
 阅读时间大约5分钟(1946字)
阅读时间大约5分钟(1946字)
2025-05-12 成功率高达96.3% 机器人实现穿针引线,中科院提出ConRFT VLA模型强化微调方法
来源:具身智能大讲堂
近年来,视觉-语言-动作(VLA)模型在机器人领域中表现出了强大的潜力,尤其在复杂的操作任务中。
作者:李鑫 出品:具身智能大讲堂
近年来,视觉-语言-动作(VLA)模型在机器人领域中表现出了强大的潜力,尤其在复杂的操作任务中。然而,尽管这些预训练的模型能够通过大规模模仿式预训练和机器人行为的基础训练捕捉到有用的操作,但机器人在处理现实世界中的复杂情景时仍然面临不少的挑战。特别是在场景相对复杂的环境下,使用传统的监督学习(SFT)进行模型微调时,有限且不一致的演示数据常常无法提供足够的支持,从而导致模型性能发挥不稳定。

传统的监督微调(SFT)方法依赖于高质量的任务特定数据,但这些数据往往数量有限且不一致,导致模型在接触丰富的环境中表现不佳。强化学习(RL)作为一种强大的工具,能够弥补策略能力与人类偏好之间的差距,但直接将RL应用于VLA模型面临样本效率低和安全性要求高的挑战。
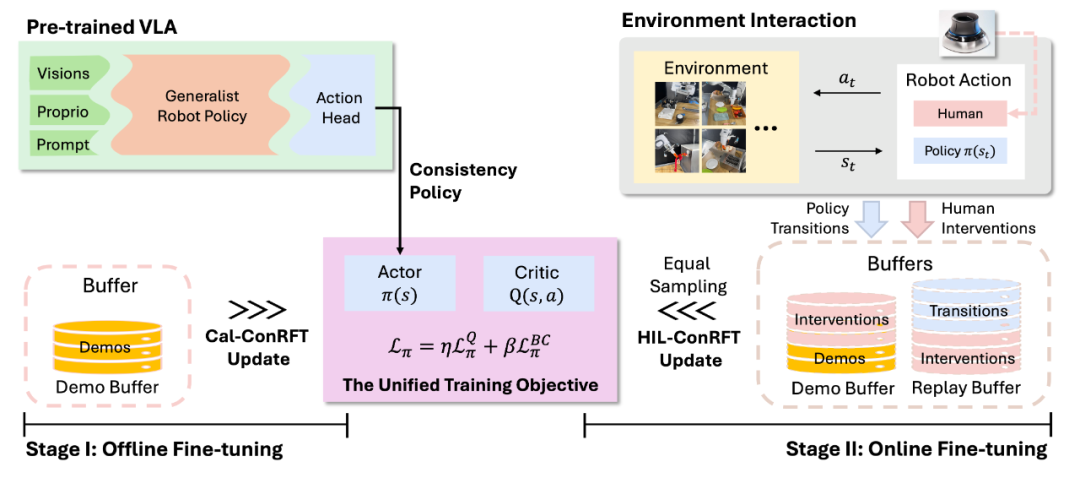
为了先决这个困难,中国科学院自动化研究所智能系统国家重点实验室、中国科学院大学人工智能学院研究人员提出了一种基于一致性策略的 VLA 模型强化微调方法——ConRFT。该方法分为离线微调和在线微调两个阶段,ConRFT通过统一的基于一致性的训练目标来优化VLA模型。在离线阶段提取有效的策略和值函数;在线阶段则通过人类干预确保安全探索和高样本效率。
1► ConRFT方法概述
研究人员将每个机器人操作任务视为一个马尔可夫决策过程(MDP),目标是通过RL找到最优策略。VLA模型通过最大化累积期望奖励来优化其行为。ConRFT方法包含两个阶段:离线微调(Cal-ConRFT)和在线微调(HIL-ConRFT)。
离线微调(Cal-ConRFT)
在离线阶段,ConRFT使用预收集的小规模演示数据集,通过结合行为克隆(BC)损失和Q学习损失来微调VLA模型。具体来看,Cal-ConRFT采用Calibrated Q-Learning(Cal-QL)作为基础离线RL方法,通过减少时间差分(TD)误差和一个额外的正则化项来训练Q函数。同时,引入BC损失来最小化策略生成的动作与演示动作之间的差异,提供额外的监督信号。
在线微调(HIL-ConRFT)
在线阶段,ConRFT通过人类干预和一致性策略进一步微调VLA模型。人类操作员可以通过遥操作工具(如SpaceMouse)在机器人策略探索过程中提供纠正动作,这些纠正动作被添加到演示缓冲区中,为策略提供高级指导。在线阶段使用与离线阶段相同的一致性策略损失结构,通过结合预收集的演示数据、策略转换和人类干预数据进行微调。
2► 实验设置与结果验证
研究人员在八个真实世界的机器人操作任务中系统验证了ConRFT方法的有效性,具体任务涵盖抓取与放置香蕉、勺子、面包等日常物品,操作抽屉与烤面包机等家居设备,以及组装椅轮、编织中国结等复杂精细动作。

实验采用Octo-small模型作为视觉语言动作(VLA)模型的基础架构,并在配备7自由度(7-DoF)的Franka Emika机械臂平台上完成部署。每个任务的状态观测由多模态信息构成,包括手腕摄像头与侧置摄像头的RGB视觉输入,以及机械臂关节位置、速度等本体感觉状态数据。
实验结果显示,ConRFT方法在全部任务中实现了96.3%的平均任务成功率,较传统监督学习基线方法提升144%。与HG-DAgger、PA-RL等先进方法对比表明,ConRFT在任务成功率、样本利用效率及单任务完成步数等核心指标上均表现优异。特别是在椅轮插入、中国结悬挂等高接触复杂度任务中,ConRFT凭借其精准的力控与位姿调整能力,展现出显著的性能优势。
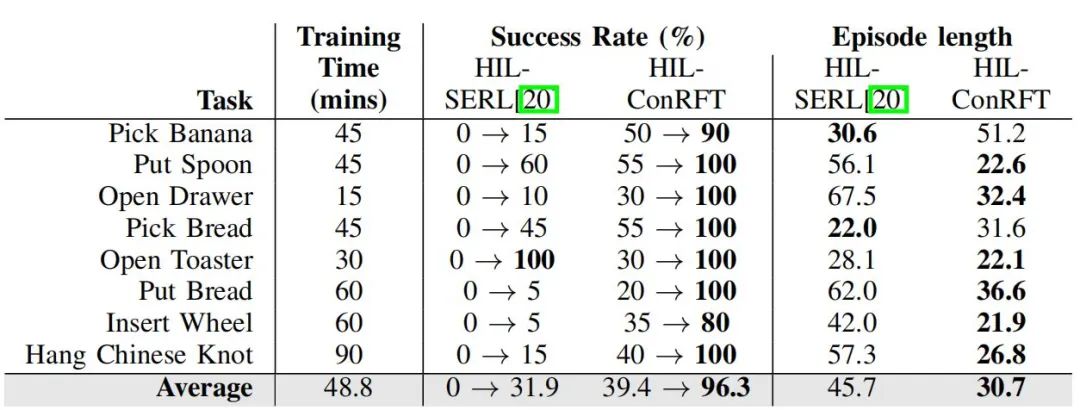
相较于直接训练强化学习(RL)策略的基准方案,ConRFT通过预训练VLA模型的迁移学习机制,实现了在线训练时间的压缩与人工干预频次的降低。实验数据显示,在相同训练周期内,ConRFT方法可快速收敛至高成功率策略,而从头训练的RL方法则普遍存在策略振荡或收敛失败现象。
进一步验证表明,ConRFT方法具有跨模型架构的泛化能力。研究人员在RoboVLM等不同VLA模型上开展对比实验,证实该方法可通过模块化适配显著提升多种视觉语言动作模型在机器人任务中的执行效能。
3► ConRFT方法目前存在的局限性
研究人员指出,在当前强化学习(RL)框架下,任务特定的二元分类器被广泛应用于奖励信号的计算。然而,这种设计存在一个固有的局限性:分类器的训练数据分布与RL策略在探索过程中实际生成的状态-动作分布之间存在分布偏移问题。这种分布不匹配可能导致策略在训练过程中学习到非预期的行为模式,进而影响其在实际任务中的表现。为应对这一挑战,未来的研究工作可考虑引入多任务密集奖励信号机制,通过整合来自多个相关任务的丰富反馈信息,为策略提供更为细致和全面的学习指导,从而有效提升样本利用效率并加速策略收敛过程。
此外,在当前实现方案中,视觉编码器和Transformer骨干网络在在线训练阶段被固定为不可更新状态,这一设计选择虽然简化了训练过程并保证了模型的稳定性,但同时也限制了策略在在线训练过程中对其感知和表示模块进行针对性优化的能力。研究人员认为,未来工作应探索采用参数高效微调技术,如低秩适配(LoRA)方法,来部分或完全释放这些冻结组件的更新权限。通过此类技术,可以在保持模型主体结构稳定的同时,针对特定任务需求对关键模块进行精细调整,进而提升策略在复杂多变环境中的适应性和任务执行性能。
4► 结语与未来:
中科院研究人员提出的ConRFT方法,通过离线和在线两个阶段的微调,结合一致性策略和强化学习,提升了VLA模型在复杂操作任务中的成功率和样本效率。从结果上来看,ConRFT在多个真实世界的机器人操作任务上均表现出色,优于现有的监督和强化学习方法。未来通过改进其奖励工程和参数更新策略,该技术有望适配更广泛的机器人操作任务。

推荐阅读





×
右键可直接复制图片