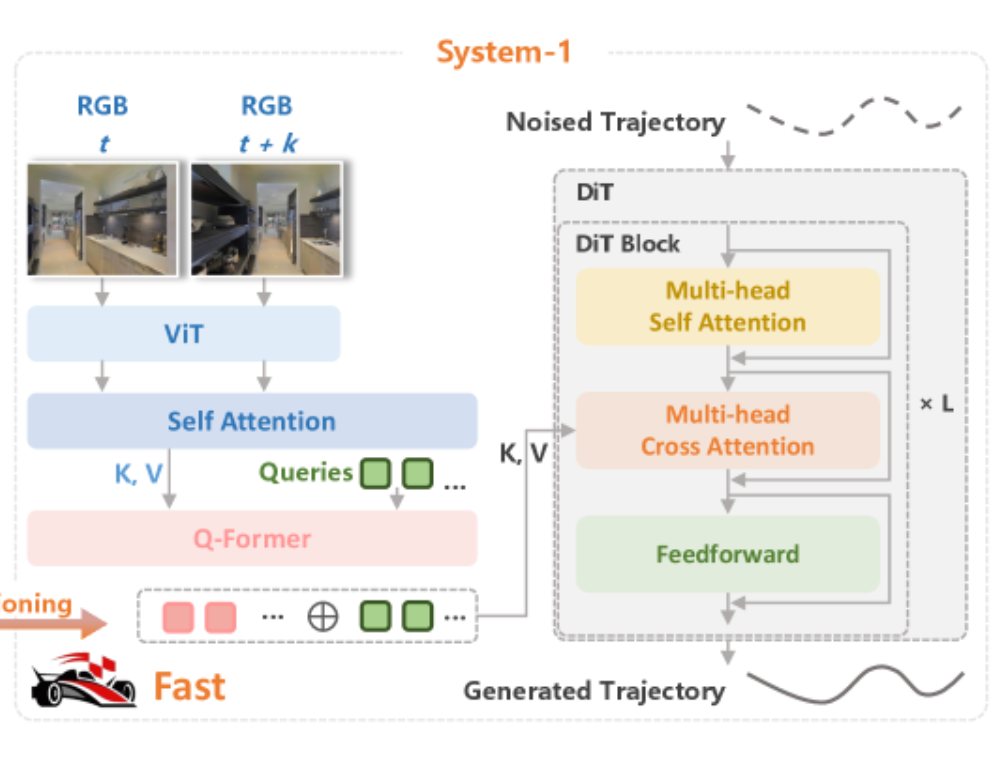
这两个信号的结合,让System 1的轨迹生成能力远超传统模型。它能输出包含32个密集路径点的平滑轨迹,引导机器人一步一步走向目标。更重要的是,System 1和System 2是异步工作的:当System 2还在计算下一个航点时,System 1可以基于已有的目标信息,持续生成轨迹。这种设计让机器人的运动不再卡顿,实现了“边规划、边行走”的流畅体验。
解耦训练:让两个系统“专精所长”
DualVLN的另一个巧妙设计,是解耦训练机制。在训练过程中,研究团队会先训练System 2,让它掌握全局规划能力;然后冻结System 2的权重,再训练System 1,让它学会将目标转化为轨迹。
这种训练方式的优势十分明显:System 2可以接触大量的多源推理数据,保持强大的泛化能力——换一个新环境、换一条新指令,它依然能准确规划;System 1则专注于低层控制,只需要少量目标数据就能训练成熟,而且运算速度快、延迟低,适合实时部署。
2►实验验证:多维度测试的优异表现
为验证DualVLN性能,研究团队开展了多维度测试,结果显著优于主流模型。
模拟环境测试:刷新基准纪录
研究团队在VLN-CE和VLN-PE两大导航基准开展测试。VLN-CE模拟室内静态导航场景,核心衡量目标到达准确性;VLN-PE贴近现实场景,纳入机器人动力学与控制误差,侧重评估导航稳健性。在VLN-CE的R2R和RxR数据集上,仅依赖单视角RGB输入的DualVLN,显著超越多传感器融合模型及基于VLM的端到端模型,导航误差(NE)降至4.05,成功率(SR)提升至70.7%,各项核心指标刷新现有纪录。在VLN-PE基准测试中,即便未针对该场景轨迹微调,DualVLN的下落率与卡住率仍远低于基线模型,展现出极强的稳健性。
创新Social-VLN基准:适配动态行人场景
针对现实中机器人需应对动态行人的需求,研究团队提出Social-VLN新基准。该基准基于R2R-CE数据集,融入Habitat 3.0模拟的类人生物,通过让“行人”随机出现在导航轨迹上,评估模型的社会意识与避障能力。测试显示,动态环境虽导致所有模型性能下降,但DualVLN仍保持领先优势,不仅导航误差更低、成功率更高,人与碰撞率(HCR)也维持在低水平,可在避让行人的同时保障目标导向性。

Social-VLN 基准的典型场景示意图
真实世界测试:跨平台稳健适配
为验证实际应用能力,研究团队在轮式(Turtlebot4)、四足(Unitree Go2)、人形(Unitree G1)三类机器人上开展实地测试。测试设备配备RGB-D摄像头,连接搭载RTX 4090显卡的远程服务器,覆盖走廊、卧室、办公室等不同复杂度场景。结果显示,DualVLN在所有场景中均实现高成功率与低导航误差,可有效应对桌椅避让、行人规避、楼梯通行、振动等复杂路况。依托异步推断与TensorRT加速技术,System 1生成32条轨迹仅需0.03秒,保障导航的实时性与流畅性。

消融实验:验证核心设计必要性
消融实验结果证实,显式像素目标与隐性潜在特征对系统性能均不可或缺:移除像素目标会导致潜在特征失去方向指引,移除潜在特征则无法利用VLM语义信息,均会造成性能显著下降。同时发现,System 1具备低数据需求特性,仅使用System 2收集的1%轨迹数据即可实现较好性能,数据量提升至10%时性能接近饱和,降低了训练成本,利于大规模部署。
3►结语
DualVLN 为视觉语言导航技术提供了全新思路,其双系统设计不仅解决了传统端到端模型的碎片化动作、高延迟、弱避障等问题,更搭建了语义推理与运动控制之间的衔接桥梁。传统导航模型多存在精准规划与实时执行难以兼顾的问题,而 DualVLN 通过 System 2 保障语义理解与目标定位准确性,System 1 保障运动控制的稳健性与实时性,实现了两者的协同优化。
该设计为具身智能的落地应用拓展了空间,未来搭载 DualVLN 的机器人有望应用于家庭服务、物流配送、医院导诊等场景,实现自然语言指令理解与复杂动态环境下的稳健导航。

推荐阅读





×
右键可直接复制图片