
 阅读时间大约6分钟(2209字)
阅读时间大约6分钟(2209字)
2025-08-11 8校联合攻关!MUPA框架以多路径推理颠覆视频问答!20亿参数碾压70亿模型,刷新领域最优纪录!
来源:豆包
多模态大模型在视频问答(VideoQA)领域取得显著进展,成为推动人工智能系统跨模态理解能力的重要方向。
作者:陆柒 出品:具身智能大讲堂
近年来,多模态大模型在视频问答(VideoQA)领域取得显著进展,成为推动人工智能系统跨模态理解能力的重要方向。然而,尽管这些模型在回答准确率上取得了突破,现有方法普遍存在推理过程缺乏视觉证据支撑的问题,模型往往依赖语言偏见或训练数据中的伪相关性,难以实现真正意义上的“视觉对齐”。
在Grounded VideoQA任务中,这一现象尤为突出。Grounded VideoQA任务要求模型不仅回答问题,还需指出支撑答案的视频片段,兼顾准确性与可解释性。因此,如何提升模型在复杂视频内容中的证据感知能力,构建具备推理一致性与证据可信度的多模态系统,成为当前研究的热点与难点。
▍提出MUPA框架,表现刷新最优记录
针对上述挑战,由来自兰州大学、新加坡国立大学、中山大学、暨南大学、南洋理工大学、北京大学、中国科学技术大学和合肥工业大学的研究人员组成的研究团队进行了深入研究,并受多路径协同推理策略与元推理反思机制的启发,提出了一种面向Grounded Video Question Answering(Grounded VideoQA)任务的多智能体协同多路径推理框架——MUPA(Multi-Path Agentic)。
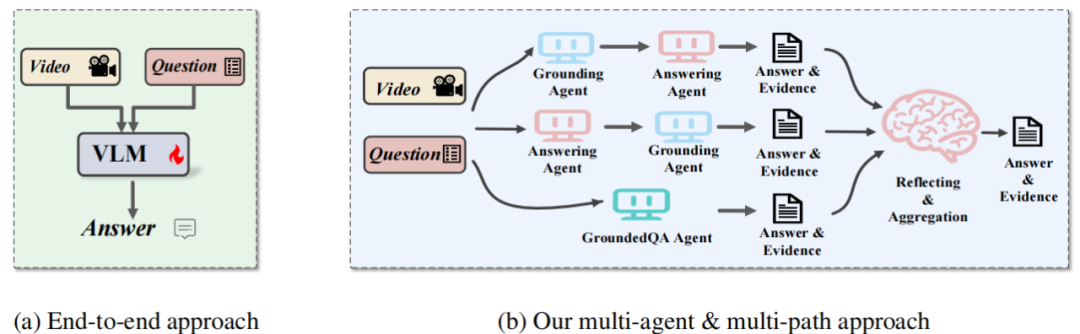
图1:端到端方法与本研究提出的多智能体多路径方法对比
该方法设计了三条具有时间顺序差异的推理路径,分别模拟“先定位后回答”、“先回答后定位”与“答案-证据联合生成”的三种推理策略,并引入反思智能体对候选“答案-证据”对进行一致性验证与置信度加权融合,从而最终输出准确且可信的回答结果。该框架可灵活适配多种任务需求,同时保持较低的系统复杂度。
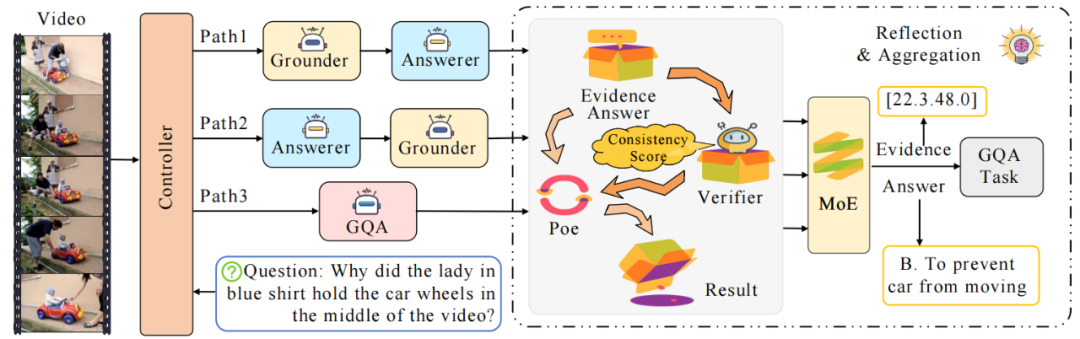
MUPA在多个主流视频问答数据集上表现出优异的性能。值得关注的是,其基础模型仅采用20 亿参数规模,却已全面超越所有 70 亿参数级别的对比方法;当模型扩展至 70 亿参数后,更在 NExT-GQA 和 DeVE-QA 两大数据集上分别实现 30.3% 和 47.4% 的 Acc@GQA 指标,刷新当前领域最优纪录。该方法通过有效增强模型的视觉对齐精度与推理可靠性,为Grounded VideoQA(锚定视频问答)向 “可解释、可验证” 的技术方向发展提供了有力支撑。
前不久该研究成果的相关论文预印本版本已以“MUPA: Towards Multi-Path Agentic Reasoning for Grounded Video Question Answering”为题发表在arXiv上(2506.18071)。党吉圣为第一作者,宋惠霖,肖俊斌,王笔美,彭涵,李昊轩,杨勋,汪萌,蔡达成共同作者。
接下来,和具身智能大讲堂一起来深入探索这一研究成果!
▍四智能体-三路径架构,确保可靠性
MUPA框架采用创新的"四智能体-三路径"架构,其核心思路是通过分工协作与交叉验证实现可靠的视频问答。
具体来说,MUPA框架包含四个关键智能体:
定位智能体(Answerer)
基于改进的VideoMind架构,配备时空金字塔编码器,可处理长达150帧的视频输入。其创新点在于引入<REG>特殊标记的跨模态注意力机制,能够同时学习视觉特征与文本查询的时空对齐。
问答智能体(Answerer)
采用Qwen2-VL作为基础模型,通过Chain-of-LoRA技术实现参数高效微调。特别设计了动态掩码注意力机制,可自适应关注关键视频片段。
联合智能体(Answerer)
共享视觉编码器但独立训练预测头,其创新之处在于双流特征交互设计:视觉特征通过3D卷积提取时空信息,文本特征则采用层次化注意力进行语义增强。
反思智能体(Reflectioner)
包含两个关键模块:基于对比学习的验证器(Verifier)和基于概率图模型的融合器(Fuser),前者计算答案-证据一致性分数,后者实现多路径决策融合。
在具体实现上,MUPA框架设计了三条具有互补性的推理路径,共同构成完整的“定位-问答-验证”闭环:
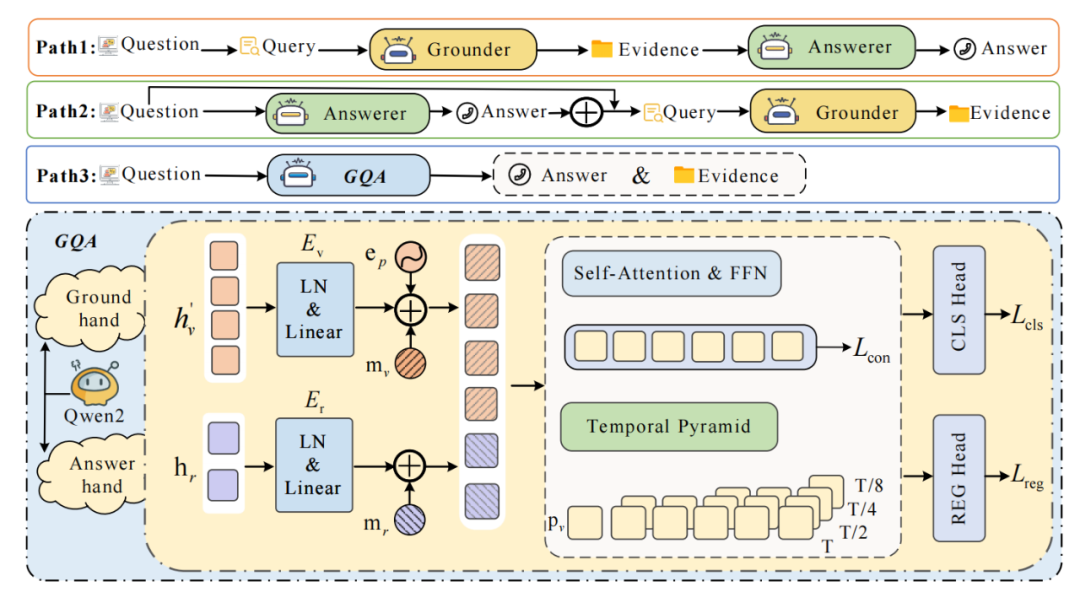
路径1
采用"先定位后回答"的策略,首先由定位器提取候选片段,再由回答器生成答案,这种方法适用于问题明确涉及特定时刻的场景。
路径2
采用逆向思维,先由回答器预测答案,再由定位器反向检索支持该答案的片段,有效减少错误定位对最终答案的影响。
路径3
通过联合问答器实现同步预测,在保证计算效率的同时可能受到噪声干扰。这种多路径设计使得模型能够从不同角度进行推理,显著提高了系统的鲁棒性。
值得一提的是,MUPA框架还包含有反思机制,以确保答案与视觉证据的高度一致性。该机制主要包括两个关键阶段:
单路径验证阶段
系统对每条路径的候选答案-证据对进行一致性评分,采用专家乘积(PoE)策略融合定位置信度和验证评分,有效抑制低质量候选。
多路径融合阶段
通过加权K-means聚类合并不同路径的候选片段,并利用最小二乘法优化边界,最终输出最可靠的证据片段。
▍基于两大基准数据集,系统实验评估
为了验证所提MUPA框架在时序视频问答任务上的优越性,研究团队在NExT-GQA和DeVE-QA两大基准数据集上进行了深入实验,并围绕“MUPA是否优于现有方法?”“多路径设计是否有效?”“反思机制是否提升性能?”三大问题进行系统化测试评估。
在核心性能测试中,MUPA框架展现出强大的竞争力。使用20亿参数的轻量版模型在NExT-GQA数据集上取得了28.7%的Acc@GQA指标,这一成绩已经超越了所有参数量达70亿的对比模型。当扩展至70亿参数时,模型性能进一步提升至30.3%,创造了该基准的新纪录。
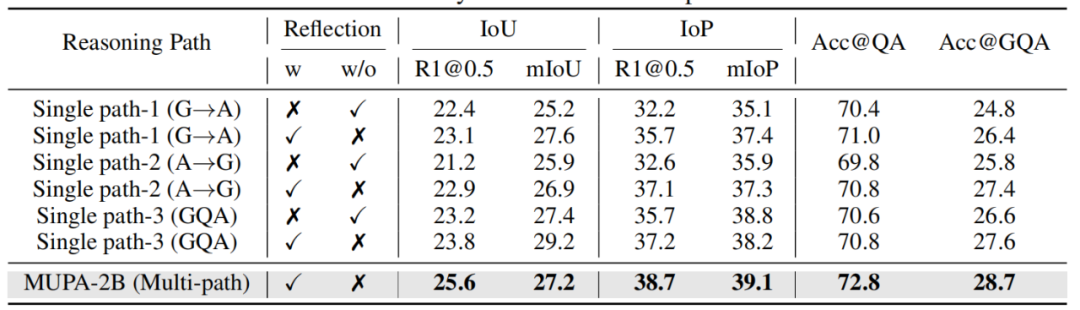
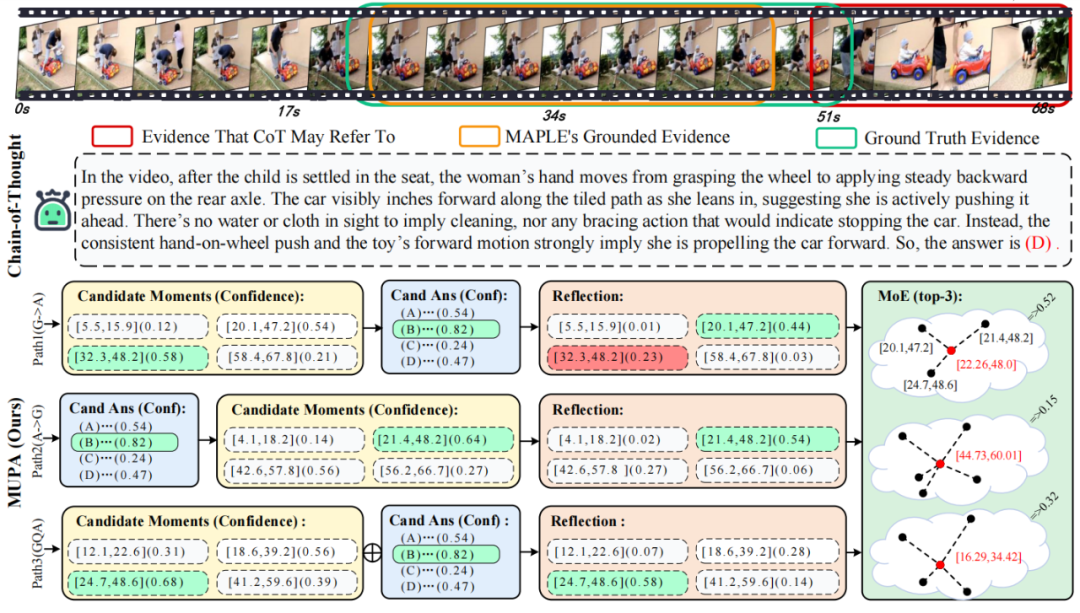
值得注意的是,在衡量答案与视觉证据一致性的IoP@0.5指标上,MUPA框架相较之前最优模型实现了4.1个百分点的提升,这充分证明了多路径协同设计的有效性。实验中,研究团队也特别关注了不同推理路径的贡献度。实验结果表明,传统的“先定位后回答”路径在明确的时间查询上表现最佳,而创新的“先回答后验证”路径则更擅长处理需要高层语义推理的问题。当三条路径协同工作时,系统展现出明显的互补优势,在复杂问题上能够比单一路径模型提升2.3%的准确率。这种协同效应在长视频理解任务中尤为突出,对于持续时间超过30秒的事件关联问题,多路径设计的优势可达到3.5个百分点。
对于反思机制的性能提升问题,研究团队亦通过专业的验证器进行了评估。结果表明,MUPA框架能够有效识别并过滤掉68%的不可靠候选答案。在典型案例分析中,当不同路径给出矛盾结果时,反思机制成功校正结果的准确率达到82%。更值得关注的是,在对抗性测试集上,配备完整反思机制的模型保持住了85%的原始性能,而基线模型的准确率则骤降了23%。
此外,研究团队也探索了模型的实际应用潜力。在医疗内镜视频分析场景中,经过领域适配的MUPA框架实现了72.3%的病灶定位准确率,其生成的诊断描述被专业医师评为“临床可用”的比例达到76.5%。这些结果充分证明了MUPA框架在专业领域的实用价值。

推荐阅读





×
右键可直接复制图片