 阅读时间大约7分钟(2762字)
阅读时间大约7分钟(2762字)
10小时前 4亿参数“小脑”开源:HoloMotion-1 给人形机器人补上了哪块短板?
来源:机器人产业应用
对行业而言,这意味着机器人“小脑”开始有了可共享、可评测、可迭代的底座。
作者:余柯 排版:曹若曦 出品:机器人产业应用
前言
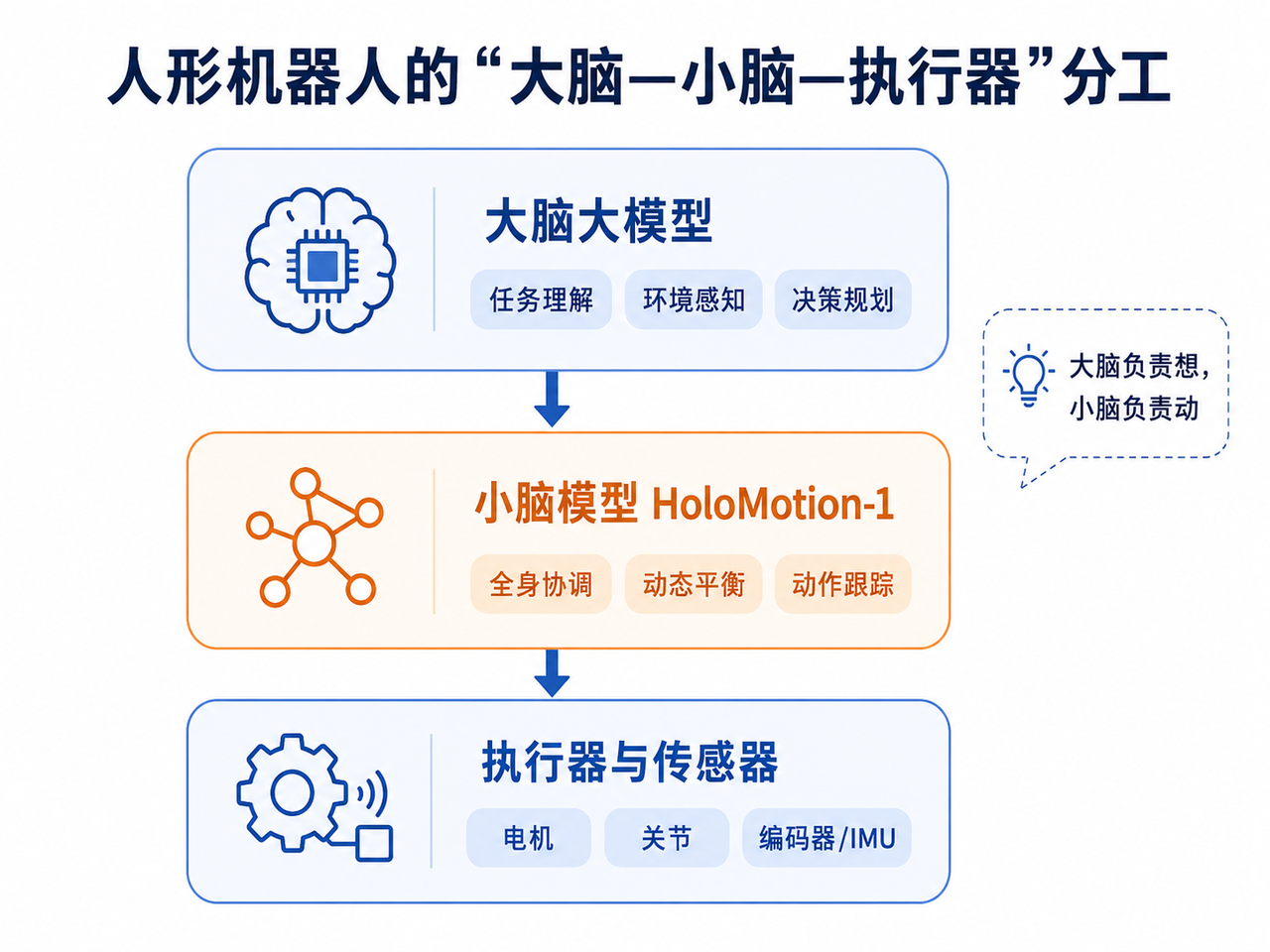
最近谈人形机器人,公众更关注“大脑”:它能不能听懂人话,能不能识别物体,能不能规划任务。但真正让机器人在现实世界站稳、转身、下蹲、挥手、踢腿甚至跳舞的,往往不是大脑,而是“小脑”。
这里的“小脑”不是生物学意义上的器官,而是机器人底层运动控制模型。它接收机器人自身状态、参考动作、速度或姿态目标,输出关节级控制指令,让几十个自由度在毫秒级时间内协同起来。人说“走过去拿杯子”,大脑负责理解“杯子在哪、路线怎么走”;小脑负责让机器人每一步不摔倒、上肢和躯干不打架、脚底接触稳定、动作连续自然。
地平线开源的 HoloMotion-1,核心价值就在这里:它不是再造一个聊天机器人,而是把人形机器人的运动控制模型做大、做快,并尝试做成可复用的基础模型。
01
什么是机器人“小脑模型”?
传统机器人控制常用分层架构:任务规划在上层,轨迹规划在中层,底层控制器负责电机力矩或关节位置。优点是可解释、稳定,缺点是面对复杂全身动作时工程量极大。比如机器人要从站立切换到蹲下,再伸手、转身、恢复平衡,躯干、髋、膝、踝、肩、肘、腕都要同步变化。每增加一种动作,控制策略都可能重新调参。
小脑模型的思路是:让模型从大量人体动作、仿真交互和机器人状态中学习“全身协调规律”。它不只学一个动作,而是学习一类动作分布。HoloMotion-1 的定位是人形机器人全身运动跟踪基础模型,即给定参考动作后,让机器人尽可能稳定、准确地模仿并执行。
这与“大脑大模型”的分工不同。大脑偏语义、推理、规划,频率可以较低;小脑偏连续控制、动态平衡、实时反馈,频率必须很高。大脑可以慢半秒想清楚,小脑不能慢半拍,否则机器人已经摔了。
02
HoloMotion-1 带来了什么不同?
HoloMotion-1 的差异主要体现在三个方面:模型规模、数据来源和端侧推理效率。

以往不少人形机器人控制策略采用 MLP,也就是多层感知机。MLP 很快,但对长时序动作、复杂运动风格和跨数据分布的表达能力有限。HoloMotion-1 使用 MoE Transformer,把控制模型推到 4 亿参数量级,同时通过稀疏激活控制计算量。通俗说,它有一个很大的“动作知识库”,但每一帧只调用其中少数相关“专家”。

这张表说明一个关键点:HoloMotion-1 不是简单“参数越大越好”,而是“总容量大、单步计算小”。总参数 4 亿,单步实际激活约 700 万。相比传统小模型,它可以覆盖更复杂的动作分布;相比普通密集大模型,它又不会把全部参数都算一遍。
03
MoE 和 KV-cache 为什么能让它跑到 300FPS?
MoE 是 Mixture-of-Experts,中文常译为“专家混合”。可以把它理解为一个由多个子网络组成的系统。每来一帧机器人状态,路由器先判断当前更像哪类运动:走路、转身、下蹲、踢腿、手臂摆动,或者多个动作的组合。随后只激活少数专家参与计算。这样,模型总容量可以很大,但每一步的计算成本保持较低。
KV-cache 是 Transformer 推理中的缓存机制。Transformer 需要关注过去一段时间的状态,才能理解动作连续性。如果每一帧都把过去所有状态重新算一遍,计算量会随时间窗口急剧上升。KV-cache 会把历史注意力中的 Key 和 Value 存起来,下一帧只计算新增状态,再与缓存交互。结果是:模型保留时序记忆,但避免重复计算。
这两者合起来,构成 HoloMotion-1 的实时性基础:MoE 减少“每帧要算多少参数”,KV-cache 减少“每帧要重复算多少历史”。因此它能在机器人端侧计算模块上达到约 200–300Hz 推理速度。
但这里要避免一个误解:300FPS 不等于机器人电机以 300Hz 直接执行所有控制。论文中真实机器人控制环固定为 50Hz,模型推理更快意味着系统有更多实时余量,可用于状态估计、通信、安全检查和控制缓冲。端侧高速推理的价值,不是炫技,而是降低闭环延迟,让动作更稳、更及时。
至于和芯片的关系,可以概括为一句话:模型结构决定“少算什么”,芯片决定“剩下的算得多快”。MoE、KV-cache、低精度矩阵计算、内存带宽和算子优化共同决定最终帧率。公开资料并未把 300FPS 归因于某一颗具体芯片,因此更准确的表述应是:这是模型结构、推理工程和端侧算力协同的结果。

04
零样本迁移到底省了什么成本?
“零样本迁移”容易被误读成“什么机器人、什么场景都不用训练”。这不准确。HoloMotion-1 当前更明确的能力,是对未见过动作和动作来源的泛化,以及在特定真实人形平台上的直接部署验证。它不是万能控制器,也不意味着换任意机型都能即插即用。
即便如此,它仍能显著降低三类成本。
第一,降低动作采集成本。传统控制策略往往依赖高质量 MoCap,即动作捕捉数据。MoCap 精度高,但采集贵、覆盖窄。HoloMotion-1 引入大量野外视频(真实、非受控的自然环境中拍摄的视频)重建动作,再用 MoCap 和自有数据补充高质量监督,使动作多样性更容易扩展。
第二,降低专项训练成本。过去做一个舞蹈、下蹲、爬行或武术动作,可能要单独采集、训练、调参和仿真验证。基础小脑模型的意义在于,把大量动作共性先学好,新动作更多通过参考轨迹和重定向进入系统,而不是每次从零训练。
第三,降低真机试错成本。人形机器人真机训练代价高,摔一次可能损坏关节、电机或结构件。若模型能在仿真中学习更多扰动、摩擦、质量偏差和动作延迟,再迁移到真机,整机厂可把更多风险前置到仿真阶段。
当然,零样本不是免验证。真实部署仍需要机器人动力学参数、关节限位、执行器性能、传感器延迟、安全策略和场景边界的工程校准。
对整机厂,最大利好是缩短从“能走”到“能做动作”的路径。开源模型、训练流程和评测框架能提供一个公共基线,减少重复造轮子。厂商可以先用预训练策略做离线动作复现、在线遥操作或演示动作,再逐步叠加自有硬件适配和安全层。
对零部件企业,利好在于形成更真实的控制负载。电机、减速器、传感器、计算模组和电池企业过去常用单项指标宣传性能,但人形机器人真正需要的是系统级闭环表现。小脑模型普及后,零部件可以围绕真实动作任务评估:关节响应够不够快,编码器噪声会不会影响平衡,计算模块能不能稳定低延迟运行,散热和功耗能否支撑长时间运动。
对开发者和高校,开源的意义更直接:有了可复现基线,就能围绕动作数据、仿真环境、迁移学习、安全约束和跨机型适配继续研究。人形机器人不缺概念,缺的是能被验证、能被复用的工程起点。
05
哪些场景可能率先受益?
高速小脑模型最先推动的,未必是复杂家务,而是对“全身运动表现”要求高、对复杂物体操作要求相对低的场景。
第一类是展演、文旅、商业导览。跳舞、挥手、迎宾、讲解、队列动作,核心是动作自然、稳定、可快速编排。HoloMotion-1 这类模型能让机器人更快生成多样化动作,减少逐个动作调参。
第二类是远程操控和训练。通过 VR、惯性动捕或遥操作设备,人可以给机器人输入身体动作,小脑模型负责把人体动作转成机器人可执行的全身控制。这适合危险环境巡检、应急演练和专业训练。
第三类是工业和仓储中的移动辅助。短期内,人形机器人未必能独立完成复杂装配,但稳定行走、转身、蹲起、搬运姿态切换和上肢协同,会直接影响其进入半结构化场景的速度。
更长期看,真正的通用人形机器人需要“大脑”和“小脑”合流:大脑理解任务,小脑保证动作可执行,感知系统实时修正环境变化,安全层负责约束边界。HoloMotion-1 的价值不是让机器人突然具备通用智能,而是把长期被低估的底层运动控制,推进到基础模型阶段。
06
结语
人形机器人商业化的瓶颈,不只在“听懂人话”,也在“身体听话”。HoloMotion-1 的开源信号很明确:运动控制正在从手工调参、小模型策略,走向大规模数据、基础模型和端侧实时推理。
它的亮点不是单一的 4 亿参数,也不是单一的 300FPS,而是把大容量模型、稀疏计算、时序缓存、混合动作数据和真机部署放进同一条链路。对行业而言,这意味着机器人“小脑”开始有了可共享、可评测、可迭代的底座。
但也要冷静看待:当前 HoloMotion-1 主要解决“模仿任意姿态”的第一阶段问题,面向任意指令、复杂地形和跨机型泛化仍是后续挑战。人形机器人真正落地,还要跨过硬件可靠性、安全规范、成本控制和场景闭环。小脑变强,是必要条件,不是全部答案。

推荐阅读





×
右键可直接复制图片