
 阅读时间大约10分钟以上(4325字)
阅读时间大约10分钟以上(4325字)
2025-08-22 波士顿动力LBM大行为模型进展:端到端、长程、复杂、提速以及全身运控和灵巧操作
来源:波士顿动力
这项成果展示了一种更高效的教会机器人完成任务方法。
作者:liuxjerry 出品:具身纪元
波士顿动力与丰田研究院合作,用大行为模型(LBMs)的人工智能方法,让 Atlas 人型机器人通过端到端的策略模型,完成移动和操作结合为一体的长序列复杂任务。
几个亮点:
这是老牌机器人公司波士顿动力推出的一个全新的端到端的、由语言指令驱动的AI策略模型。
移动(locomotion)和操作(manipulation)结合在一起进行数据采集和训练。他们为机器人的双脚增加了两个额外的追踪器,使得 Atlas在移动上可以与操作员的动作完全适配。
出现问题时(例如零件掉到地上),策略模型能够智能地做出反应。这是因为策略模型可以仅凭训练中观察到的经验,有效地从机器人的传感器估计世界状态并做出相应反应。编写新的操控行为不再需要高级学位和多年的经验,这为扩大 Atlas 的行为开发创造了一个极具吸引力的机会。
操作任务难度较大:从简单的取放任务到更复杂的任务,如打绳结、翻转吧台凳、展开并铺开桌布,以及操控一个较重的汽车轮胎,包含长程任务
这个策略模型可以在推理时加快执行速度,而无需在训练时做任何改变。能够将策略模型的速度提高 1.5到2倍,而不会显著影响其性能,超过遥操作的速度
仿真数据是波士顿动力训练数据的补充,也帮助他们快速迭代和评估
这项成果展示了一种更高效的教会机器人完成任务方法:不需要复杂的编程,通过“手把手”演示就能让机器人自主学习。他们宣称:“只要你能演示出来,机器人就能学会。” 这给机器人投入实际应用增加了新的机会。
以下为全文翻译:
https://bostondynamics.com/blog/large-behavior-models-atlas-find-new-footing/
实用的人型机器人需要具备一系列广泛的能力。它们需要能够操控各种各样的物体(例如:硬/软、重/轻、刚性/铰接、大/小),并协调整个身体来重新配置自身和环境、避开障碍物,并在应对意外情况时保持平衡。我们相信,构建通用型人工智能机器人是培养这些能力、实现大规模自动化的最可行途径。
我们很高兴能与大家分享我们为 Atlas开发大行为模型 (Large Behavior Models, LBMs)的一些进展。这项工作是丰田研究院 (TRI) 和波士顿动力的人工智能研究团队之间合作的一部分。我们一直在构建端到端的、由语言指令驱动的策略模型,使 Atlas 能够完成长序列的操控任务。
这些策略模型能够充分利用仿人形态的各种能力,包括行走、精确定位脚部、蹲下、转移重心以及避免自身碰撞——我们发现所有这些对于解决现实的移动操控任务都至关重要。
构建策略模型的过程

构建策略模型的过程包括四个基本步骤:
·收集具身行为数据:通过在真实机器人硬件和仿真环境中进行遥操作来收集数据。
·处理、标注和整理数据:以便我们能轻松地将其整合到机器学习流程中。
·训练神经网络策略模型:使用涵盖所有任务的全部数据进行训练。
·评估策略模型:使用一套测试任务进行评估。
第四步的结果会指导我们决策,判断需要额外收集哪些数据,以及哪种网络架构或推理策略能带来更好的性能。
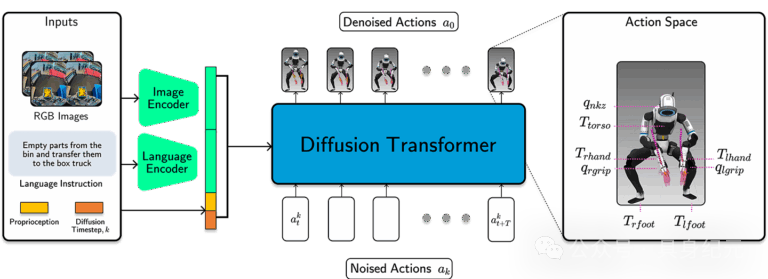
图注:波士顿动力模型架构
我们的策略模型将图像、本体感觉和语言提示等输入映射为动作指令,以 30Hz 的频率控制整个 Atlas 机器人。我们利用Diffusion Transformer和流匹配损失 (flow matching loss) 来训练我们的模型。
在实施这一过程中,我们遵循了三个核心原则:
最大化任务覆盖范围:原则上,人型机器人可以处理极其广泛的操控任务,但在保证高质量、响应迅速的运动的同时,收集超越固定位置操控任务的数据是具有挑战性的。我们构建了一个顶尖的遥操作系统,将 Atlas 的模型预测控制器 (MPC) 与定制的 VR 界面相结合,以覆盖从指尖级别的精细操作到全身范围的伸展和移动等各种任务。
训练通用策略模型:该领域不断积累的证据表明,基于大量多样化任务数据训练的通用策略模型,比那些为解决单个或少数任务而训练的专用策略模型具有更好的泛化和恢复能力。我们使用多任务、语言指令驱动的策略模型,在多种机器人形态上完成各种任务,其中整合了来自 Atlas、仅有上半身的 Atlas 操控测试台 (MTS) 以及TRI Ramen机器人的预训练数据。构建通用策略模型还能让我们简化部署,在不同任务和机器人形态之间共享策略模型的改进,并向解锁涌现行为更近一步。
构建支持快速迭代和严谨科学的基础设施:能够快速迭代设计选择至关重要,但真正关键的是能够有信心地衡量一个策略模型何时优于或劣于另一个,这是取得稳步进展的核心要素。通过结合仿真、硬件测试和为生产规模构建的机器学习基础设施,我们能够高效地探索数据和策略模型的设计空间,同时不断提升机器人在真实环境中的表现。
长序列、端到端的操控
“Spot 车间”任务展示了协调的移动能力——行走、跨大步站立和下蹲——以及灵巧的操控能力,包括零件拾取、重新抓取、关节操作、放置和滑动。它由三个子任务组成:
从推车上抓取 Spot机器狗的腿,将其折叠,然后放到架子上。
从推车上抓取面板,然后拉开底层架子上的箱子,并将面板放入箱中。
当推车完全清空后,转向后面的蓝色箱子,清除其中所有其他 Spot 零件,并将它们分批放入蓝色的倾卸车中。
在这个未经剪辑的端到端视频中,我们展示了一个单一的、由语言指令驱动的策略模型执行了完整的任务序列,其中三个子任务中的每一个都是通过向策略模型传递一个高级语言提示来触发的。
一个关键特性是,当出现问题时(例如零件掉到地上或箱盖关闭),我们的策略模型能够智能地做出反应。我们策略模型的初始版本不具备这些能力。通过向机器人演示如何从这类干扰中恢复,并重新训练我们的网络,我们能够快速部署新的反应式策略模型,而无需进行任何算法或工程上的更改。这是因为策略模型可以仅凭训练中观察到的经验,有效地从机器人的传感器估计世界状态并做出相应反应。因此,编写新的操控行为不再需要高级学位和多年的经验,这为扩大 Atlas 的行为开发创造了一个极具吸引力的机会。
额外的操控能力
我们研究了数十个任务,既用于基准测试,也用于推动操控能力的极限。在 Atlas MTS 上使用单一的、由语言指令驱动的策略模型,我们可以执行从简单的取放任务到更复杂的任务,如打绳结、翻转吧台凳、展开并铺开桌布,以及操控一个 22 磅(约 10 公斤)重的汽车轮胎。绳索、布料和轮胎的操控是传统机器人编程技术极难完成的任务,因为它们具有可变形的几何形状和复杂的操控序列。但有了 LBMs,训练过程都是一样的,无论是堆叠刚性积木还是折叠 T 恤:只要你能演示出来,机器人就能学会。
学习后调整策略模型的性能
我们策略模型的一个显著特点是,我们可以在推理时加快执行速度,而无需在训练时做任何改变。具体来说,由于我们的策略模型会预测一系列未来的动作以及这些动作应该被执行的时间,我们可以通过调整这个时间来控制执行速度。在下面的视频中,我们比较了策略模型以 1 倍速(即数据收集中完成此任务的速度)以及 2 倍和 3 倍速运行的情况。总的来说,我们发现在MTS和完整的Atlas平台上,我们能够将策略模型的速度提高 1.5 到 2 倍,而不会显著影响其性能。虽然任务的动态特性有时会妨碍这种推理时加速,但这确实表明,在某些情况下,我们可以超越人类遥操作的速度极限。
方法
平台
Atlas 拥有 50 个自由度 (DoF),提供了广泛的运动范围和高度的灵活性;Atlas MTS 拥有 29 个自由度,用于探索纯粹的操控任务。每个夹爪有 7 个自由度,使我们能够使用多种抓取策略(如强力抓握、捏取等)。我们依靠安装在头部的一对 HDR 立体摄像头,为遥操作提供态势感知,并为我们的策略模型提供视觉输入。
遥操作:为模型训练收集高质量数据
以流畅、动态和灵巧的方式控制机器人至关重要,我们在这方面投入了大量资源来打造我们的遥操作系统。该系统建立在波士顿动力的 MPC 系统之上,该系统此前已被部署于从跑酷、舞蹈到实用和不实用的操控等各种用例。这个控制系统使我们能够在保持平衡和避免自身碰撞的同时执行精确的操控,从而让我们能够突破 Atlas 硬件的极限。
遥操作设置利用 VR 头戴设备,让操作员完全沉浸在机器人的工作空间中,并能获取与策略模型相同的信息。通过将 Atlas 头部摄像头的画面重新投影到用户的视点,渲染出立体视觉,从而增强了空间感知能力。定制的 VR 软件为遥操作员提供了丰富的机器人指令界面,通过增强现实、控制器触觉反馈和平视显示元素,为他们提供机器人状态、控制目标、传感器读数、触觉反馈和系统状态的实时信息。这使得遥操作员能够充分利用机器人的硬件和能力,将自己的身体和感官与机器人同步。
VR 遥操作应用的初始版本使用头戴设备、基站、控制器和一个用于胸部的追踪器来控制静止站立的 Atlas。该系统采用用户与机器人之间的一对一映射(即用户的手移动 1 厘米,机器人也移动 1 厘米),这带来了直观的控制体验,尤其对于双手任务而言。通过这个版本,操作员已经能够执行各种任务,例如低蹲去拿地上的物体,以及站直去够高处的架子。然而,该系统的一个局限是它不允许操作员动态地重新定位脚部和迈步,这极大地限制了我们能执行的任务。
为了支持移动操控,我们为双脚增加了两个额外的追踪器以实现一对一追踪,并扩展了遥操作控制,使得 Atlas 的站姿模式、支撑多边形和行走意图与操作员的相匹配。除了支持移动,这个设置还使我们能够充分利用 Atlas 的工作空间。例如,在打开地上的蓝色手提箱并从中取物时,操作员必须能够让机器人配置成宽站姿和弯曲膝盖的姿态,以便在不与箱子碰撞的情况下够到箱内的物体。
我们的神经网络策略模型使用与遥操作系统相同的机器人控制接口,这使得重用我们之前开发的模型架构(用于不涉及移动的策略模型)变得很容易,只需增加动作表示即可。
策略模型
我们的策略模型基于丰田研究院的大行为模型(该模型扩展了类似 Diffusion Policy 的架构),采用了一个4.5 亿参数、基于 Diffusion Transformer 的架构,并结合了流匹配目标函数。该策略模型以本体感觉、图像为条件,并接受一个语言提示来向机器人指定目标。图像数据以 30Hz 的频率输入,我们的网络使用历史观测数据来预测一个长度为 48 的动作块(对应 1.6 秒),通常每次策略模型推理运行时会执行 24 个动作(在 1 倍速运行时为 0.8 秒)。
Atlas 策略模型的观测空间包括来自机器人头部摄像头的图像以及本体感觉。动作空间包括左右夹爪的关节位置、颈部偏航、躯干姿态、左右手姿态以及左右脚姿态。
Atlas MTS 的上半身在机械和软件方面都与 Atlas 完全相同。其观测和动作空间与 Atlas 相同,只是省略了躯干和下半身的组件。Atlas 和 Atlas MTS 之间共享的硬件和软件有助于训练能够在两个平台上运行的多形态策略模型,使我们能够汇集来自两种形态的数据。
这些策略模型是在团队持续收集和迭代的数据上训练的,其中高质量的演示是获得成功策略模型的关键部分。我们严重依赖我们的质量保证工具,这些工具使我们能够审查、筛选并对收集到的数据提供反馈。
仿真
仿真是一个关键工具,它使我们能够快速迭代遥操作系统,编写单元和集成测试以确保我们能够无故障地前进,并进行有信息量的训练和评估,而这些在硬件上进行会更慢、更昂贵且难以重复。由于我们的仿真堆栈是硬件和机器人上软件堆栈的忠实再现,我们能够在仿真和硬件平台上共享我们的数据管道、可视化工具、训练代码、VR 软件和接口。
除了使用仿真来对我们的策略模型和架构选择进行基准测试外,我们还将仿真作为我们部署在硬件上的多任务和多形态策略模型的重要联合训练数据源。
结论与未来展望
我们已经证明,我们可以训练出多任务、由语言指令驱动的策略模型,这些模型能够控制 Atlas 完成涉及移动和灵巧全身操控的长序列任务。我们的数据驱动方法是通用的,几乎可以用于任何可以通过遥操作演示的下游任务。
虽然我们对目前的结果感到鼓舞,但仍有许多工作要做。在我们已建立的任务和性能基线上,我们将专注于扩展我们的数据飞轮,以提高吞吐量、质量、任务多样性和难度,同时探索新的算法思想。
我们正在追求几个研究方向,包括与性能相关的机器人学课题(例如,带触觉反馈的夹爪力控制、快速动态操控)、整合多样化的数据源(跨形态、第一人称人类数据等)、用强化学习(RL)改进视觉-语言-行动(VLA)模型,以及部署视觉-语言模型(VLM)/视觉-语言-行动模型(VLA)架构以实现更复杂的长序列任务和开放式推理。

推荐阅读





×
右键可直接复制图片