 阅读时间大约3分钟(962字)
阅读时间大约3分钟(962字)
2026-04-16 蚂蚁灵波开源LingBot-Map,突破实时空间感知技术瓶颈
来源:蚂蚁灵波
蚂蚁灵波开源LingBot-Map,仅靠普通摄像头即可实时理解三维世界。
4月16日,蚂蚁灵波科技宣布开源流式三维重建模型 LingBot-Map。该模型仅需一个普通RGB摄像头,即可在视频采集过程中实时估计相机位姿、重建场景三维结构,为机器人、自动驾驶、AR眼镜等应用提供连续、稳定、实时的空间感知与理解能力。

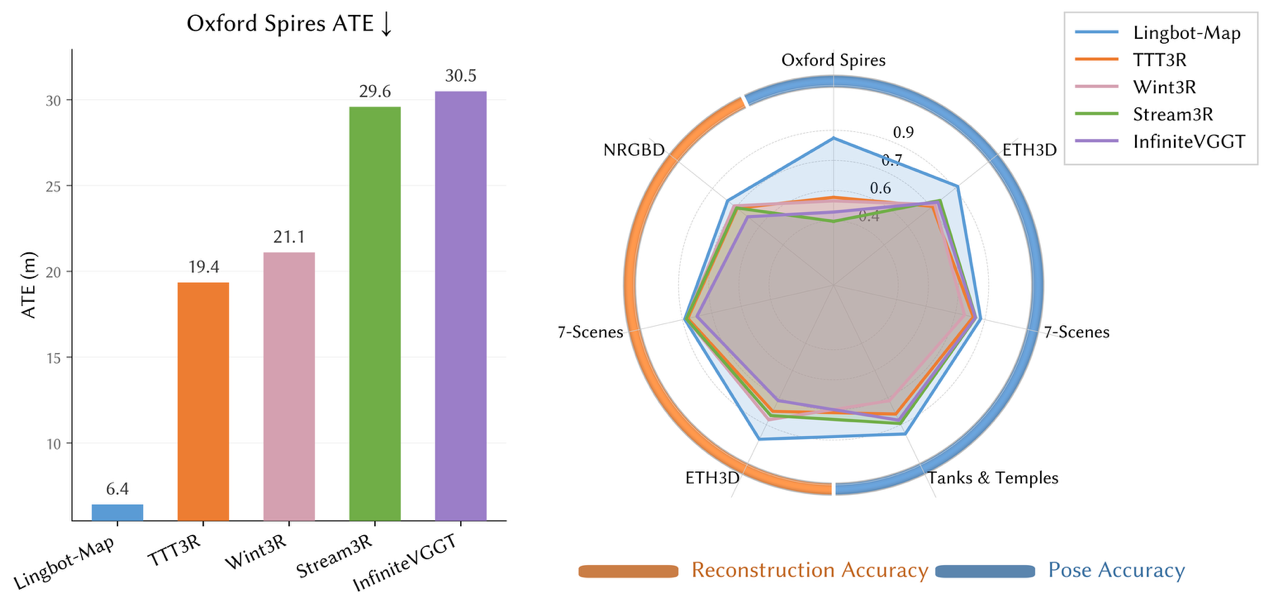
(图说:LingBot-Map 在多项国际主流评测中全面领先现有方法,是目前精度最高、稳定性最强的流式三维重建模型)
在以大尺度、复杂光照和严苛评估标准著称的Oxford Spires数据集上,LingBot-Map的绝对轨迹误差(ATE)仅为 6.42 米,轨迹精度较此前最优流式方法提升近 2.8 倍,也显著优于离线方法 DA3 的 12.87 米和优化方法VIPE 的 10.52 米。
在ETH3D、7-Scenes、Tanks and Temples等多个权威基准上,LingBot-Map在位姿估计和三维重建质量两个维度也全面领先现有流式方法。其中,在ETH3D基准上,其重建F1分数达到98.98,较第二名提升超过21 个百分点,展现出更强的场景还原能力。


除精度外,LingBot-Map 还兼顾实时性与长时稳定运行能力。技术报告显示,该模型可实现约 20 FPS 的推理速度,并支持超过 10,000 帧的长视频序列连续推理,且精度几乎保持不变。这意味着在机器人导航、避障、操作、交互等强调连续在线处理的真实场景中,模型具备在较长时间范围内稳定运行的能力。
流式三维重建是机器人和空间智能系统的重要底层能力。与传统三维重建方法在获取完整图像后再统一处理不同,流式三维重建强调“边看边理解”,系统需要一边接收新的画面,一边持续完成定位和建图,还要控制计算和存储开销。如何在几何精度、时序一致性和运行效率之间取得平衡,一直是流式三维重建的核心难点。
针对上述问题,LingBot-Map采用了面向流式场景的纯自回归式建模方式,基于几何上下文 Transformer,在不依赖未来帧信息的前提下,逐帧处理当前及历史画面,持续输出相机位姿和深度信息,实时恢复场景的三维结构。
LingBot-Map 的核心创新在于其几何上下文注意力(Geometric Context Attention,GCA)机制,能够对跨帧几何信息进行更有效的组织与利用,在保留关键历史信息的同时减少冗余计算。据介绍,该设计借鉴了经典 SLAM 系统对空间信息分层管理的思路,但将原本依赖手工设计和复杂优化的部分交由模型统一学习完成,从而更好兼顾长序列场景下的重建质量、运行效率与系统稳定性。
今年 1 月,蚂蚁灵波相继开源了高精度空间感知模型 LingBot-Depth、具身大模型 LingBot-VLA,世界模型 LingBot-World 和自回归视频-动作模型 LingBot-VA,围绕空间感知、具身决策、世界模拟等关键环节,不断夯实具身智能“智能基座”的技术布局。此次开源的 LingBot-Map,则进一步补齐了实时空间理解与在线三维建图的关键能力拼图。
目前,LingBot-Map 的模型和代码已在 Hugging Face开源。随着更多开发者和研究团队参与,流式三维重建将推动机器人更稳定、更高效地理解和适应真实物理世界。

推荐阅读





×
右键可直接复制图片