 阅读时间大约9分钟(3273字)
阅读时间大约9分钟(3273字)
2026-04-14 给Ego数据加上触觉,然后呢?
来源:具身纪元
弥补感知盲区。
作者:Marilyn Liu 出品:具身纪元
机器人能看见世界,但它摸不到。
这个问题在第一视角(egocentric)数据集领域尤其突出——过去几年积累的大量人类操作视频,记录了手在画面里抓、拧、推、捏的全过程,却从来不知道手指哪个部位正在受力,力有多大,接触面积是什么形状。
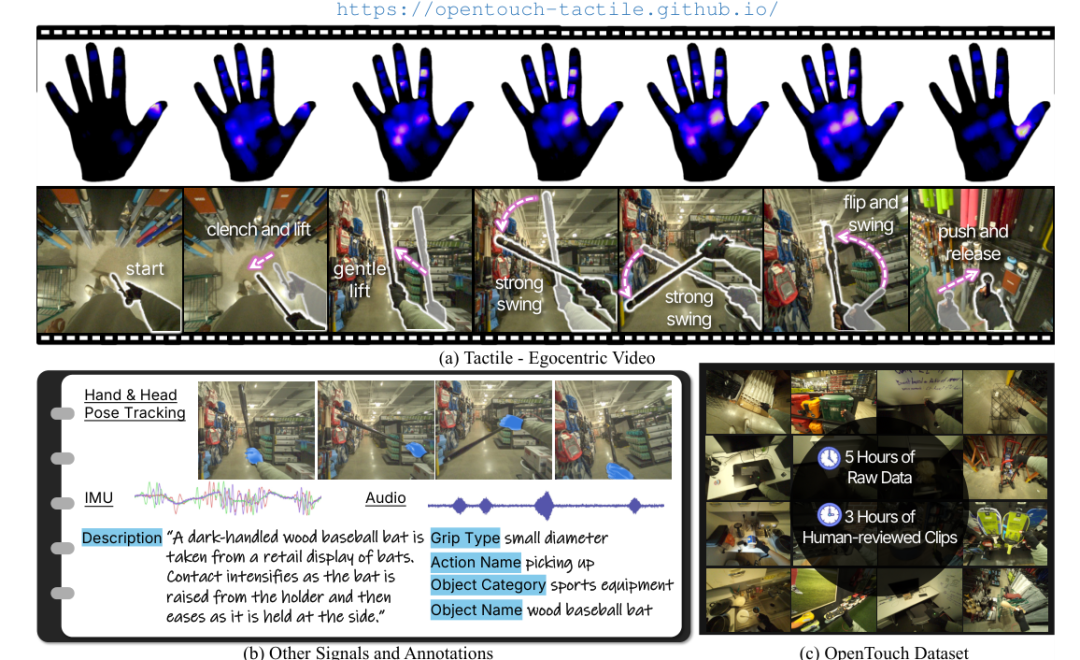
MIT 联合 Duke、Brown、University of Washington 和 Harvard 的团队提出了 OPENTOUCH,第一次把全手触觉、第一视角视频和手部姿态三路信号在真实日常环境中同步采集下来,试图补上这块最关键的感知盲区。
视觉能看见手在动,但看不见手在感受
想象一下闭着眼睛从口袋里掏钥匙。手指在摸索的过程中,靠的不是视觉,而是指尖和掌面传回的压力分布——哪里硌了一下,哪里滑了一点,哪里卡住了。
这种信息在现有的 egocentric 数据集里完全缺失。

OPENTOUCH 数据集概览:同步采集第一视角视频、全手触觉和手部姿态
已有的触觉数据集要么局限在实验室里、对象数量极少,要么依赖热成像或固定压感垫,无法穿戴到手上在野外自然采集。而那些有运动学数据的方案,又往往没有触觉。
真正能做到"可穿戴、全手覆盖、野外自然采集、还能和视频及手部姿态严格时间同步"的数据,在 OPENTOUCH 之前几乎是空白。
这也不是一个锦上添花的问题。对于抓握理解、接触建模、灵巧操作策略学习来说,触觉是核心输入而非辅助通道。
没有它,模型只能猜手和物体之间发生了什么。
真正缺的不是另一台相机,而是手上的那层感觉
论文里有几组例子特别能说明问题。
同样的手势,看上去几乎没变,但触觉图已经能分出这一刻到底只是搭在物体上,还是已经施加了足够的力把椅子推走;面对透明量杯、手部部分出画、或者中指轻点按钮这种细微动作时,视觉不是完全没信息,但最关键的接触证据并不在画面里。

视觉难以判断的接触瞬间:受力、透明物体、出画动作和细小按压都能在触觉图里暴露出来
这也是 OPENTOUCH 最值钱的地方。它补的不是“更多画面”,而是视觉最难补的一层物理状态——接触有没有发生以及接触面在哪里?受力在怎么变化。
一只手套、一副眼镜、一套同步方案
OPENTOUCH 的硬件方案刻意追求低成本和可复现。
触觉采集部分,作者用 FPC(柔性印刷电路)布线夹住商业压阻薄膜,形成 16×16 电极网格,最终在手指和掌面上布置了169 个 taxels(触觉像素点)。这不是实验室里的定制 MEMS 阵列,而是一套开源、可自行组装的方案。
OPENTOUCH 硬件系统:触觉手套、Aria 眼镜与 Rokoko 手套的集成
手部姿态由 Rokoko Smartglove 捕获,单手 7 个 6-DoF 传感器,融合 IMU 与 EMF 信号,输出频率 30 Hz。
第一视角视频来自我们常说的Meta Project Aria 眼镜,RGB 分辨率 1408×1408,帧率同样 30 Hz。
三路数据的时序同步通过终端上的视觉提示完成,论文报告平均同步延迟约2 ms。对于 30 Hz 采样率来说,这个延迟基本可以忽略。
另辟蹊径的采集方案
数据采集的设计选择值得单独说。
作者没有让参与者照着预设动作列表操作,而是把他们放到14 个日常环境里——厨房、办公室、车库、洗衣房等——让他们自由操作现场已有的物体。
这个决定的代价是标注更难、数据更杂,但收益是交互模式的多样性远超实验室采集。最终数据集包含5.1 小时同步三模态数据、2,900 个人工审核片段、超过8,000 个物体、约800 个物体类别和29 类抓握类型。

OPENTOUCH 数据分布:环境、动作、抓握类型和对象类别的整体构成
标注层面,每个片段都有 object name、object category、environment、action、grasp type 和自然语言 description 六类标签。为了控制标注成本,作者没有把整段视频交给标注模型处理,而是围绕压力峰值采样三个关键时刻:峰值前最低压力帧、峰值帧、峰值后最低压力帧。
这是一个很巧妙的标注的方法,因为接触的时候其实才是关键帧到位的时刻。
用这三张 RGB-触觉对驱动 GPT-5 自动生成标签与描述,人工审核报告准确率约90%。主要失败场景集中在峰值时手离开画面、照明/遮挡复杂、以及三帧上下文不足的情况。
它到底在评测什么
论文的 benchmark 其实不是简单地问“触觉准不准”,而是在问三件更本质的事。
第一,视频和触觉之间能不能互相对齐。
第二,手部姿态和触觉之间能不能互相约束。
第三,当视频、姿态、触觉一起出现时,它们能不能形成比单模态更稳定的交互表示。
作者因此设计了 video↔tactile、pose↔tactile,以及多模态→单模态的检索任务,指标主要用 Recall@1/5/10 和 mAP。前者看 top-k 能不能捞对,后者看整个排序质量是不是靠谱。
跨模态检索:视觉和触觉之间到底能不能互相翻译?
论文围绕两类任务建立 benchmark:跨模态检索和分类。
检索任务的核心问题是:给定一段视频,能不能找到对应的触觉模式?反过来,给定一组触觉信号,能不能反推出当时的视觉场景?
基线方法包括 CCA(典型相关分析)、PLSCA(偏最小二乘相关分析)和一个 CLIP 风格的对比学习框架。
CCA是一种非常传统、简单粗暴的数学方法。它试图用最简单的“直线”(线性投影)来找“视频数据”和“触觉数据”的相关性;PLSCA它是 CCA 的一个改进版本。除了看数据之间像不像,它还会去抓取这两种数据在变化时的共同规律(最大化共享协方差)。
对比学习方法把线性基线甩开了一个数量级。视觉到触觉这种跨感官映射并非不可学。
尽管绝对数字还不高,但结果证明两者之间确实存在可学习的关联。
当视频和姿态同时作为查询去检索触觉时,mAP 从双模态的 15.47% 跳到了26.86%。视频提供场景上下文,姿态提供运动结构,两者合并后能大幅降低触觉预测的歧义。

跨模态检索定性结果:给视频找触觉,或者给触觉找视频,模型已经能捞到相当接近的接触模式
触觉不是万能模态,但在抓握理解上不可替代
分类实验进一步揭示了触觉的能力边界。
在抓握类型分类(grasp classification)上,三模态融合(触觉+姿态+视频)达到68.09%准确率,而纯视频只有 57.45%,纯触觉在 57.12%~60.23% 之间。触觉对抓握理解有不可替代的贡献——这符合直觉,因为抓握类型本质上由接触几何决定。
但在动作分类(action classification)上,情况反转了。纯视频达到40.26%,而三模态融合反而只有 35.02%~37.32%。
触觉在动作识别上不仅没帮忙,甚至可能引入了噪声。这个结果反过来界定了触觉的适用范围:它擅长局部接触理解,而非全局动作意图推断。
把触觉当成万能模态是危险的,它的价值在于补足视觉的接触盲区,而非替代视觉的语义理解。
OPENTOUCH 给出的答案更克制。触觉对抓握这种“手和物怎么接触”的问题帮助很大,但对动作这种“人在整体上想干什么”的问题,视觉仍然更像主轴。
时间窗口和编码器的消融:两个反直觉发现
时间消融实验显示,video→tactile 的 R@1 从 5 帧窗口的 5.77% 提升到 20 帧窗口的8.49%。在三模态检索中,这个提升更剧烈:从 6.57% 到12.82%。
接触不是一张静态图片,而是一个时间演化过程。只有看见施力的动态过程,跨模态对齐才能稳定。
编码器消融则给出了一个更反直觉的结论:在 tactile→pose 检索中,轻量级 Lite encoder 的 mAP 为16.76%,而更深更重的 ResNet-18 只有6.53%。触觉图不是自然图像,它是稀疏的、结构化的压力分布,盲目上大模型不仅没用,反而会破坏这种结构化模式的学习。
这个发现对后续触觉编码器的设计有直接指导意义。
换句话说,这篇论文顺手还回答了一个工程问题。做触觉表征时,不一定是“模型越大越好”。
对于这种低分辨率、强结构、弱纹理的信号,更贴近物理拓扑的轻量编码器,反而比沿用视觉时代那套重骨干更合适。
它甚至可以拿去给别的数据集补触觉
论文最后做了一个很有意思的应用:把在 OPENTOUCH 上学到的跨模态检索能力,拿去 Ego4D 这种没有触觉的大型第一视角视频数据上做 zero-shot retrieval。
给定一段 Ego4D 视频,模型会从 OPENTOUCH 的数据库里检索最相近的触觉序列;而作者再去看这些被检索出来的源视频,发现它们在手部运动和接触对象几何上,确实和查询视频非常接近。

零样本 Ego4D 触觉检索:没有触觉标注的视频,也开始能被配上一个相对可信的触觉候选
这一步很像给海量纯视频数据接上一层“伪触觉索引”。它当然还不是严格意义上的触觉预测,但已经让人看到一个更现实的扩展路径:先用少量高质量触觉数据学跨模态对齐,再把这种对齐能力迁到更大的视频语料上。
边界在哪里
OPENTOUCH 的局限性需要正视。
首先,数据只覆盖右手,总时长 5.1 小时。对于跨模态学习来说,这个规模只够验证可行性,离训练一个泛化的触觉基础模型还有距离。
其次,自动标注准确率约 90%,意味着每 10 个片段里大约有 1 个标签可能有误。在遮挡严重或手离开画面的场景下,三帧采样策略的信息量不足以支撑可靠标注。
第三,触觉传感器的空间分辨率(169 taxels)和动态范围仍然有限。对于需要精细力控的任务——比如区分纸张厚度或感知织物纹理——当前的硬件可能不够。
最后,论文的 benchmark 结果虽然显著优于线性基线,但绝对数字(如 R@1 约 7%)说明跨模态对齐仍处于早期阶段,距离实用还有很长的路。
基础设施比分数更重要
回到开头的问题:机器人能看见世界,但它摸不到。OPENTOUCH 没有解决这个问题,但它第一次证明了全手触觉可以在真实世界里规模化采集、自动标注,并用于跨模态学习。
从技术路线的角度看,这篇工作更像是给"能不能把手感数据做大"这个问题铺好了基础设施。它的贡献不在于某个 benchmark 上的绝对分数,而在于证明了三模态同步采集的工程可行性,以及触觉作为独立模态在抓握理解上的不可替代性
后续最值得关注的方向可能有两个:一是把数据规模从 5 小时推到 50 甚至 500 小时后,跨模态对齐的上限会不会显著提高;二是这套触觉数据能否直接迁移到机器人灵巧手的策略学习中,让 sim-to-real 不再只靠视觉和力矩反馈。
触觉这条路,刚刚铺下第一块砖。

推荐阅读





×
右键可直接复制图片