
 阅读时间大约10分钟以上(4259字)
阅读时间大约10分钟以上(4259字)
2025-07-03 谷歌具身智能VLA模型RT-2—— 将互联网知识迁移至机器人控制
来源:豆包
将在互联网规模数据上训练的视觉-语言模型,直接整合到端到端的机器人控制中,以增强泛化能力并实现涌现的语义推理。
作者:陈康成 出品:机器觉醒时代
引言
视觉语言模型的语义推理、问题解决和视觉理解能力对需要在真实环境中执行多种任务的通用机器人而言极具价值。然而,机器人应如何获取此类能力尚不明确。
受大语言模型发展的启发,理论上可通过大规模机器人数据训练使机器人大模型具备类似大语言模型的Scaling Law能力;然而从现实来看,短期内获取此类大规模数据仍面临较大挑战。
上面的方法行不通,退而求其次,是否能够去借用现有的大语言模型或者视觉语言模型的能力,即把后者的一些能力直接迁移到机器人上?事实上,这也是一个难题。困难在于大语言模型或者视觉语言模型处理的是语义、标签和文本提示,而机器人需要的是具身的低层级动作,例如笛卡尔末端执行器命令。
当前LLM或VLM 与机器人技术的融合研究多聚焦于高层任务规划,其核心机制类似 “状态机”—— 通过解析指令生成 “原子动作序列”(如物体抓取 - 移动 - 放置),而底层运动控制仍依赖独立训练的低级模块。这种“语义 - 控制”的分层架构存在根本局限:低级控制器未能共享大规模预训练模型的语义知识,导致机器人在复杂环境中难以实现跨任务的知识迁移。
那么,能否将在互联网规模数据上训练的视觉-语言模型,直接整合到端到端的机器人控制中,以增强泛化能力并实现涌现的语义推理?
谷歌DeepMind探索出了有效方法:直接训练面向开放词汇视觉问答和视觉对话而设计的视觉-语言模型,使其在解决其他互联网规模视觉语言任务的同时,也能输出低层级的机器人动作。
具体做法是:通过在机器人动作轨迹上训练视觉语言模型,将动作序列转化为文本标记,并创建“多模态语句”。这些语句通过生成相应的动作序列来“响应”与相机观察配对的机器人指令。通过这种方式,视觉语言模型可以被直接训练成遵循指令的机器人策略。
谷歌在论文《RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control》中给出了明确的答案。
2023年7月,谷歌DeepMind发布具身智能VLA模型RT-2。RT-2将机器人动作视为另一种语言,将机器人动作映射为文本标记并与互联网规模的视觉-语言数据集共同训练。
在推理过程中,文本标记被解码为机器人动作,从而实现闭环控制。利用视觉语言模型的主干架构和预训练能力来学习机器人策略,将其泛化能力、语义理解以及推理能力的一部分迁移至机器人控制上。
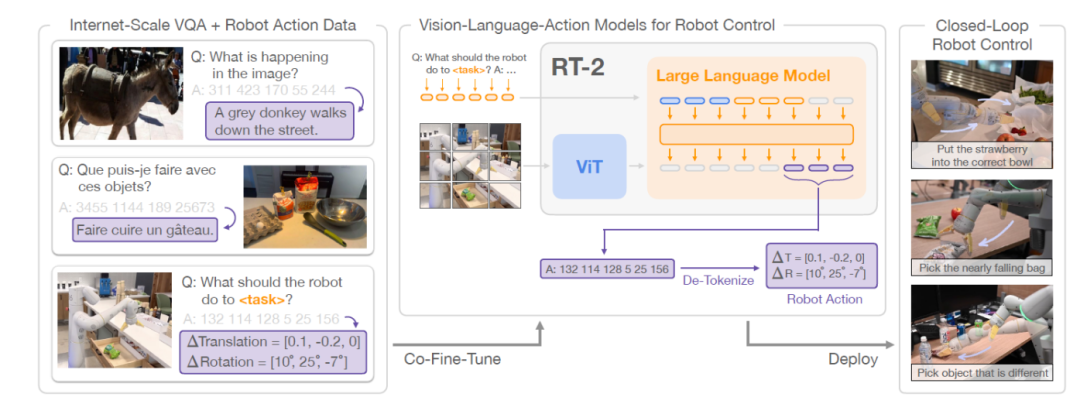
RT-2模型工作流程
一、具身智能VLA模型
为实现视觉语言模型对机器人的控制,需将其训练为可输出动作指令的视觉语言动作(VLA)模型。在该论文的研究中,谷歌基于两种现有视觉语言模型——PaLI-X 和 PaLM-E,分别构建了对应的VLA 模型实例:RT-2-PaLI-X 与 RT-2-PaLM-E。
采用方法:将动作表征为模型输出的标记(Tokens),其处理方式与语言标记完全一致。动作编码采用与RT-1相同的离散化方案。
动作空间包括:
机器人末端执行器的6自由度(6-DoF)位置和旋转位移;
机器人夹爪的开合程度;
一个用于终止任务片段(episode)的特殊离散指令(该指令应由策略触发以表示任务成功完成)。
连续维度(除终止指令外)被均匀地离散化为256个bins;机器人动作可以用这些离散bins的序数表示为8个整数值。
模型微调的关键步骤在于建立模型现有词汇表与离散动作空间之间的映射关系。为此,需要预先保留256 个标记(tokens)作为专用的动作标记。具体选择哪些标记作为动作标记,取决于所使用的视觉语言模型(VLM)的分词方案:
PaLI-X:由于其分词方案为每个不超过 1000 的整数分配了唯一的标记,因此可直接将 action bins 映射到对应的整数标记上。
PaLM-E:该模型的分词方案不包含数字的直接表示,因此需要覆盖词汇表中 256个使用频率最低的标记,将它们重新定义为动作词汇表。
1)联合微调
实验表明,提升机器人性能的关键训练技巧在于:将机器人数据与原始网络数据进行联合微调,而非仅对机器人数据实施简单微调。联合微调能生成泛化能力更强的策略,因为在此过程中策略,同时接触网络规模数据的抽象视觉概念和微调过程中的低层级机器人动作,而非仅局限于机器人动作。
具体实现中,谷歌DeepMind通过提高机器人数据集的采样权重,平衡每批次训练数据中机器人数据与网络数据的比例。
2)输出约束机制
RT-2 与标准视觉语言模型(VLM)的核心区别在于:RT-2必须输出有效的动作token才能在真实机器人上执行。
为确保RT-2 在解码过程中输出有效动作标记,通过以下方式约束其输出词汇表:
机器人动作任务场景:当模型接收到机器人动作任务提示时,仅允许采样有效的动作tokens。
标准视觉语言任务:模型则仍然被允许输出所有可能的自然语言tokens(如问答、图像描述等)。
3)实时推理
谷歌开发了一种协议(protocol),通过将RT-2模型部署在多TPU 云服务中,并通过网络查询该服务,使其能够在机器人上运行 RT-2 模型。通过这种解决方案,谷歌不仅能实现合适的控制频率,还能通过同一云服务为多台机器人提供支持。
谷歌评估的最大模型,即550亿参数的 RT-2-PaLI-X-55B 模型,可以以 1Hz~3 Hz的频率运行。该模型的一个较小版本,包含 50 亿参数RT-2-PaLI-X-5B,可以以大约5Hz的频率运行。
二、RT-2研究实验验证
实验内容主要针对以下四个问题展开:
1)RT-2 在已见过的任务上表现如何,以及它对新物体、背景和环境的泛化能力如何?
2)能否观察并衡量RT-2 的任何涌现能力?
3)RT-2泛化能力如何随参数数量和其他设计决策而变化?
4)RT-2能否像视觉-语言模型那样展现出思维链推理的迹象?
1. RT-2实例化模型选择
在实验中,谷歌DeepMind训练了两种具体的RT-2实例化模型,他们基于预训练的视觉语言模型(VLMs)构建:
RT-2-PaLI-X:基于5B和 55B参数的PaLI-X模型构建。
RT-2-PaLM-E:基于12B参数的PaLM-E模型构建。
2. 基线模型选择
RT-1: 35M参数的Transformer模型
VC-1和R3M :训练RT-1的主干网络,将他们的表征作为输入。
MOO:使用视觉语言模型(VLM)创建一个额外的语义地图图像通道,然后将该通道输入到一个 RT-1 的主干网络中。
3. 模型训练所使用数据
大规模互联网数据:内容包括视觉问答(VQA)、图像描述、非结构化图文交织样本等。
机器人轨迹数据:13台机器人持续17个月采集的办公环境中的厨房场景数据(与RT-1训练所使用的数据相同)。
4. 实验内容评估
问题1:RT-2 在已见过的任务上表现如何,以及它对新物体、背景和环境的泛化能力如何?
1)对于分布内的已见任务:谷歌采用与RT-1相同的已见过指令集,本次评估包含200多项任务:36 项拾取物体任务、35项敲击物体任务、35项将物品竖直放置任务、48 项移动物体任务、18 项打开和关闭各种抽屉任务,以及36项从抽屉中取出物品并放入抽屉的任务。
然而,这些“分布内”评估仍然会改变物体的摆放位置以及时间、机器人位置等因素,要求技能能够泛化到环境中的实际变化。
2)对于分布外的未见任务:该泛化评估场景分为未见物体、未见背景和未见环境三大类,并一步将每类划分为简单和复杂两类。这些评估共包含超过280 项任务,主要聚焦于多种不同场景下的拾取与放置技能。

(a)未见物体 (b)未见背景 (c)未见环境
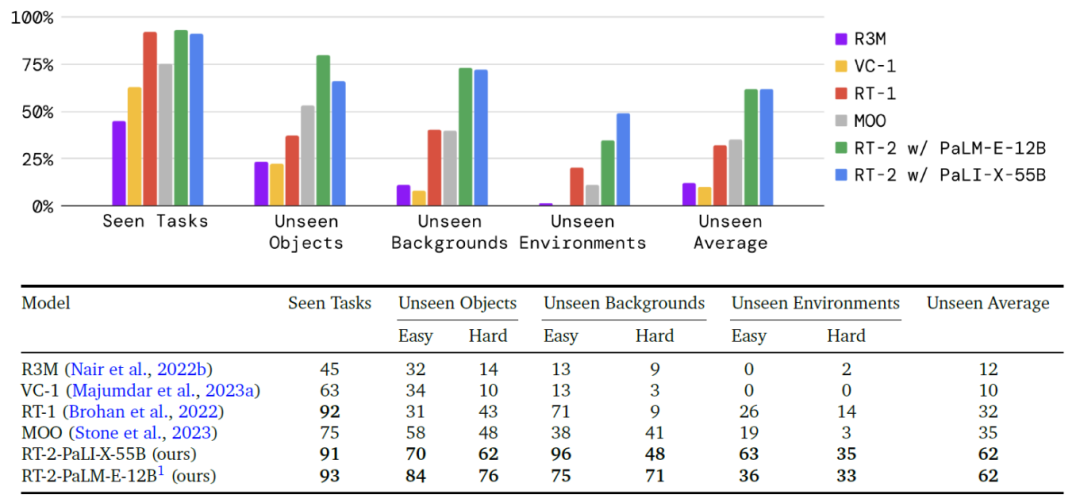
评估结果如下图所示:
RT-2模型与基线模型的泛化能力表现结果
1)在已见任务上,RT-2与RT-1表现相近,而其他基线模型的成功率较低。
2)在未见任务上,两种RT-2模型(PaLM-E-12B与PaLI-X-55B)整体泛化能力表现相近,但两者都明显优于其它基线模型,较次优的两个基线模型(RT-1 和 MOO)实现了约2倍的性能提升,较其他基线模型(VC-1和R3M)提升约 6 倍。
问题2:能否观测并量化RT-2的涌现能力?
该项评估分为定性评估和定量评估两大类型:
1)定性评估
选取RT-2-PaLI-X 模型进行实验测试,以确定其从视觉语言概念中迁移的多种涌现能力。研究发现,RT-2-PaLI-X在场景语义理解与基础推理方面展现出前所未有的能力:
语义关联推理案例:执行指令“将草莓放入正确的碗中”—— 要求模型不仅理解“草莓”和“碗”的实体概念,还需在场景上下文中推理出“草莓应与其他同类水果放置在一起”。
物理状态推理案例:执行指令“拾取即将从桌面掉落的袋子”—— 模型需区分两个袋子,并识别处于不稳定位置的物体。
上述案例中这些场景中测试的交互行为均未在机器人数据中出现过,这表明语义知识已从视觉- 语言数据中实现迁移。
2)定量评估
为量化这些涌现能力,选取两个基线模型(RT-1与VC-1)与两个RT-2模型(RT-2-PaLI-X和RT-2-PaLM-E)进行对比。为降低实验方差,所有方法均采用A/B测试框架进行评估——四个模型在完全相同的条件下依次执行测试。
谷歌将RT-2的涌现能力划分为三大类,涵盖推理与语义理解维度:

评估结果如下图所示:
RT-2与基线模型的涌现能力评估结果对比
1)两种RT-2模型在上述所有类别均显著优于基线模型,尤其是RT-2-PaLI-X模型的平均成功率超次优基线模型(RT-1)3倍以上。
2)两种RT-2的表现也存在差异:
较大模型RT-2-PaLI-X在符号理解、人物识别表现更优;
较小模型RT-2-PaLI-X在数学推理任务上占优;
可能原因在于PaLM-E预训练数据包含更多数学计算任务,而PaLI-X侧重视觉预训练。
问题3:RT-2的泛化能力如何随参数量级及架构决策变化?
实验选取两种不同参数规模(5B和55B)的RT-2-PaLI-X模型以及三种不同的训练流程进行对比分析:
从头训练模型(不使用VLM预训练的任何权重);
仅使用机器人动作数据对预训练模型进行微调;
联合微调(同时使用原始VLM 训练数据和机器人数据)。
评估结果如下图所示
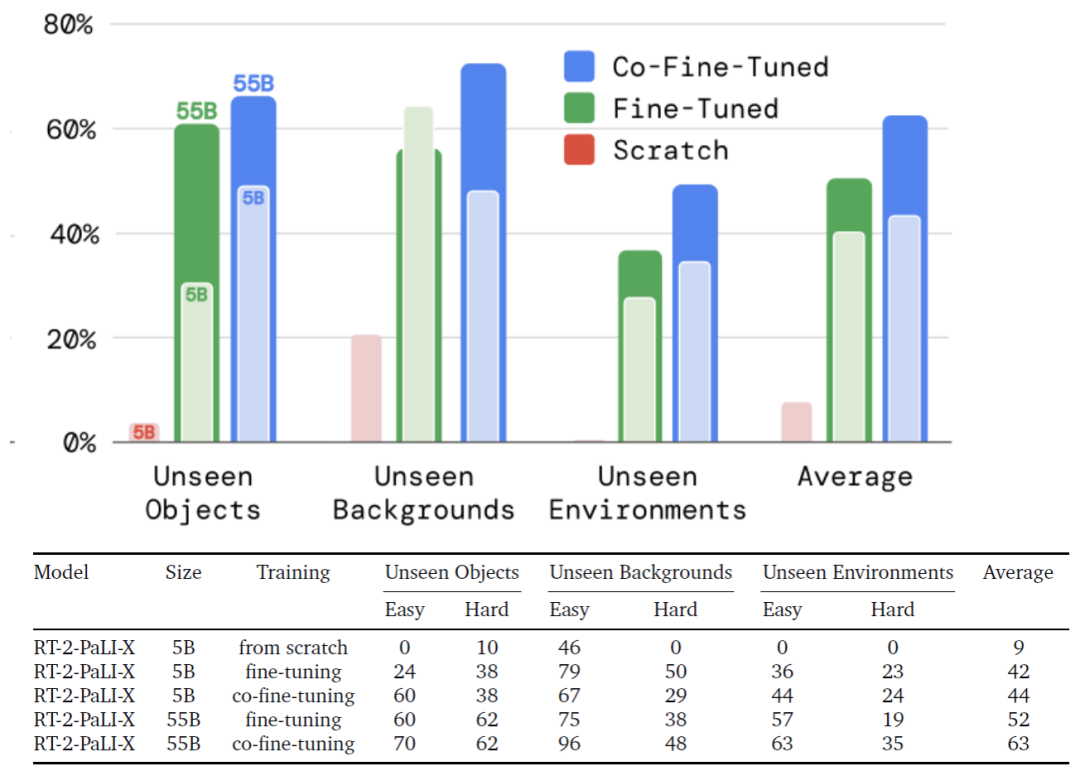
不同参数规模的RT-2模型的泛化能力对比
1)5B参数的PaLI-X模型,从头训练出的RT-2-PaLI-X模型性能非常差。基于此结果,实验中并未对55B的PaLI-X模型从头进行训练。
2)联合微调模型(无论规模大小)的泛化性能均优于仅用机器人数据进行微调的模型。谷歌研究人员认为这是因为在微调训练中保留了原始数据,可使模型不会遗忘在VLM 训练阶段学习到的先前概念。
3)模型参数规模的增加会带来更好的泛化性能。
问题4:RT-2能否展现类似视觉语言模型的思维链推理特征?
受大语言模型(LLMs)思维链提示法启发,谷歌研究人员对RT-2的PaLM-E变体进行仅数百步梯度更新的微调,以增强其联合利用语言与动作的能力,期望借此激发更复杂的推理行为。
数据增强方案:在训练数据中新增"规划/计划(Plan)"步骤:首先以自然语言描述机器人即将执行动作的目的,随后输出实际的动作标记(token)。
这一数据增强方案构建了视觉问答数据集(视觉推理)与操作数据集(动作生成)之间的桥梁。
从定性角度观察表明,具备思维链推理的RT-2能够响应更复杂的指令,因为模型可先在自然语言中规划动作意图。初步验证了将LLMs或视觉语言模型(VLMs)作为规划器与低层策略整合到单一视觉-语言-动作(VLA)模型的可行性。
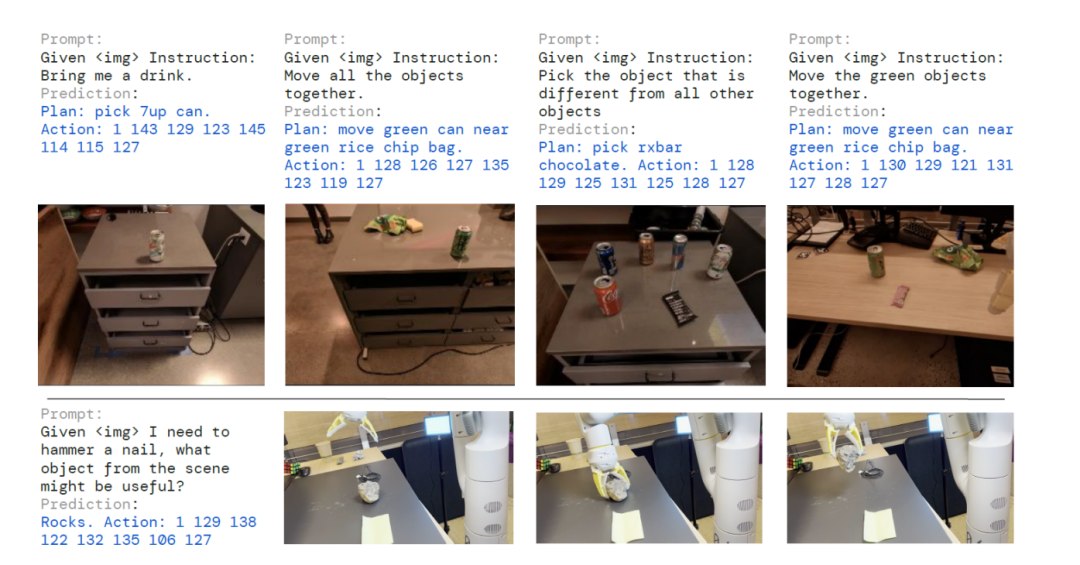
带有思维链推理RT-2会同时生成任务执行计划与具体动作指令
结语
论文阐述了如何通过结合视觉语言模型(VLM)预训练与机器人数据来训练视觉语言动作(VLA)模型。
谷歌DeepMind提出了基于PaLM-E和PaLI-X的两种VLA实现方案,分别命名为RT-2-PaLM-E和RT-2-PaLI-X。这些模型通过机器人轨迹数据进行联合微调,以输出表示为文本标记的机器人动作
研究表明,该方法不仅能生成高性能的机器人策略,更重要的是其泛化能力显著提升,并继承了大规模网络视觉- 语言预训练所赋予的涌现能力。
尽管RT-2展现出优异的泛化性能,该方法仍存在多重局限。
1)局限一:可用的开源VLM模型少
目前仅有少量可用于创建RT-2 的通用视觉 - 语言模型(VLM),期待更多开源模型及开放专有模型的微调API——这是构建VLA模型的必要条件。"
2)局限二:动作创新能力受限
首先,VLM通过网络规模预训练可提升语义与视觉概念的泛化能力,但机器人并未因包含这些额外经验而获得执行新动作的能力。
模型的物理技能仍局限于机器人数据中所见的技能分布,仅能创新性地组合已有技能。DeepMind认为这源于数据集的技能多样性不足所致。未来研究的关键方向是探索通过新数据收集范式(如人类操作视频)获取新技能。"
3)局限三:实时推理瓶颈
其次,尽管实现了大型VLA模型的实时运行,但其计算成本仍高昂。若应用于需高频控制的场景,实时推理将成为主要瓶颈。未来研究需探索量化和蒸馏技术,以提升模型速率或适配低成本硬件。

推荐阅读





×
右键可直接复制图片