
 阅读时间大约9分钟(3587字)
阅读时间大约9分钟(3587字)
2025-05-26 Nvidia的具身推理模型还缺什么
来源:清熙
未来提升具身时空感知的关键,在于将大模型的推理能力与真实感官--动作回路有效结合。
作者:王庆法 出品:清熙
物理人工智能系统需要感知、理解并在物理世界中执行复杂动作,NvidiaCosmos-Reason1就是为此而设计。
一、Cosmos-Reason1Cosmos-Reason1
模型系列宣称可以通过长链思维推理过程理解物理世界,并以自然语言生成相应的具身决策。
该模型将物理AI推理的核心能力,锁定在物理常识和具身推理:
1.采用分层本体论来捕捉关于空间、时间和物理学的基础知识。分层本体将物理常识划分为空间、时间和基础物理三大类16个子类;
2. 基于二维本体论实现跨物理实体的泛化。二维本体映射了人、机械臂、人形机器人等多种具身智能体的推理过程和能力。

通过物理AI监督微调SFT和物理AI强化学习RL两阶段,完成数据构建与模型训练。同时推出基于物理常识具身推理的评估基准,开源了代码与预训练模型。Cosmos-Reason1 通过多模态信息融合和预先编码的物理时空知识,具备了一定的空间关系和时间序列推理能力,可以用自然语言规划和解释具身任务。
二、融合的模型架构
Cosmos-Reason1 模型基础架构为纯解码器Transformer,结合视觉编码器ViT处理视频帧序列,能同时接受文本和视觉输入,一段文本提示和一段低帧率视频。
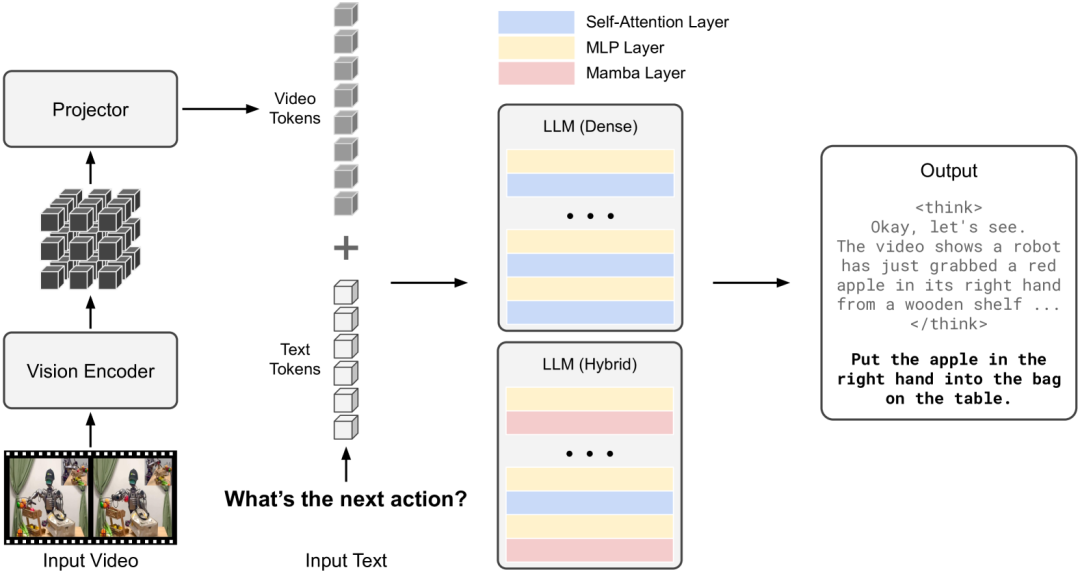
视觉内容由 ViT 编码为语义特征,文本提示与视觉特征一起输入Transformer网络,通过长思维链CoT推理逐步生成输出答案。
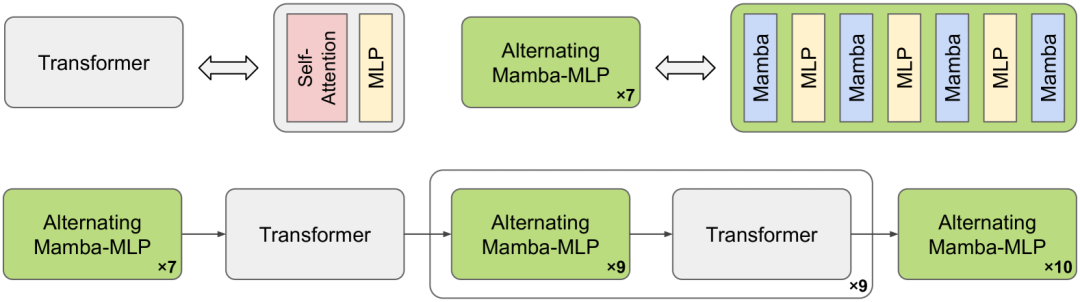
模型核心本质上是状态空间模型Mamba与Transformer的融合架构,通过物理AI SFT,将预先训练的视觉语言模型适配为物理 AI 推理模型,并通过物理 AI 为重点任务的强化学习对模型进行后训练 。
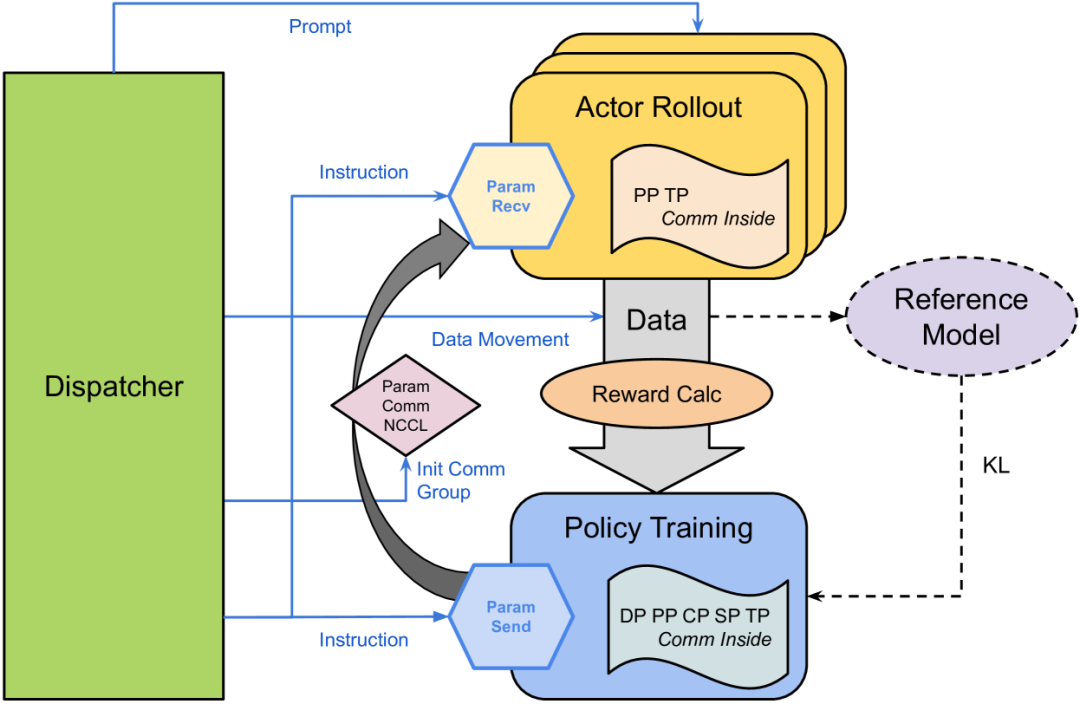
强化学习算法选用GRPO,简单高效,避免了训练和维护单独的批评者模型。GRPO 是简化的策略优化方法,详见GRPO 是DeepSeek魔法的源泉。
三、状态空间模型
Transformer 的后浪来了笔者探讨过Mamba这一“输入依赖的结构化状态空间模型”SSM:
状态空间模型简单,却具备强大的刻画能力,可解决:时变性 time-varying,非线性 nonlinear,通用性 general,即使人脑也能用这个形式建模。
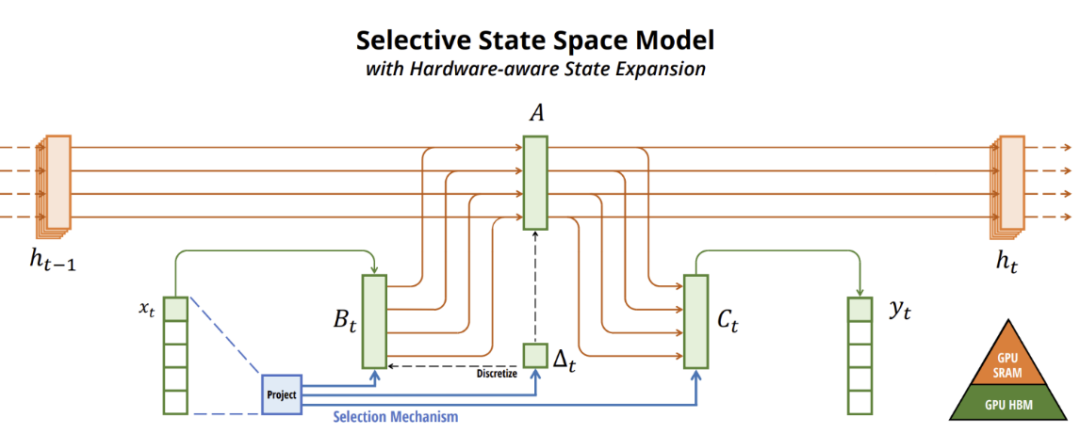
Mamba 非常注重强化建模中非线性部分的处理,"重复这个块,用标准归一化和残差连接交织,形成Mamba 架构";同时"离散化与连续时间系统有着深度的连接,可赋予额外属性,如解不变性与自动确保模型适当归一化"。
不仅"SSM的离散化"处理本身保障适当归一化,还在架构上与标准归一化与残差连接交织,确保了非线性处理能力,参数和步长都是如此,因而优于Transformer特别是仍具有炼金术特征的skip connection部分。
物理具身模型感知、理解以及复杂行动都是在物理时空中发生的,因而需要构建可以对时间、空间建模和推理的世界模型,状态空间模型是其最核心的时间维度建模方式。
四、时空世界模型
在解读OpenAI Sora文生视频技术原理中,笔者详细阐释了如下的时空世界模型构建框架:某个时刻 t ,所有非时间维度张成的状态子空间中,对事物的表征和刻画,可以从细颗粒度到粗颗粒度,逐级重整化提取潜变量分布;从而获取该时刻事物状态的不同颗粒度的信息,形成客观认知,原理可以参考笔者梳理的大模型的数理认知框架。
状态空间随时间的变化,即动态性,从时间的维度研究整个状态空间的变迁,对应着状态空间的时间序列,即状态空间的动力学,或者外在驱动“力”或因素导致的状态的“流动”,状态空间t时刻与 t-n时刻之间的关系,注意力机制捕获到的是其时间依赖规律。
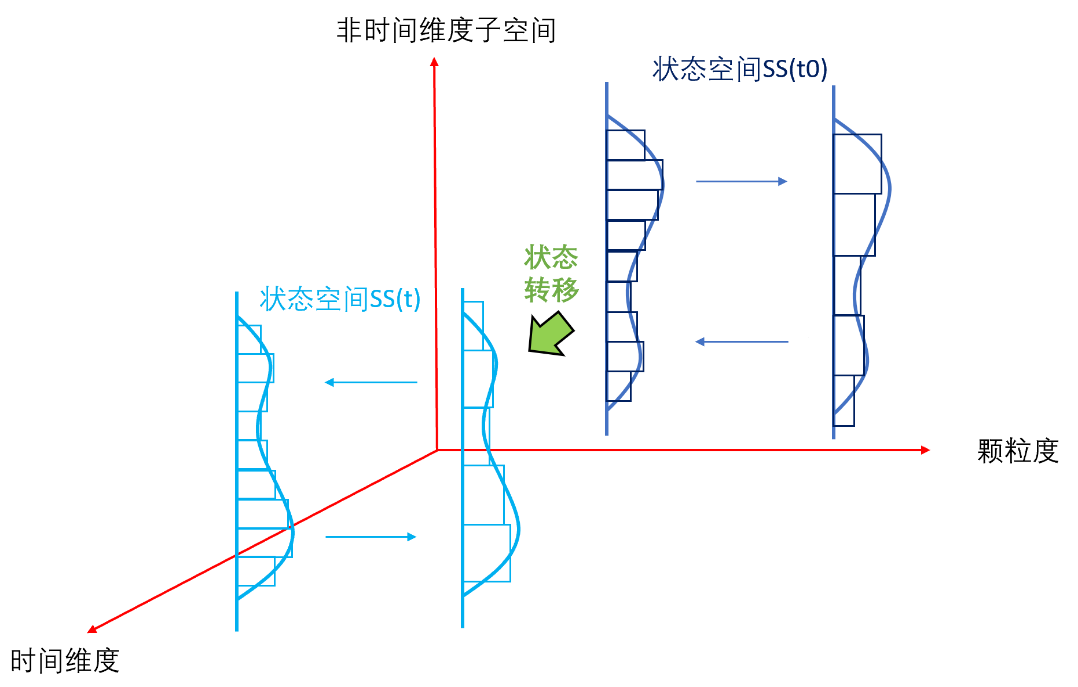
状态空间整体动态性由不同颗粒度的潜变量对象(时空碎片patch)的动力学共同构成。因而,只要模型需要,研究对象可以是潜变量空间中任意颗粒度的碎片patch或其组合。
物理世界中,事物状态的动态演化受数理规律的支配,观测采集这些变化的表征,从中发掘背后隐藏的普适规律是现代自然科学的基本范式,也是一个从概率表征到因果表征的范式,正如苹果砸中牛顿事件。
物理具身模型,对状态空间时间序列的学习过程,是时间维度上的重整化提取信息的过程,从细时间尺度,到粗时间尺度,可以逐层获取到碎片们patches的动力学概率表征。
五、时空推理
构建时空世界模型这一过程,有机会促成从概率表征到因果表征的范式演变,毕竟因果其实是概率的特例。
基于时空世界模型,而不是某一时刻t的世界模型的切片或投影,这样的推理才可能真正变得可靠。通往世界模型之路Sora、Genie、Emo、LTX Studio笔者梳理过:
通过碎片化时空模型,海量学习事物及其运作模式的概率表征,将学到的时空模型,概念化、可选可配可生成,可作为构建时空世界模型的共识范式。LeCun建议的 V-JEPA 实现路径,就是让大家用一致的架构去学习各个领域的局部世界模型,最后拼成整体的世界模型。
不过,世界的复杂性和动态性,决定了无穷无尽的模型需要构建,因而这可能是个无法完成的任务,除非找到了世界演化的核心方式。推本溯源,物质本质上是减速变重的能量。在笔者看来,所谓“物理世界”,是由物质、能量及其相互作用构成的系统,在相对论框架下表现为四维时空的动态结构,并在物理规律约束下演化。
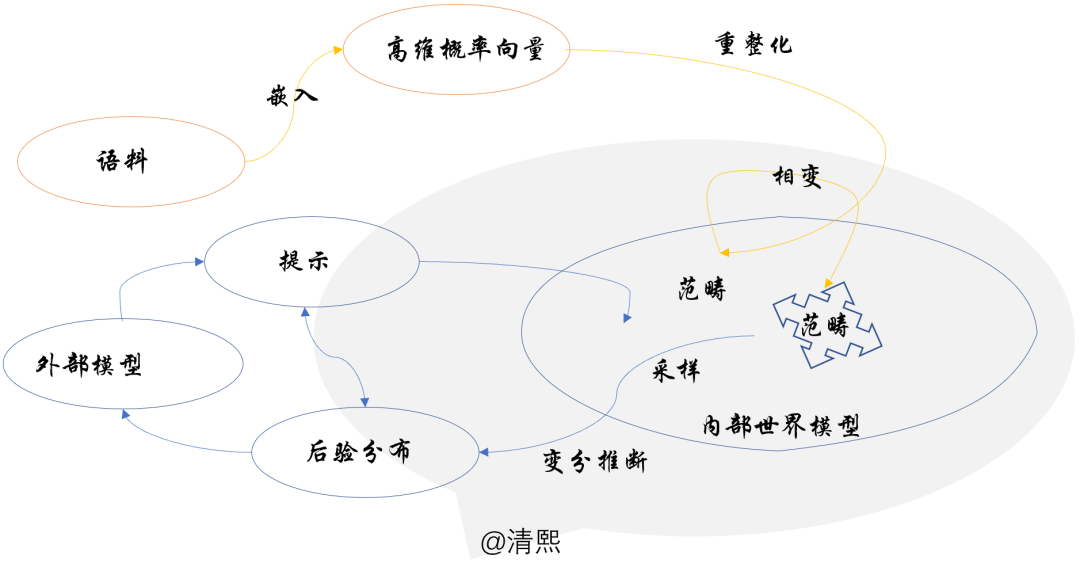
Cosmos-Reason1提出的,分层本体论可提供纵向的层级结构,解决跨层级的依赖与涌现;而二维本体论,则可以提供横向的双重视角,解决同一层级内的多模态存在。
丰富范畴作为形式化工具,可通过赋予态射集额外结构,统一编码横向与纵向的复杂的结构化依赖关系,因而自然可以纳入到笔者建议的大模型的数理认知框架。
六、人类具身智能
神经科学研究表明,感官层面,人类在感知空间与时间时,依赖多通道的感官信息和运动反馈,实现高度整合的认知:
视觉、听觉、触觉、前庭觉和本体觉等协同工作:视觉提供环境的空间布局,前庭觉和本体觉反馈运动信息,两者共同支持运动路径积分和定向导航。
多模态感知与持续运动使人体能够实时更新对空间的理解,并形成对时序的预测能力。感官信息融合可提高空间位置与速度的估计精度。运动经验则进一步强化空间认知:主动移动的大脑不断更新自身在环境中的位置与方向,从而构建动态地图和运动模型。
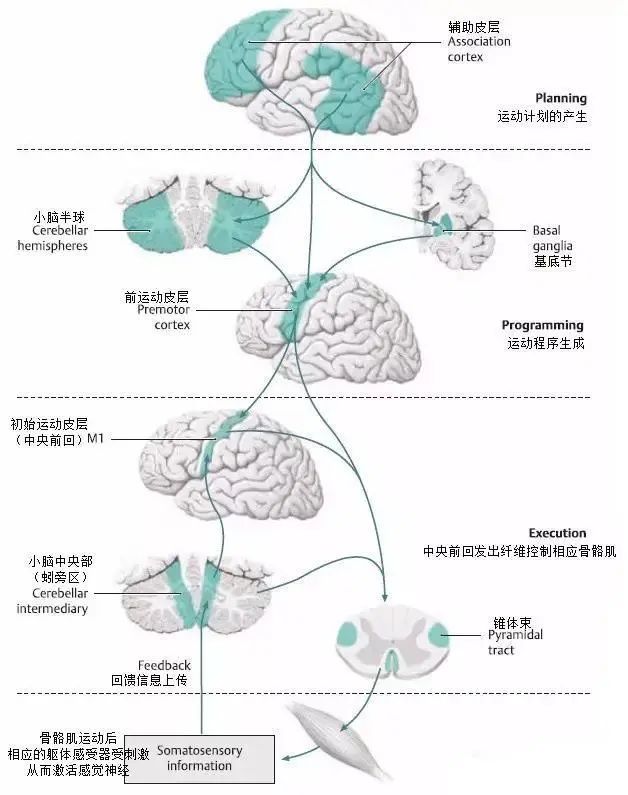
神经结构层面,海马体被认为是构建“时空认知地图”的核心部位。海马体中的“地点细胞”对特定环境位置敏感,“时间细胞”则在序列事件中随时间点触发。
这些细胞共同编码空间和时间信息,使海马体能够将不同事件的时空关系学习并存储,形成一个覆盖环境与经历的“记忆空间”。
纹状体基底节在动作序列和时序决策中发挥重要作用:通过强化学习机制选择和调整行为,参与毫秒到秒级时长区间的时间估计;而小脑则在精细运动协调和内部定时中占主导地位,其神经活动通常在动作前启动,以预测和调节时序。
七、具身认知闭环
对比可见,人类具身智能整合视觉、听觉、触觉、前庭和本体感受等多种感觉通道;Cosmos-Reason1 则仅利用视觉(视频帧)和文本提示。
人类通过自主运动产生连续反馈,实时更新内部模型;而 Cosmos-Reason1 并不具备自主运动或触觉输出,其“行动”仅限于在文本中生成下一步建议,无法与物理环境交互并获得即时反馈。
人类感知-运动闭环允许实时校正感知偏差,而 Cosmos-Reason1 的推理建立在静态视频信息上,缺少动态反馈机制。
人脑采用并行神经网络方式,直觉式结合经验与预测;Cosmos-Reason1 则通过 Transformer 的逐步注意力计算与长链思维显式推理,依赖预训练知识和输入提示逐步决策。

在时空感知上,人类往往快速、无意识地完成感知—决策循环;Cosmos-Reason1 则需要显式链式推理,输出解释性答复。
或许相似之处在于二者都需要将感知信息映射为环境模型并指导行动规划,但 Cosmos-Reason1 侧重“物理常识”的显性编码,而人类则更依赖长时记忆和多感官融合。
人类大脑能够自然感知时间流逝并预测未来事件,部分由海马体(时间细胞)与其他脑区共同完成。Cosmos-Reason1 虽然在训练中编码了时间本体知识,但其“时序”理解限于视频帧中显式观察到的动作序列,缺乏持续的内在时间感。
也就是说,人类可以在没有外界视觉信息的情况下通过经验估计时间,而Cosmos-Reason1主要通过视频片段中的时间线索和物理规则来推理顺序关系,这是相当局限和脆弱的时空关系。
可以看到,目前的具身智能,“感官”相对单一,其敏感度与内在协调性与人类还不可同日而语。且不谈高度精密协同的感官系统,仅传感器本身都还是关键瓶颈。
现在的具身机器人也还没有类似“海马体”提供的宏观的时空映射和记忆,没有基底节与小脑可以通过学习、预测和校准实现对时间间隔与运动模式的精细控制。
丰富的感官与复杂精密的神经结构协作,才使得具身智能体能够在复杂环境中精准感知时空并做出相应行动。缺少这些,揠苗助长跑马拉松,大家知道发生了什么。
八、具身智能的星辰大海
前路漫漫、任重道远,然而具身智能已然成为人工智能行业共同的星辰大海。
前有谷歌 DeepMind Gato,一个多模态、多任务的序列模型,可处理图像、传感器状态和文本等的输入,并输出文本或连续动作。
Gato 可在多种“具身”环境中感知和行动,但其对时空关系的理解主要依赖大规模数据中的模式,对未见过的物理常识泛化推理能力有限。

继而有Tesla Optimus,一个现实中的双足人形机器人,配备了摄像头、传感器和自主运动执行器。估计采用了与特斯拉自动驾驶类似的视觉神经网络和强化学习。
Optimus 的时空感知能力与自主导航相关联,能够基于视觉和惯性信息在真实环境中行走和操控物体;但在高级时空推理和物理理解方面,仍处于基础任务演示阶段,尚不具备复杂规划能力。

还有波士顿动力的 Atlas 机器人,以高超的运动控制著称,其核心是基于强化学习和控制理论训练的动力学模型。
也有尝试将LLM用于指导 Atlas 的高层决策,利用自然语言指令生成运动计划,使得 Atlas 能够在语义层面“理解”任务,但仍需依赖底层的物理控制算法执行动作。
综上可见,Nvidia此次推出的Cosmos-Reason1在构建物理世界的时空模型方面专注于“知识驱动的推理”,输入依赖预录视频和文本提示,缺乏真实世界交互和多模态反馈,难以像人类或高级机器人那样在连续的物理环境中自主学习和修正时空模型。
其他具身系统实现了运动与感知融合,可在实时环境中建图、导航,或通过强化学习获得运动技能。但其依赖的数据或算法并非为深层次的时空推理设计,对物理世界的理解依赖任务特定的训练。

笔者判断,未来提升具身时空感知的关键,在于将大模型的推理能力与真实感官--动作回路有效结合,以实现在物理世界中,实时多感官交互的高效协同,做精准的时空推理。

推荐阅读





×
右键可直接复制图片