
 阅读时间大约8分钟(2981字)
阅读时间大约8分钟(2981字)
2026-01-14 Cell Rep. Med.见刊发表!龙尔平/万沛星团队发布大模型“圆桌会议”框架MCC 大幅提升医疗推理能力
来源:豆包
医疗AI从 “单点智能” 向 “协同推理” 实现范式跃迁。
作者:李鑫 出品:具身智能大讲堂
在医学人工智能飞速发展的当下,GPT-4、Med-PaLM 2 等大型语言模型在医学问答与考试任务中持续刷新纪录,展现出逼近人类的认知水平。然而,单一模型固有的“黑箱”局限,以及缺乏多视角校验的推理机制,已成为其在真实、高风险临床场景中安全落地的核心瓶颈。如何让 AI 复刻多学科专家会诊的模式,实现交叉质证与协同决策,是医疗 AI 迈向可信、可靠阶段必须跨越的科学鸿沟。

2026 年 1 月 5 日,中国医学科学院基础医学研究所龙尔平团队与北京大学基础医学院万沛星团队,在《Cell Reports Medicine》期刊在线发表题为《Model confrontation and collaboration: a debate intelligence framework for enhancing medical reasoning in large language models》的研究论文。该研究提出 “模型对抗与协作”(MCC)框架,推动医疗 AI 从 “单点智能” 向 “协同推理” 实现范式跃迁;通过构建可辩论、可追溯、动态协作的模型圆桌,从根本上助力医疗 AI 向可靠、可解释、可协作的下一代形态演进。
1►三阶段解析MCC框架中模型对抗与协作机制
研究团队提出“模型对抗与协作”(Model Confrontation and Collaboration, MCC)框架,核心是将不同厂商的大型语言模型组建为动态圆桌智囊团,通过“推理—行动—反思”的闭环交互提升医疗推理的精准度与可靠性。为保障协作效果,框架专门设计“共享上下文工作区”(shared context):把问题本身、各模型生成的候选答案、关键证据点及立场变化,以结构化形式纳入统一记忆空间,且每轮辩论全程保留完整对话历史,确保所有批判与修正都基于同一事实与语境,避免认知偏差。
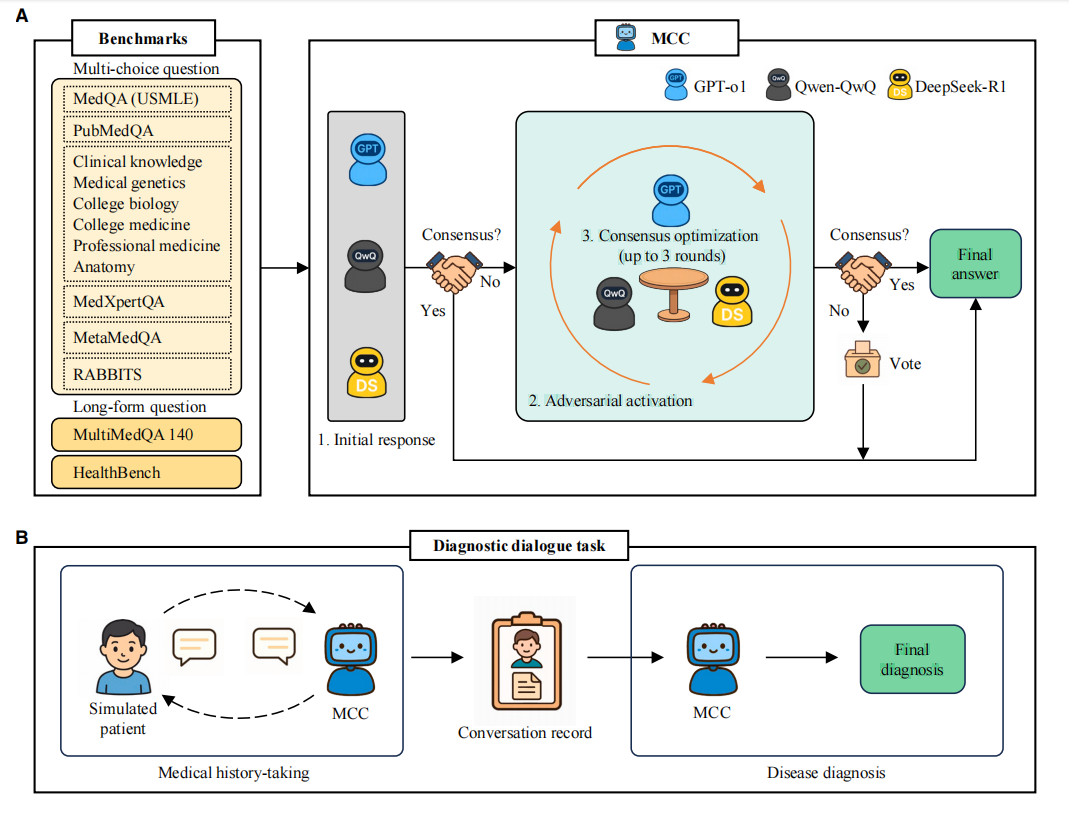
MCC 框架:模型对抗与协作机制解析
MCC框架的核心流程分为三个阶段,首先是独立推理(Reason)阶段,框架选取GPT-o1、Qwen-QwQ、DeepSeek-R1三款不同厂商的先进模型,针对同一医疗问题同步生成答案及关键论证点,保证初始观点的多样性与差异性。随后启动分歧门控(Gate)机制:由系统/主持LLM检测三款模型候选答案的一致性,仅当答案存在分歧时才激活后续辩论,从源头控制额外计算成本,提升运行效率。
进入对抗辩论(Debate as Action)阶段后,模型间开展多轮消息交互,每一轮均围绕“质疑—举证—反驳—修正”四类核心动作推进。各模型聚焦共享上下文中的证据缺口、推理断点开展交叉验证:精准找出对方论证中的逻辑跳步、证据不足或概念混淆问题,补充临床指南、病理机制、鉴别诊断依据等关键信息支撑自身观点;同时进行自我反思,全面核查自身推理链与核心假设,最终以可解释的方式更新立场与结论。
共识优化(Consensus Optimization)阶段遵循“早停原则”:每轮辩论结束后立即判定是否达成共识,若模型观点一致则终止流程并输出结果;若经过最多三轮辩论仍未达成共识,就采用多数投票作为保底输出方案。
相较于传统“静态集成/硬投票”方案,MCC框架的核心优势在于把多模型的互补性转化为“基于上下文的迭代纠错”协作过程——利用异构模型在知识覆盖范围、推理逻辑偏好上的差异,精准定位错误、对齐证据,最终提升复杂难题场景下的结论收敛质量与输出稳定性。
2►全场景性能碾压单模型 多项指标刷新纪录
MCC 在各类医学基准测试中表现出压倒性优势,多项指标刷新纪录、稳居 SOTA 水平。经典测试中,MedQA 基准(1273 道题)上 MCC 达到 92.6%(±0.3)的平均准确率,超越 Med-Gemini 此前保持的 91.1% 的最佳纪录,大幅领先于单个模型(GPT-o1 为 84.8%、Qwen-QwQ 为 81.8%、DeepSeek-R1 为 89.7%)和专业医疗模型 Med-PaLM 2(86.5%),且多次独立运行中均展现出稳定表现;PubMedQA 基准中,其 84.8% 的准确率同样超越 MDTeamGPT 的 83.9%,持续领跑。MMLU 医学子集中,它覆盖遗传学、解剖学、临床知识等多个科目,整体准确率维持 90% 以上,其中五个科目更是斩获 SOTA,在医学遗传学领域准确率高达 99.7%,充分彰显跨领域推理能力。
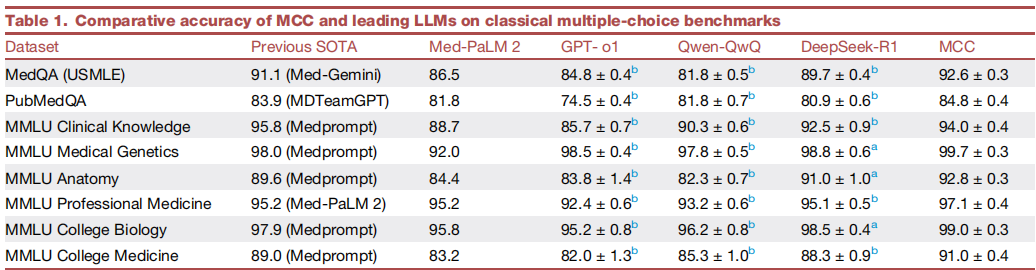
MCC与主流大语言模型在经典多项选择基准测试中的准确率对比
值得关注的是,面对初始存在分歧的题目,MCC 的迭代修正能力尤为突出。254 个存在争议的 MedQA 题目中,经过多轮辩论,MCC 最终为 94.9% 的题目提供了正确答案 ——GPT-o1 修正了 82.4% 的初始错误,Qwen-QwQ 修正率为 55.7%,DeepSeek-R1 修正率为 30%。这种高效自我修正源于不同推理路径的碰撞,正确推理往往能获得更多证据支撑,而错误观点则在多方质疑中被逐步摒弃。

MCC 在 MedQA 基准上的表现与决策动态
即便在 “更难、更接近真实临床风险” 的评测中,MCC 依然保持稳健表现。专家级推理测试 MedXpertQA 上,它在推理题和理解题上分别取得 40.2% 和 40.1% 的准确率,远超 GPT-4o(分别为 30.6% 和 29.5%)等主流模型,在该基准对比评测中位居前列;MetaMedQA 测试中,MCC 不仅实现 84.1% 的整体准确率,还能精准识别不确定或无明确标准答案的情形,给出 “未知 / 需补充信息” 的保守处理,体现出更强的元认知边界管理能力,其缺失答案召回率达 75.7%,表现优于所有对比模型。此外,RABBITS 鲁棒性测试中,面对药物商品名与学名的混用、替换等临床常见语言变体,MCC 的准确率下降幅度仅为 0.5%-0.6%,远低于单个模型 2%-3% 的降幅,充分证明其在复杂临床场景中的泛化能力与稳定性。
3►长文本问答与诊断对话评测 综合回答水平更高
长文本问答任务中,研究团队采用 MultiMedQA 基准,并邀请 10 名执业医师与 10 名普通测试者开展双视角盲评,全面评估模型在真实医疗咨询中的综合表达与建议能力。
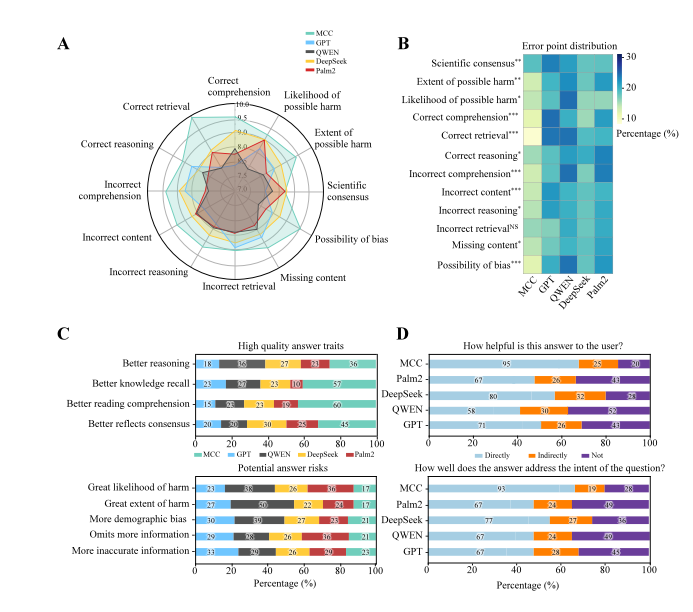
开放式医学问答输出的多维度评估
结果显示,MCC 在所有维度上均优于 GPT-o1、Qwen-QwQ、DeepSeek-R1 以及 Med-PaLM 2:医生评审的 12 项指标中,MCC 在病情要点提取(提升 11.8%)、推理正确性(提升 8.8%)与偏差控制(提升 11.1%)等关键维度实现 8–12 个百分点的显著进步,且错误内容率更低;在另一组 9 项综合质量指标中,其缺陷率下降 3%–9%,一致性与知识覆盖更为稳定。
普通测试者评估中,MCC 的回答更具实用性和易懂性,以 “平衡失调可能是什么症状” 为例,单个模型回答各有遗漏:GPT-o1 忽略听神经瘤等鉴别诊断,Qwen-QwQ 未提及脊柱和环境因素,DeepSeek-R1 遗漏代谢和精神因素。而 MCC 整合所有合理成分,涵盖神经、耳鼻喉、代谢、心血管等多个领域,提供诊断建议和风险分层,还明确标注各知识点的来源模型,兼顾全面性和透明度。
进一步在 HealthBench 测试中,MCC 在与临床专家共识对齐的任务中取得 0.921 的综合评分,并在更高难度的 HealthBench Hard 子集(如复杂德语干细胞治疗咨询)中保持领先,即便面对需兼顾 regulatory 信息、风险枚举与循证替代方案的复杂要求,仍能通过多轮修正形成更安全完整的回复,体现出在复杂场景下的稳健性与安全性优势。
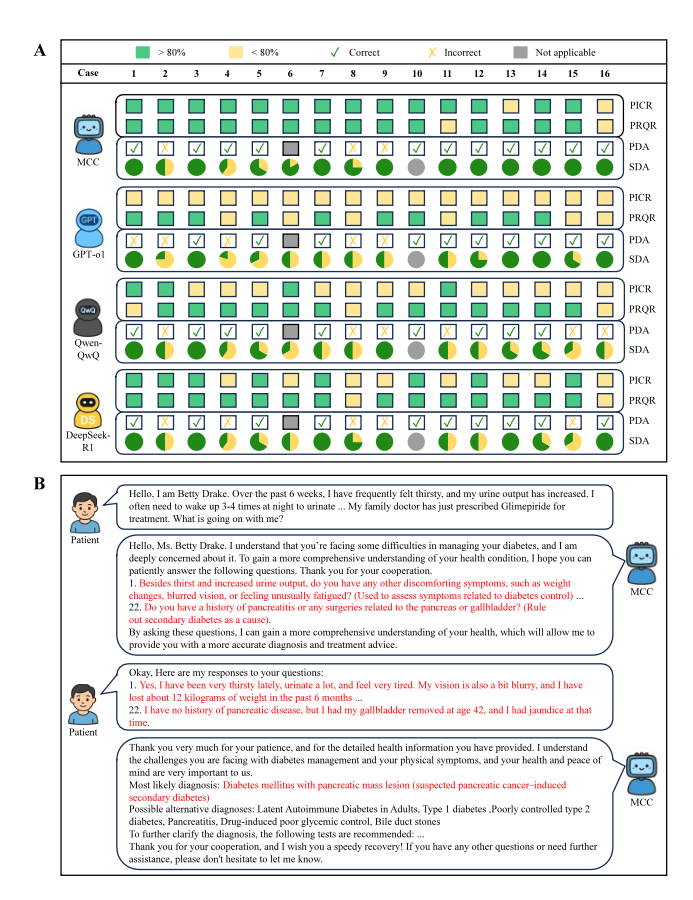
MCC在诊断对话任务中的表现
为评估 MCC 在交互式诊疗场景中的能力,研究团队构建了类医学院 OSCE 的模拟病例对话测试:模型作为医生与模拟患者实时交互,在完成病史采集后给出诊断与鉴别诊断。结果显示,MCC 在病史采集阶段平均可捕获 80% 以上的关键患者信息点;在 16 个病例中,有 14 例的信息捕获率(PICR)超过 80%,而 GPT-o1 无一达标,Qwen-QwQ 和 DeepSeek-R1 分别仅有 4 个和 8 个病例达标。
与此同时,MCC 提出的问题与患者主诉的相关性更高(多数病例 > 80%),提示其问诊路径更聚焦关键线索、减少无效提问。在诊断结论阶段,15 个可判定病例中,MCC 的首选诊断正确率达到 80%(12/15),并在鉴别诊断的完整性上显著优于所有单个模型 ——10 个病例中能准确识别全部支持性鉴别诊断,而 DeepSeek-R1、GPT-o1、Qwen-QwQ 分别仅能做到 6 例、5 例和 3 例。
典型案例中,一位 56 岁女性出现多饮多尿、乏力与体重下降,既往以 2 型糖尿病处理但血糖控制不佳。辩论过程中,模型间交叉质询促使补问胰腺相关病史与上腹痛向背部放射等线索,进而将诊断从 “糖尿病本身” 推进至 “胰腺肿瘤相关继发性糖尿病” 的更深层解释,这一关键诊断最初仅由其中一个模型提出,经多轮辩论补充证据后达成共识,充分体现出 “圆桌式会诊” 对关键线索召回与深入诊断推理的促进作用。
4►结语与未来:
研究证实,MCC框架可成为增强医疗推理能力的通用范式。无需引入额外任务训练与外部知识库,该范式借助结构化辩论,将不同模型在知识覆盖与推理偏好上的差异,显式应用于交叉核验、证据对齐与错误纠偏,进而提升复杂问题的推理收敛质量与输出稳定性。
值得强调的是,MCC 并非要替代医生,而是通过提供多角度论据与可追溯的辩论日志,帮助临床人员降低漏诊误判风险、提升决策透明度,同时还具备教学示范意义。面向临床应用,MCC 仍需推进多方面优化:实现与电子病历及检查结果的端到端集成,完善对不确定或冲突信息的处理策略,做好隐私合规与计算成本控制,确保其以安全、高效的方式融入真实医疗工作流。
该论文的共同第一作者为中国医学科学院基础医学研究所博士生孙欣提和洪奇阳,共同通讯作者为龙尔平研究员与北京大学基础医学院的万沛星研究员。
论文地址:https://www.cell.com/action/showPdf?pii=S2666-3791%2825%2900620-2

推荐阅读





×
右键可直接复制图片