
 阅读时间大约10分钟以上(6532字)
阅读时间大约10分钟以上(6532字)
2025-06-27 全面盘点!从开源整机、开源数据集到开源大模型,谁是最强王者?
来源:广汽GoMate
本文将深入剖析国内具身智能的开源生态,对代表性项目进行横向测评。
作者:余柯 出品:机器人产业应用
具身智能作为人工智能领域的前沿方向,正通过与物理世界的深度融合,加速迈向通用人工智能(AGI)。中国在这一领域展现出强大的创新活力,特别是在开源整机、开源数据和开源大模型方面取得了显著进展。本文将深入剖析国内具身智能的开源生态,对代表性项目进行横向测评,揭示其技术特点、发展趋势及面临的挑战与机遇,为行业发展提供洞察。
具身智能的发展历程与核心挑战
具身智能的理念萌芽于人工智能早期的符号主义与连接主义范式,不过其真正的蓬勃发展却是得益于当下大模型、多模态技术、强化学习以及机器人硬件的协同共进,特别是视觉 - 语言 - 动作(VLA)模型横空出世,助力机器人更为精准地解析语言指令、洞察视觉环境,进而输出恰当动作。
纵然进步飞速,但具身智能依旧身陷多重技术困境:
1.数据稀缺与质量挑战
具身智能对于海量、优质、多模态(包含视觉、语言、动作等)数据渴求强烈,可与大语言模型能倚仗海量文本数据的境况不同,具身智能在真实世界里采集数据成本高、耗时漫长,数据量也稀缺得可怜。
有专家直言,具身智能的训练数据与文本数据存在 “百万倍的落差”。拿自动驾驶来说,每天都能回流上亿条数据,反观具身智能领域,当下最大的数据集规模才百万条级别。
在真实数据采集如此艰难的情形下,合成数据技术正呈井喷式增长,已然成为具身智能 “冷启动” 阶段以及规模化训练的关键凭借。
合成数据是依靠生成式人工智能技术与模拟 “创造” 出来的,可以快速、低成本地批量产出大规模训练数据。
上海 AI 实验室的 “虚实贯通” 技术体系就是一个典型, 它可以仿真数据高效收集,再到模型部署的闭环流程。该体系可以让数据生产效率大幅攀升,成本则锐减。
银河通用的 GraspVLA 模型便是鲜活案例,它完全凭借十亿帧的合成大数据完成预训练,还能在真实世界里实现零样本泛化抓取。

|银河通用的 GraspVLA 模型
这就明明白白地说明合成数据不只是真实数据的 “跟班”,而是能成为基础模型预训练的主要 “源头活水”,妥妥地破解了具身智能发展前期的 “冷启动” 难题,为后续大规模、低投入的模型训练筑牢根基。
未来,具身智能的数据模式有望从单纯依赖真实数据,朝着“合成数据主导预训练,搭配真实数据精调验证” 的混合路径转变,模型的迭代速度与泛化能力都将借此得到显著提速。
2.算力与硬件瓶颈
当前的具身大模型往往包含数十亿甚至万亿参数,这对计算资源与数据吞吐量的要求极为苛刻。现有的通用计算硬件,例如 CPU、GPU 等,在实现实时响应(即延迟需控制在毫秒级)、保持低功耗以及确保成本合理等多重要求时,显得力不从心,尤其是在边缘端部署时。
这里的边缘端,指的是在靠近数据源头或用户端的本地设备上进行计算,而非在遥远的数据中心。各大企业一直在为具身智能本地端运算努力,如近日谷歌发布的 Gemini Robotics On - Device 模型,能在本地运行,摆脱网络束缚,在多项测试中表现出色,还支持开发者微调。

|谷歌发布的 Gemini Robotics On - Device 模型
鉴于边缘端算力不足,具身智能领域催生出硬件与软件协同设计的新模式。以深圳市人工智能与机器人研究院(AIRS)的 AIRSTONE 项目为例,其核心在于针对机器人特定任务负载设计定制化加速器,并运用开源 FPGA 设计,以此突破边缘端计算瓶颈。
这凸显了一个事实,即单靠提升通用硬件性能已无法满足具身智能的发展需求。必须从底层硬件架构及软件层面进行协同优化,研发专用芯片或加速器,以实现边缘计算的低功耗与高实时性。
3.新学习理论与泛化能力
具身智能的复杂性需要新的AI学习理论来支持其在复杂、动态的真实环境中进行高效学习和泛化,而非仅仅依赖静态学习范式 。如何让机器人从有限的经验中快速学习并泛化到未知的任务和环境,是当前研究的重点。
如谷歌的 Gemini Robotics是基于多模态通用大模型 Gemini 2.0 构建的视觉 - 语言 - 动作(VLA)模型,它能基于少量示例就提高执行复杂灵巧双臂任务(如折叠衣物)的能力,任务完成率相比 Gemini 2.0 大幅提升,展现出强大的零样本泛化能力,可直接用于机器人控制,包括物体检测、轨迹生成等。
由智元发布的首个通用具身基座模型——智元启元大模型(Genie Operator - 1)(简称GO-1)开创性地提出了 Vision - Language - Latent - Action(ViLLA)架构。该模型借助人类和多种机器人数据,让机器人获得了革命性的学习能力,可泛化应用到各类的环境和物品中,能在极少数据甚至零样本下泛化到新场景、新任务,降低了具身模型的使用门槛。
国内开源具身智能整机:实体载体的开放创新
中国在具身智能硬件领域积极推动开源,旨在降低开发门槛,加速技术普惠,并涌现出多个具有代表性的开源整机项目。这些项目通过开放硬件设计、物料清单和控制代码,吸引了广泛的开发者社区参与,共同推动具身智能的迭代与应用。
2.1
国内开源整机项目概览
青龙 (OpenLoong)
由国家地方共建人形机器人创新中心于2024年7月推出,是全球首个全尺寸开源工版人形机器人。
它身高1.85米,体重80公斤,整机集成43个主动自由度,在头部、手部、臂部、腿部、腰部和踝部实现了精妙设计 。
青龙搭载了400 TOPS高算力的具身智能控制器,并集成了“视、听、触、嗅、动”五感融合设计,使其能够深度感知周围环境,与外界实现更加自然、智能的交互 。
其电源系统具有能量回收和输出稳压管理功能,可连续工作3-4小时 。该项目的开源范围广泛,包括本体、数据集和运动控制等技术成果,旨在面向行业开放,加速人形机器人真正进入人类生活 。

| 青龙机器人
智元灵犀X1/X2
智元机器人作为国内人形机器人头部企业,已开源其灵犀X1的整机结构图纸、物料清单(BOM)和运控算法代码。
灵犀X1身高1.33米,体重约33公斤,拥有32个主动自由度,配备8个环绕式摄像头、6自由度灵巧手以及六维力传感器和高精度触觉传感器,以实现精准灵活的动作和对力的微小变化感知 。
而灵犀 X2 身高 1.65 米,体重 55 公斤,主动自由度达 42 个,拥有 12 个视觉传感器、70 多个触觉传感器、20 多个六维力传感器和 3 个 IMU 传感器,且实现了机械本体、灵巧手等全栈开源。
与X1相比,灵犀 X2 尺寸更大、体重更重、自由度更多,运动灵活性和动作复杂度更具优势,能完成更精细多样的动作。其传感器数量和种类远超 X1,对环境和自身状态的感知监测能力更强,复杂环境适应反应能力更佳。且 X2 全栈开源,为开发者提供全面支持,推动人形机器人技术发展。

|灵犀X1机器人
傅利叶N1
傅利叶智能于2025年4月11日发布了其首款开源人形机器人N1。
N1身高1.3米,体重38公斤,拥有23个自由度,最高稳定奔跑速度可达3.5米/秒,并能通过15°-20°坡度斜坡,攀爬20厘米高的楼梯,甚至完成撑地爬起等动作 。
傅利叶智能提供了完整的开源资料,包括物料清单、设计图纸、组装指南和基础操作软件,旨在通过“乐高式”模块化方式降低开发门槛,吸引更多开发者和研究机构参与创新 。

|傅利叶N1机器人
优必选偃师 (Yanshee)
偃师是一款面向K12、中高职、高校学生的开源人形机器人教育平台。
它拥有17个自由度,搭载800万像素高清摄像头,支持人脸检测、物体识别等离线AI模型,并具备智能语音功能。
其开放硬件平台基于Raspberry Pi 3B + STM32,提供丰富的接口和API,支持多种编程语言和虚拟仿真环境(如Gazebo、Webots),旨在帮助学生学习AI、编程和机器人运动相关知识 。

|优必选偃师机器人
广汽GoMate
广汽集团于2024年12月26日发布了第三代具身智能人形机器人GoMate。
这是一款全尺寸的轮足人形机器人,全身拥有38个自由度,创新性地采用了行业首创的可变轮足移动结构,可融合四轮足和两轮足两种模式,以适应不同场景的需求 。
GoMate在硬件上实现了灵巧手、驱动器、电机等核心零部件的完全自研,并在软件层面融入了自研纯视觉自动驾驶算法和云端多模态大模型,能够毫秒级响应人类语音指令 。
虽然广汽GoMate未明确开源整机硬件,但其在软件层面针对特定应用场景调优开源大模型的做法,显示出与开源生态的紧密结合 。

|广汽GoMate机器人
具身智能开源整机正从教育科研走向工业应用,加速商业化落地。传统上,开源机器人主要面向教育科研场景 。然而,青龙被明确定义为“工版”人形机器人,并计划进入汽车工厂参与搬运、检测等任务 。傅利叶N1的开源目标也包括吸引更广泛的开发者,探索更多应用 。
这表明国内开源整机项目正在超越单纯的学术和教育范畴,积极探索工业和商业应用场景,通过开源加速技术成熟和市场验证。开源硬件的成熟度正在提升,其目标用户群体和应用场景将更加多元化,为具身智能的商业化落地提供了更广阔的平台。
硬件模块化与软件开放性是开源整机成功的基石。青龙项目强调其“关键模组”和“通讯系统充分兼顾模块化和扩展性” 。傅利叶N1则通过“乐高式”模块化方式降低开发门槛 。优必选偃师采用“开放式硬件平台架构”并提供API接口。这些设计理念与多语言编程支持、ROS兼容性等软件开放性特征相结合,共同促进了“二次开发”的便利性。
成功的开源整机项目不仅要公开设计,更要通过模块化设计降低硬件组装和软件开发的复杂度,从而真正激发社区的创新活力。具身智能开源整机的未来将是硬件高度模块化、软件接口标准化的生态系统,这将大大加速新功能和新应用的开发与集成。
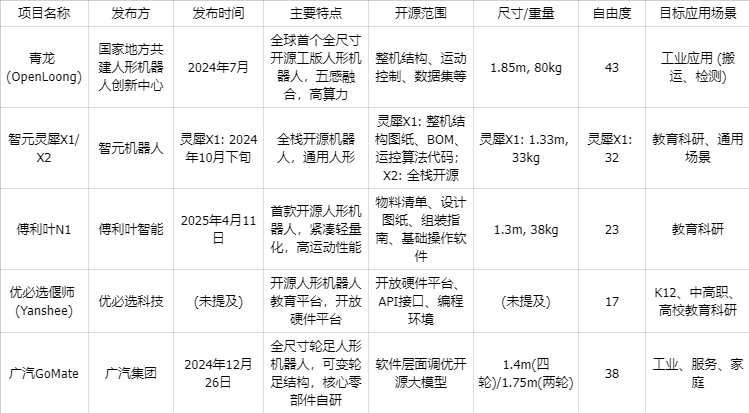
|国内开源具身智能整机项目对比
国内开源具身智能数据:破解“数据荒”的关键
3.1
数据在具身智能中的核心地位
在具身智能领域,数据是发展基石。具身智能依靠智能体与环境交互实现感知、决策与行动,高度依赖大量优质数据。与大语言模型不同,具身智能难以获取现成数据,“数据荒”问题突出。
国内积极探索破解之道。智元机器人联合上海人工智能实验室发布 AgiBot World 数据集,为全球首个百万级真实场景机器人数据集,覆盖家居、工业等五大核心场景,涵盖八十余种生活技能,并建立严格质量控制体系。
国家地方共建具身智能机器人创新中心与北京大学推出 RoboMIND 数据集,采用多形态机器人采集数据,适配复杂场景训练,还牵头立项首个具身智能数据采集行业标准。这些开源数据项目,正为突破 “数据荒”、推动具身智能发展提供关键支撑。
3.2
具身智能数据集的“ImageNet时刻”
随着具身智能的不断发展,具身智能领域正迎来其“ImageNet时刻”,即大规模、高质量数据集的涌现,为模型训练提供了前所未有的“养料”。这些数据集的开放,如同当年ImageNet对计算机视觉领域的推动作用,正加速具身智能技术的进步。
智元AgiBot World
智元机器人联合上海AI实验室等机构开源的百万级真机数据集,被誉为具身智能领域的“ImageNet时刻” 。
该数据集包含超过100万条演示轨迹,覆盖家居、餐饮、工业、商超、办公五大核心场景,任务多样性高,从抓取、放置等基础操作到搅拌、折叠等复杂动作均有涵盖 。其长程数据规模是Google Open X-Embodiment数据集的10倍,场景覆盖面扩大100倍,数据质量从实验室级上升到工业级标准 。
宇树G1操作数据集
基于G1 人形机器人构建,聚焦精细操作与复杂环境交互任务。包含五类典型操作场景,覆盖家庭与工业场景的基础技能,包括日常操作、工具使用和复杂装配。宇树不仅开放数据集,还同步开源采集代码、训练框架及硬件配置说明,形成 “数据 + 工具链 + 算法” 的完整技术包。
上海交通大学RH20T
该数据集由上海交通大学发布,包含超过40TB的数据,涵盖数百万对“人类演示-机器人操作”数据,并融合了视觉、力觉、听觉和运动信息。
RH20T选择了来自RLBench、MetaWorld的48和29个任务,并引入了70个自创任务,为机器人操作学习提供了丰富且多样化的资源 。
北京人形机器人创新中心RoboMIND
作为全国首个通用具身智能数据集和Benchmark(基准测试),RoboMIND实现了跨异构机器人平台的统一数据规范,解决了多构型机器人数据兼容的技术难题 。
目前,该数据集已包含10.7万条高质量操作轨迹,涵盖479种任务场景和96类物体交互,预计年底将扩展至30万条规模,堪称目前全球最完备的机器人操作数据库之一 。
国内数据集呈现“真实世界规模化”与“合成数据主导”双轨并行趋势。智元AgiBot World强调其“百万级真机数据集”和“工业级标准”,代表了真实世界数据规模化的努力 。与此同时,银河通用GraspVLA则完全依赖“十亿帧合成大数据”进行预训练 。
这种现象并非矛盾,而是反映了国内在数据策略上的双重押注:一方面努力克服真实数据采集的困难,追求高质量、大规模的真机数据;另一方面则在合成数据生成和应用上取得突破,以实现更广阔的泛化能力。
这种双轨并行策略将加速具身智能的发展,合成数据提供广度,真实数据提供深度,两者互补将推动具身智能模型更快地走向实用化。
数据集标准化和互操作性成为构建开放生态的关键。北京人形机器人创新中心的RoboMIND更是实现了“跨Franka、UR5e、AgileX、TienKung四大异构机器人平台的统一数据规范” 。
这表明行业已认识到,数据碎片化是制约具身智能发展的瓶颈。通过制定统一的数据标准和接口,可以促进数据集的共享、模型的复用和跨平台泛化,从而加速整个生态系统的发展。
未来具身智能领域将出现更多跨机构、跨平台的标准化数据集项目,这将是构建真正开放、协作的具身智能生态的关键一步,并有助于中国在全球具身智能标准制定中发挥更大作用。
|国内开源具身智能数据集对比
国内开源具身大模型:赋能具身智能的“大脑”
4.1
具身大模型:VLA模型与决策智能
具身智能数据集是具身大模型训练的基础。而具身大模型是赋能具身智能“大脑”的核心。
数据支撑模型训练:数据集为模型提供场景、动作、物体关系等训练数据,是模型学习认知、规划能力的基础。
塑造模型核心能力:特定数据集(如 CAN-DO 的指令规划数据、MMDL 的家庭活动数据)助力模型提升环境理解、任务规划、人机交互等能力。
驱动模型优化迭代:通过数据集(如 MFE-ETP)评估模型在对象理解、时空推理等维度的表现,发现缺陷并优化,推动模型发展。
模型反推数据进化:模型能力提升会要求数据集更具多样性、复杂性(如覆盖更多现实场景),促使数据规模、质量持续升级。
大模型所具备的“规模大、涌现性、通用性”三大特点,使其成为驱动具身智能从感知、理解到决策、控制全流程智能化的关键 。如腾讯AI Lab聚焦于“决策智能”的研究。
具身大模型中视觉-语言-动作模型(VLA)扮演着关键角色。VLA模型能够处理来自视觉、语言和动作模态的信息,使机器人能够理解自然语言指令、感知环境并生成相应的物理动作。这种多模态能力使得机器人能够从简单的重复任务转向更复杂的、需要理解和决策的任务。
相比传统的深度强化学习方法,VLA模型在复杂环境中的通用性、灵活性和泛化能力显著提升 。它们不仅能用于生成低级控制动作,也能作为高级任务规划器进行任务分解,实现“大小脑协同”。例如,一个VLA模型可以接收“整理房间”的指令,然后将其分解为“拿起散落在地的衣物”、“将衣物放入洗衣篮”等子任务,并为每个子任务生成具体的机器人动作序列。
4.2
典型开源具身大模型及平台项目
1.基础模型类:多模态感知与任务规划
RoboBrain 2.0(智源研究院)
开源具身大脑模型,专注空间推理与多机协同。
任务规划准确率较1.0提升74%,支持动态场景图构建与跨本体调度;全链路响应延迟<3ms,端云通信效率提升27倍
GraspVLA (银河通用)
银河通用发布了全球首个完全基于合成大数据预训练的端到端具身抓取基础大模型GraspVLA,其训练数据量达到十亿帧“视觉-语言-动作”对 。该模型通过合成数据预训练,实现了在真实世界中的零样本泛化抓取能力,并已成功应用于24小时无人药店,由机器人完成5000多种药品的取货和打包 。
2.运动控制类:自然语言驱动动作生成
龙跃 MindLoongGPT(复旦大学 & 国地中心)
全球首款生成式人形机器人运动大模型,支持文本/语音/图像驱动动作生成。
能够进行时序一致性优化,解决长序列动作僵硬问题,舞蹈/跑步拟真度媲美真人。
采用轻量化设计,模型体积压缩至同类1/3,适配嵌入式设备实时部署
3.空间认知类:物理世界模拟与合成
SpatialLM(群核科技)
开源的空间理解多模态大模型,专注于将大语言模型(LLM)的能力扩展至 3D 空间理解领域,旨在赋予机器类人般的空间认知、推理与交互能力。
通过整合多模态感知(如视频、点云)与结构化建模技术,首次实现了 LLM 对 3D 空间的语义解析。
能够将现实世界的场景转化为虚拟环境中的可交互 3D 模型,为机器人训练提供海量合成数据。
从基础通用到专项突破,从 单点突破 走向 全栈协同,中国具身智能开源生态呈现多层次、协同发展的特点。国内的开源项目覆盖了具身智能栈的各个层面。同时,许多项目都强调与高校、科研机构和企业的深度协同创新 ,共同构建“开源社区” 。
这表明国内具身智能的开源生态并非单点突破,而是形成了一个多层次、分工明确、相互协作的复杂系统,通过集智攻关来加速整体发展。这种协同发展模式有助于集中优势资源,克服单一机构的局限性,从而在具身智能这一复杂领域取得更快、更全面的进展,并有望在全球竞争中形成独特优势。
结语:精密制造的国产突围样本
尽管国内具身智能开源生态蓬勃发展,但仍面临数据、软硬件等多重挑战:
·数据鸿沟:真实数据体量不足且采集成本高,合成数据需突破 “虚实鸿沟”,Sim-to-Real 技术(领域随机化、自适应学习等)是关键。
·软硬件协同与算力瓶颈:通用硬件难平衡实时性、低功耗与算力需求,亟需定制化硬件加速器及跨学科协同的软硬件设计。
·标准化与互操作性:缺乏统一的硬件接口、通信协议及机器人操作系统标准,碎片化阻碍生态合力,标准化建设是提升国际话语权的国家战略。
·开源社区管理与商业模式:需解决社区激励、知识产权保护及开源商业化路径问题。
·新学习理论缺失:现有理论难以支持具身智能在动态环境中的持续学习与泛化,需突破传统静态学习范式。
发展机遇与未来展望
·政策支持:国家将具身智能列为战略性新兴产业,通过 “人形机器人创新中心”“天工开源计划” 等推动技术研发与应用。
·市场需求与场景落地:工业制造、医疗康复等领域需求广阔,如 GraspVLA 在无人药店、“天工” 机器人在汽车工厂的商业化应用,为技术迭代提供数据支撑。
·产学研协同创新:智元 AgiBot World、RoboMIND 数据集等项目由高校、科研院所与企业联合推进,加速科研成果转化。
结语:精密制造的国产突围样本
展望未来,具身智能将朝着通用化、智能化、普惠化发展。
随着合成数据技术与仿真平台成熟,“数据荒”将得到缓解,模型训练效率显著提升。
硬件加速器和专用芯片的突破,能有效解决边缘算力瓶颈,推动具身智能机器人广泛落地。统一操作系统和开发框架的出现,将降低开发门槛,助力繁荣开源生态。
未来5-10年,具身智能有望承担人类不愿从事或危险的工作;到2045年,甚至可能肩负星际探索重任。中国具身智能领域的开源发展,正加速技术进步,为实现通用人工智能筑牢根基。

推荐阅读





×
右键可直接复制图片