
 阅读时间大约7分钟(2628字)
阅读时间大约7分钟(2628字)
2025-10-09 用手机拍段视频,就能让机器人学会新技能?伯克利团队提出R2R2R,数据生成效率比人类快27倍!
来源:豆包
用1条人类演示数据生成的训练集,就能让机器人达到150条人类远程操控数据的训练效果。
作者:李鑫 出品:具身智能大讲堂
在机器人学习领域,有个绕不开的数据困境。想让机器人掌握抓取、摆放这类精细操作,需要海量标注数据,但靠人类远程操控机器人采集数据,不仅成本高、速度慢,1 个操作员 1 分钟顶多生成 1.7 条有效数据,跟训练大语言模型动辄千万级的数据集完全不在一个量级。

现在,加州伯克利和丰田研究院的团队提出了一种颠覆性方案——Real2Render2Real(简称 R2R2R)。只需用手机拍两样东西:一是目标物体的多角度扫描视频,二是人类完成任务的演示视频,就能自动生成成千上万条高质量机器人训练数据。
更关键的是,它既不用复杂的物理仿真,也不需要实际操控机器人,单块 GPU 的数据生成速度就是人类的 27 倍,用1条人类演示数据生成的训练集,就能让机器人达到150条人类远程操控数据的训练效果。
1►为什么传统机器人数据采集 “又慢又贵”?
在 R2R2R 之前,机器人学习的数据来源主要有两条路,但都有明显短板:
一条是人类远程操控。操作员通过手柄控制机器人完成任务,记录动作和视觉数据。这种数据最贴近真实场景,但效率极低,1 个操作员采集 150 条 “把杯子放到咖啡机上” 的演示数据,要花 86 分钟;而且数据受限于操作员的水平,场景一变就需要重新采集。
另一条是物理仿真。在虚拟环境里用算法生成机器人动作,比如用强化学习让虚拟机器人 “试错” 学习抓取。这种方式能批量生成数据,但最大问题是 “仿真到现实的鸿沟”:虚拟环境里的物体摩擦力、光照条件和真实世界差太远,仿真里训练好的技能,放到真实机器人上往往会失灵。而且搭建高保真仿真环境成本不低,还需要手动调整大量物理参数,比如物体的弹性、表面纹理,对小团队极不友好。
简单说,传统方案要么 “慢且贵”,要么 “假且不准”。而 R2R2R 的核心思路是:从真实世界的少量数据出发,用 3D 重建和渲染技术,生成既贴近真实、又能批量扩展的训练数据。
2►R2R2R 怎么工作?三步实现 “手机拍→数据生→机器人学”
R2R2R 的流程特别直观,本质是 “把真实世界的信息转化为虚拟训练数据,再用虚拟数据教真实机器人”,整个过程分三步:

第一步:用手机 “复刻” 真实世界 ——3D 重建物体和动作
首先需要两部手机拍摄的输入:

3D 高斯 Splat 物体重建,基于特征分组进行部件级分割
一是物体的多角度扫描视频,比如围绕杯子、咖啡机拍一圈,用 3D 高斯溅射(3D Gaussian Splatting)技术重建出物体的 3D 模型。这种技术比传统的 3D 建模快得多,还能保留物体的细节纹理,比如杯子上的图案、咖啡机的按钮;

轨迹插值 –R2R2R 通过空间归一化和 Slerp 函数,使物体运动适应不同的起始/结束配置。
二是人类演示视频,比如用手机拍一个人 “拿起杯子放到咖啡机上” 的过程,用 4D 差分部件建模(4D-DPM)技术,跟踪物体的 6 自由度运动 —— 简单说,就是算出 “杯子从哪里开始动、怎么移动、最终放到哪里”,甚至能区分关节物体,比如抽屉的推拉、水龙头的旋转。
这一步的核心是 “数字化复刻”:把真实物体和人类动作,转化为计算机能理解的 3D 模型和运动轨迹,为后续批量生成数据打下基础。
第二步:让数据 “变多”—— 批量生成多样化训练样本
有了基础的 3D 模型和运动轨迹,接下来要解决 “数据多样性” 问题 —— 如果只重复人类演示的动作,机器人学不会应对不同场景(比如杯子位置变了、光照变了)。R2R2R 用两种方式扩展数据:
一是轨迹插值:比如人类演示的是 “杯子从 A 点放到 B 点”,算法会自动生成 “杯子从 C 点放到 B 点”“杯子从 A 点放到 D 点” 的轨迹,还能保证动作逻辑不变(比如先伸手、再抓取、最后放下)。论文里提到,他们用 “球面线性插值” 调整物体的旋转角度,用 affine 变换调整平移路径,确保新轨迹既多样又合理。
二是环境随机化:在渲染虚拟训练数据时,随机调整光照(比如从冷光变暖光)、相机角度(比如稍微偏移 2 厘米、旋转 5 度)、物体初始位置(比如杯子每次放在桌子的不同地方)。这些变化能让机器人学会适应真实世界的变量,不会因为光照变了就认不出杯子。
第三步:“喂” 给机器人学 —— 生成兼容主流模型的训练数据
最后一步是把生成的 3D 模型和轨迹,转化为机器人能理解的训练数据。R2R2R 用 IsaacLab 这个渲染引擎,批量生成 “视觉 + 动作” 配对的数据:
•视觉数据:渲染出机器人视角的 RGB 图像,就像真实机器人的摄像头看到的画面;
•动作数据:根据机器人的关节结构(比如双臂机器人的每个关节角度),用逆运动学算法算出 “要完成这个轨迹,每个关节该怎么动”。
这些数据可以直接用于主流的机器人学习模型,比如扩散策略(Diffusion Policy)、视觉 - 语言 - 动作模型(VLA)。研究团队测试了两种模型:一种是从零开始训练的扩散策略,一种是基于预训练模型微调的 π₀-FAST,都能直接用 R2R2R 生成的数据训练。
3►效果有多好?1 条人类演示≈150 条远程操控数据
研究人员用 5 个典型任务测试了 R2R2R 的效果,包括 “拿起玩具老虎”“打开抽屉”“双手拿起包裹”“关掉水龙头”“把杯子放到咖啡机上”,用 ABB YuMi 双臂机器人做物理实验,结果很有说服力:
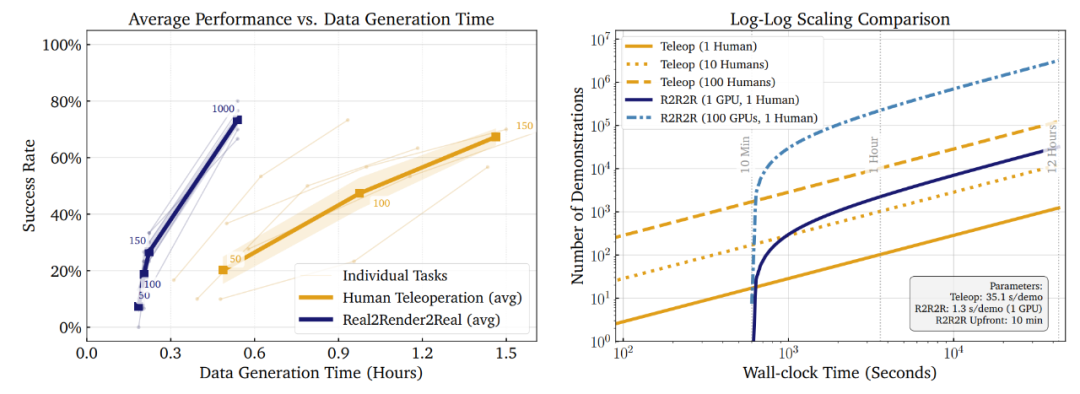
跨操作任务的数据生成效率和平均策略性能
速度:单 GPU 比人类快 27 倍
人类操作员 1 分钟能生成 1.7 条数据,而单块 NVIDIA RTX 4090 GPU1 分钟能生成 51 条,速度提升 27 倍;如果用 100 块 GPU,数据生成速度会线性增加,几小时就能生成上万条数据。比如 “双手拿起包裹” 这个任务,人类采集 150 条数据要 90 分钟,而 R2R2R 生成 1000 条数据只需要 14 分钟。
效果:少量数据就能达到高准确率
在 “把杯子放到咖啡机上” 任务中,用 R2R2R 生成 1000 条数据训练 π₀-FAST 模型,成功率达到 80%,和用 150 条人类远程操控数据训练的效果(73.3%)基本持平;在 “打开抽屉” 任务中,R2R2R 数据训练的模型成功率 86.6%,甚至超过了人类数据的 60%。
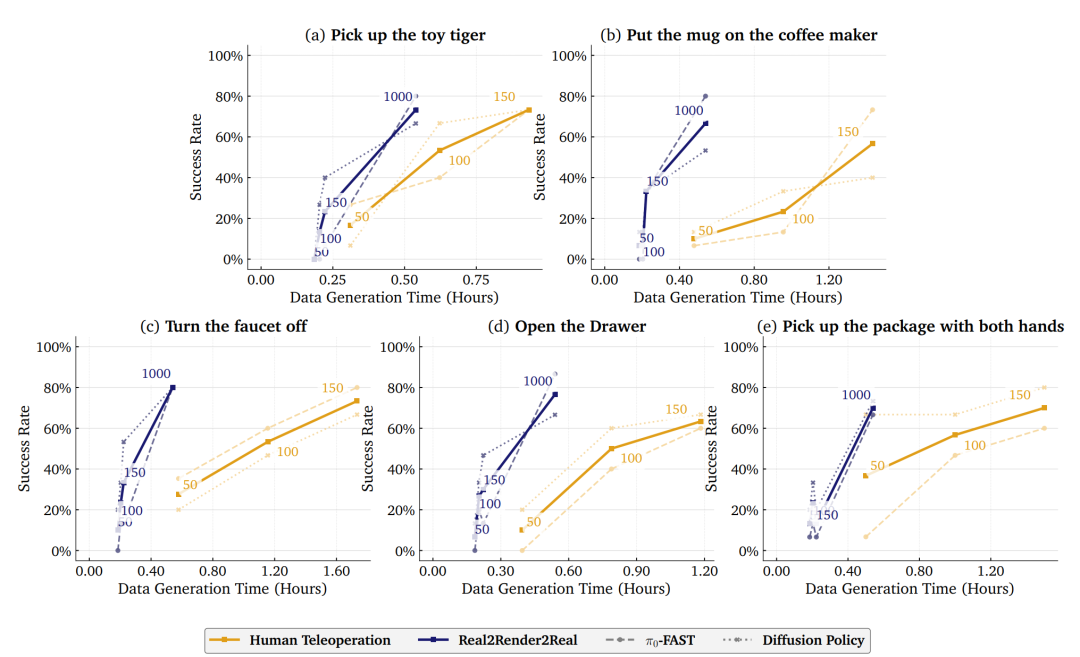
比较 Real2Render2Real 与人类远程操作数据效率的物理实验任务成功率与数据生成时间(以小时为单位)的关系图
更关键的是泛化能力:R2R2R 生成的数据能适应不同场景。比如训练时杯子放在桌子左侧,测试时把杯子移到右侧,机器人依然能完成任务;而传统仿真数据如果没见过这种场景,成功率会暴跌。
4►还有哪些不足?未来能怎么改进?
R2R2R 虽然突破明显,但还有几个待解决的问题:
一是不支持柔性物体。目前只能处理刚性物体(比如杯子、老虎玩具)和关节物体(比如抽屉、水龙头),像布料、绳子这类柔性物体还无法建模,因为它们的变形难以用 3D 高斯溅射重建。
二是没有碰撞检测。生成轨迹时不会考虑障碍物,比如如果桌子上有个盘子,算法可能生成 “杯子穿过盘子” 的不合理轨迹,需要后续加入快速运动规划来规避碰撞。
三是抓握方式有限。目前只支持平行夹爪的抓握,像多手指机械手的复杂抓握(比如用三根手指捏起勺子)还不支持,因为这类抓握需要更精细的接触点计算。
5►为什么说 R2R2R 是 “机器人学习的平民化方案”?
加州伯克利和丰田研究院提出的R2R2R,不只是提出一个数据生成方法,更在于降低了机器人学习的门槛:
以前要训练一个机器人,要么需要专业操作员和多台机器人硬件,要么需要懂物理仿真的工程师;现在只要有个手机,拍段视频,就能生成训练数据。对小团队、高校实验室来说,这意味着不用花大价钱买设备,也能开展机器人学习研究。
而且它的扩展性很强,研究中提到,未来可以结合更先进的 3D 重建技术,比如用单张图片重建 3D 模型,进一步减少拍摄成本;还能加入物理仿真模块,比如在生成数据时加入简单的碰撞检测,让数据更贴近真实场景。
简单说,R2R2R 给机器人学习提供了一条 “低成本、高效率” 的新路径:不用等海量人类数据,不用搭复杂仿真环境,用手机拍点视频,就能让机器人快速学会新技能。这或许是未来机器人 “普及化学习” 的关键一步。
论文地址:https://arxiv.org/pdf/2505.09601
项目地址:https://real2render2real.com/

推荐阅读





×
右键可直接复制图片