
 阅读时间大约10分钟(3994字)
阅读时间大约10分钟(3994字)
2026-05-09 从“像个柜子”到“能打开的柜子”:3D生成进入物理可部署的具身时代
来源:AI
3D 生成在具身 AI 中究竟扮演什么角色?
出品:具身智能之心
从 DreamFusion、Magic3D,到 TRELLIS、Hunyuan3D,3D 生成的视觉指标在过去两年里被一次次刷新。但站在具身智能与机器人研究者的角度,一个尴尬的事实是:绝大多数"看起来很不错"的生成结果,根本拿不到仿真器里跑。
一个柜子有用,不是因为它长得像柜子,而是它的门要能绕着合理的铰链转动;一块布料有用,不是因为它纹理逼真,而是它在接触下要能正确形变;一个房间有用,不是因为它视觉协调,而是机器人要能在其中导航、抓取、完成任务。
这一系列要求,把 3D 生成从一个"视觉合成问题"推向了一个"物理可部署性问题"。
正是在这一背景下,香港科技大学、武汉大学、腾讯混元 3D、新疆大学等机构的研究团队联合发布了首篇面向具身智能与机器人仿真的 3D 生成综述。论文围绕一个被以往综述长期忽视的问题展开:3D 生成在具身 AI 中究竟扮演什么角色?由此提出"数据生成器、仿真环境、虚实桥梁"三角色框架,把分散在视觉、图形学、机器人、仿真四个社区的 130+ 篇代表性工作系统串联,并把"仿真就绪(Simulation-Ready)"明确为统一的评价标准。

论文标题:3D Generation for Embodied AI and Robotic Simulation: A Survey
论文链接:https://arxiv.org/abs/2604.26509
项目主页:https://3dgen4robot.github.ioGithub
仓库:https://github.com/hitcslj/3DGen4Robot

图 1. 综述总览:以 Preliminaries 为基础,三大核心模块 Data Generator、Simulation Environments、Sim2Real Bridge 分别承担对象级资产创建、场景级环境合成、虚实迁移闭环;Datasets & Evaluation 与 Challenges 收尾。
一、为什么需要一篇"具身视角"的 3D 生成综述?
1. 演进之路:从「看得见」到「用得上」
3D 生成的演化,大致经历了三个阶段:
几何阶段:3D-GAN、AtlasNet、OccupancyNet、DeepSDF 等方法围绕形状本身建模,关注的是"长得像";视觉阶段:从 DreamFusion、Magic3D 的优化路线,到 TRELLIS、Hunyuan3D 的前馈路线,生成质量与速度被持续刷新,关注的是"看起来真";具身阶段:当 3D 资产被送入物理仿真器,需要的是关节、物理、形变、接触,关注的是"能不能用"。
前两个阶段的评价指标(CD、FID、CLIP Score)已经无法支撑第三阶段的需求。一个非流形 mesh 在 NeRF 渲染里看不出问题,进 MuJoCo 就直接崩;一个生成的橱柜外观逼真,但门的铰链方向是猜的,机器人根本拉不开。
2. 现有 3D 生成综述为何还不够?
已有的 3D 生成综述大多按生成范式(Diffusion / AR / VAE)切分章节,关注 FID、CLIP Score 等视觉指标。这对具身社区是远远不够的。研究者真正想回答的是:"哪些方法的输出,能直接进 MuJoCo / Isaac Sim / Genesis 跑起来?"
这正是这篇综述的出发点。
二、核心思路:用「角色」而不是「技术栈」组织文献
与按生成模型范式切分的传统做法不同,本综述只问一个问题:3D 生成在具身 AI 中到底承担什么角色?
由此引出了三大核心模块,也定义了整篇综述的分类体系:
Data Generator(数据生成器):3D 生成是"具身资产工厂",产出关节、物理、形变物体以及端到端 sim-ready 资产;Simulation Environments(仿真环境):3D 生成是"世界搭建者",从结构驱动一路演进到智能体驱动的场景合成;Sim2Real Bridge(虚实桥梁):3D 生成是"训练-部署连接器",覆盖数字孪生、3D 数据增强、任务与示教生成。
围绕这三大角色,综述还系统整理了技术预备、数据集、评测协议、关键挑战与未来方向。
本综述的三个核心贡献:
重新锚定评价标准:首次把"仿真就绪"(涵盖物理有效性、运动学可执行性、仿真器格式兼容性)明确为评价 3D 生成方法的核心维度,而不是视觉质量;首个"三角色"分类体系:把视觉、图形学、机器人、仿真四个原本割裂的社区串联起来;系统提炼卡脖子问题:大规模物理标注的缺失、生成质量与仿真兼容性的张力、具身评测的碎片化、Sim2Real 闭环的未闭,并给出了具体的研究方向。
三、Data Generator:从「做出来」到「能仿真」
第 3 章按物理复杂度递进,把对象级生成分为四类,覆盖 48 种代表性方法。
1. 关节物体(Articulated Objects):从纯几何到原生 URDF
关节物体是具身交互的基本单位,研究演进非常清晰:
怎么决定零件的连接关系?Kinematify 用 MCTS 搜索可行结构;NAP / GAOT / UniArt 用层次化或体素化表示建模零件连接;CAGE / ArtFormer / ArtiLatent / ArtGen / SINGAPO 用扩散模型联合建模几何与运动学;MagicArticulate / MeshArt / Particulate 把骨架预测重塑为自回归序列建模问题。
纯几何不够,怎么办?Articulate-Anything、URDF-Anything、ArtLLM、ArtiWorld、SPARK 等借助 LLM/VLM 的语义先验,从单图或文字推断关节结构;URDFormer、Real2Code、URDF-Anything+ 直接生成 URDF 或可执行运动程序,绕开几何到格式的鸿沟。
怎么直接拿去做仿真?Infinite Mobility 通过约束求解 + 物理规则规模化合成;PhysX-Anything 联合生成几何、关节与质量/摩擦/惯量等物理属性,直接导出 URDF/MJCF。这标志着关节物体生成正式进入"原生 sim-ready"时代。
静态几何看不出自由度怎么办?PartRM 在拖拽提示下建模零件级 4D 动力学;DreamArt 引入视频生成模型的运动先验,让"动起来"成为生成的一部分。
2. 物理物体(Physically-grounded Objects):从「事后修复」到「原生物理」
这一类的演化路径,可以用一句话概括:物理从"事后补丁",变成了"内嵌信号"。
理解阶段:NeRF2Physics、GaussianProperty 把 LLM/VLM 的语义先验蒸馏为物理属性预测;后处理阶段:Atlas3D、PhysComp、DensiCrafter、PhysPart 引入稳定性 / 接触损失反向修正;训练阶段:DSO 用仿真器作为奖励信号微调生成器,PhyCAGE 引入物理引导的 Score Distillation;原生统一阶段:PhysX-3D、PhysX-Anything、SOPHY、PhysGaussian、PIXIE 把几何、外观、物理参数统一进同一表示。
3. 形变物体(Deformable Objects):缝纫图样的启示
形变物体生成是公认的硬骨头,连续介质力学(FEM/MPM/PBD)天然不友好。但服装领域给出了一个令人欣慰的范式:
DressCode 用文本生成缝纫图样(Sewing Pattern),直接喂给布料仿真器;GarmentDreamer 引入 3DGS 多视图监督;Dress-1-to-3 把可微布料仿真嵌入优化环路;Image2Garment 走前馈路线提升可扩展性。
缝纫图样的成功揭示了一个朴素而深刻的道理:与其追求最终态的几何,不如找到一个"可生成且可被仿真器直接消费"的中间表示。
而对通用软体(绳、食物、颗粒物),目前还停留在 PhysGaussian / PhysDreamer / SOPHY 这样的逐实例优化阶段,这也是综述明确指出的开放问题之一。
4. 端到端 Sim-Ready 管线:把流水线打通
最具实践意义的一类工作。代表方法:
TRELLIS / TRELLIS.2:统一的结构化潜表示,单一编码可解码为 Mesh、3DGS 或 Radiance Field;Seed3D 1.0:耦合多视图纹理合成、PBR 估计、UV 完整化、尺度标定,输出可直接导入 Isaac Sim 的水密带纹理网格;EmbodiedGen:把 image/text-to-3D、质量控制、物理属性估计、URDF 序列化、布局构建整合为统一工具链。
这一层的意义在于:3D 生成系统正在从"视觉内容创作器"演化为"具身资产引擎"。

图 2. Data Generator 总览:按物理复杂度递进,Articulated → Physically-grounded → Deformable → End-to-End Pipelines。
四、Simulation Environments:从「摆得对」到「能交互」
第 4 章聚焦室内场景生成,覆盖 35 种代表性方法。综述按"控制能力"递进,把场景生成方法分为三个阶段。
1. 第一阶段:结构驱动(Structure-Driven)
过程化方法:ProcTHOR 在显式约束下采样平面图与拓扑;Infinigen Indoors 用 Blender 中的层次化规则;LayoutGPT 用 LLM 把文本翻译成布局规范;Holodeck 把语言转化为关系约束并优化布局。
场景先验方法:Graph-to-3D 从场景图预测 3D 表示;ATISS 用自回归方式生成物体序列;CC3D 在 2D 语义布局条件下合成;DiffuScene 在物体属性空间做去噪。
共性瓶颈:完全依赖外部资产库(3D-FUTURE、Objaverse),场景多样性最终被资产覆盖度而非生成器本身限制。
2. 第二阶段:可控生成(Controllable)
按条件信号分三路:
指令条件:InstructScene、SceneFoundry、Steerable Scene Generation;视觉条件:SceneGen、DepR、MIDI;物理条件:PhyScene、DynScene、FactoredScenes,把"物理可达性"明确写进生成目标。
3. 第三阶段:智能体生成(Agentic)
借助基础模型的推理能力,从"一次出图"走向"规划-反思-修复"的闭环:
模块化智能体:OptiScene、LayoutVLM、Scenethesis、SceneCraft、CAST、3D-RE-GEN、MetaScenes、3D-Generalist、Architect;自反思智能体:SceneWeaver、SAGE、DisCo-Layout、PAT3D、PhyScensis、SceneSmith;任务驱动智能体:MarketGen(超市级环境)、MesaTask(桌面任务)、TabletopGen。
值得警惕的代价:综述明确指出,几乎没有智能体式工作报告生成成本与吞吐。它们能否产出大规模训练所需的成千上万个环境,仍是一个悬而未决的问题。

图 3. 室内场景生成方法的演进路径:Structure-Driven → Controllable → Agentic。
五、Sim2Real Bridge:把生成「真正用起来」
第 5 章把 3D 生成放到"训练-部署"的闭环中考察,覆盖 39 种代表性方法,分为三个相互衔接的子方向。
1. 生成式数字孪生(Generative Digital Twin)
自动化场景重建:DRAWER、LiteReality、LatticeWorld、RoboSimGS、Scalable Real2Sim 把 RGB-D 输入直接转化为可交互的图形/物理资产;
关节重建:Ditto / PARIS / ArticFlow 用隐式表示与流匹配恢复关节结构;ArticulatedGS / ArtGS / REArtGS++ 把 3DGS 与关节先验耦合;
物理感知与视觉-动力学对齐:PhysTwin 用弹簧-质量模型 + 3DGS 估计材料参数;TwinAligner 解耦碰撞几何与视觉渲染,用无梯度优化对齐真实轨迹;Real-is-Sim 维护 60 Hz 同步的 Embodied Gaussian 孪生体,把数字孪生推到了实时闭环。
2. 生成式数据增强(Generative Data Augmentation)
视角与几何增强:RoboSplat、SplatSim、AOMGen 在 3DGS 之上合成多视角观测;
动态与时序增强:ExoGS、GAF 把示教重建为带动态属性的可编辑资产;
物理一致性约束:RoboTransfer 用深度/法线引导视频扩散;EgoDemoGen 通过自监督双重投影合成第一视角观测;Splat-MOVER、Maniwhere、SIGHT 强制几何一致性。
核心转变:从像素级扰动,走向"几何一致性作为硬约束"的增强范式。
3. 任务与示教生成(Task & Demonstration Generation)
示教扩展:MimicGen、DemoGen、Gen2Sim、GenSim2、R2R2R、ManipDreamer3D;
世界模型驱动:DreamGen、AnchorDream、PhysWorld、DRAW2ACT、Video2Act、GWM 把视频/3DGS 世界模型作为"神经仿真器";
基础模型规模合成训练:GraspVLA 在 SynGrasp-1B 十亿帧合成数据集上训练,配合 PAG(Progressive Action Generation)实现开放词表抓取。这是 3D 生成第一次以"基础设施"的姿态出现在 VLA 训练管线里。

图 4. Sim2Real 闭环:真实观测 → 数字孪生 → 数据增强 → 任务/示教生成 → 真实部署,再回到数据生成的反馈循环。
六、数据集与评测:被严重低估的瓶颈
第 6 章梳理了支撑该领域的 40 个代表性数据集与 22 项评测指标。
1. 数据集:规模与标注深度的双轴演化
物体资产数据集:从 ShapeNet、PartNet 的纯几何资源 → PartNet-Mobility、AKB-48、GAPartNet 的关节标注 →PhysXNet、PhysX-Mobility 的全物理标注,规模与标注深度的两条轴清晰可见。Objaverse / Objaverse-XL(800K / 10M+)已成为 TRELLIS、EmbodiedGen 等模型的事实预训练语料,但缺乏物理标注,这正是当前最大的数据缺口。
场景数据集:从源场景(3D-FRONT、3DSSG、Replica、HM3D)→ 生成场景(ProcTHOR-10K、SAGE-10K、MetaScenes)→ 任务/领域专用场景(MesaTask-10K、MarketGen),完成"从被动采集到主动构建"的迁移。
机器人示教数据集:Open X-Embodiment(百万级跨形态轨迹)、DROID、RH20T、BridgeData V2 代表真实数据;RoboTwin、RoboTwin 2.0、RoboCasa、ManiSkill2/3、RLBench、LIBERO、CALVIN 提供仿真基准;MimicGen 代表算法增强路线。
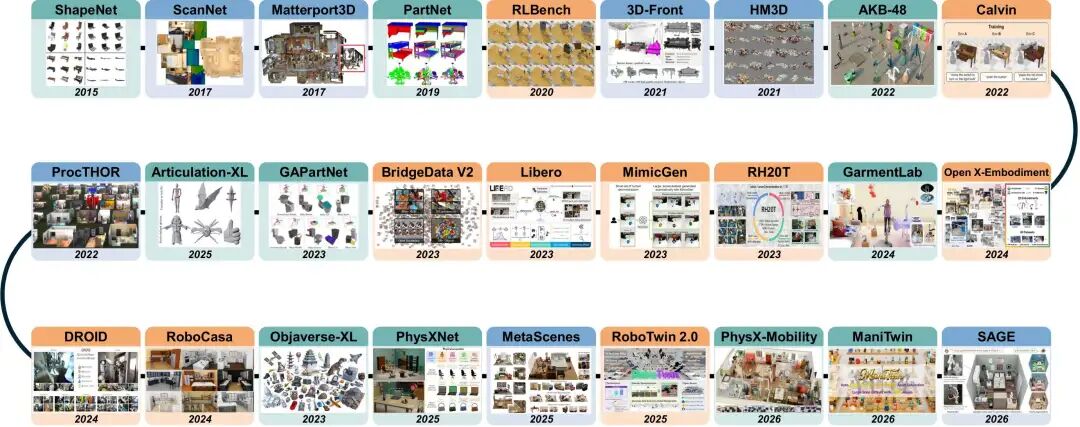
图 5. 数据集时间线,按几何 / 关节-物理 / 场景 / 示教分类的代表性数据集年代分布。
2. 评测:三层协议的标准化呼吁
综述提出三层评测协议作为标准化方向:
格式有效性:能否被目标仿真器无错加载;物理可行性:稳定率、穿透体积、关节限制合规率等仿真器无关指标;下游任务表现:固定策略与仿真器配置下的任务成功率,把资产质量从策略噪声中分离出来。

表 1. 22 项评测指标,覆盖几何/外观、物理/Sim-Ready、具身任务三大层级。
七、五个真正卡脖子的挑战
第 7 章不打算给出乐观结论,而是直面 5 个仍然没解决的问题:
① 大规模物理标定。物理标注数据集比几何数据集小数个量级;可微仿真嵌入训练循环(DSO、PhysPart)是最有希望的方向,但计算成本随场景复杂度急剧上升。轻量代理验证器可能是务实的中间方案。
② 形变与动态资产生成。缝纫图样的成功提示了一个方向:能否为通用软体找到类似的"可生成且可直接被求解器消费"的中间表示?
③ 场景生成的效率-可控性权衡。学习方法快但语义弱,智能体式方法准但贵。综述建议两条路:摊销验证(amortized verification)+层次生成(hierarchical generation)。
④ 评测标准化。当前评测在不同仿真器之间不可比;倡导跨仿真器一致性测试作为下一步。
⑤ 闭合 Sim2Real 闭环。最根本的限制是生态碎片化:生成、物理、策略学习在三个独立社区独立优化,靠脆弱的格式转换串联。统一的"几何-物理-语义"基础模型是最终方向。
结语
如果用一句话总结这篇综述的立场:
3D 生成正在从"视觉内容创作工具",演进为"具身智能基础设施"。
这意味着评价标准要变,从"看起来好"变为"用起来稳";研究范畴要扩,从孤立的物体合成走向"生成-仿真-学习"统一闭环。评价一项工作的关键指标,将不再只是 FID / CLIP Score,而是它产出的资产能否撑起一个能跑通的机器人任务。
期待这篇综述能为社区提供一份详实的"路线图",推动 3D 生成、物理仿真与具身学习真正走向统一。

推荐阅读




×
右键可直接复制图片