
 阅读时间大约10分钟以上(4136字)
阅读时间大约10分钟以上(4136字)
2026-05-18 打通Sim2Real必看的20个具身仿真评测基准
来源:具身智能之心
伴随VLA与世界模型的爆发,评测基准正从“感知与执行精度”向“高阶认知深度”跃迁。
出品:具身智能之心
具身智能的底色是物理世界的闭环控制,面对非结构化场景的海量Corner Case,Policy究竟是真正理解了任务逻辑,还是仅仅在状态空间(State Space)里做了过度拟合?
仿真评测基准(Benchmark)的意义,绝不仅是提供几个场景模型,而是为了解决具身智能最致命的三个命题:数据Scaling底座验证、泛化边界测试,以及Long-Horizon(长时程)任务的逻辑一致性评估。
伴随VLA与世界模型的爆发,评测基准正从“感知与执行精度”向“高阶认知深度”跃迁。
具身智能之心汇总了目前全球最具代表性的20个具身智能仿真评测基准,从底层物理反馈、双臂操作任务、导航、再到终身学习框架,带你直接摸透当前的真实技术水位。
内容首发于具身智能之心知识星球。更多干货,欢迎加入国内首个具身智能全栈学习社区。
·20个非真机&仿真·
评测基准汇总
以上内容由『具身智能之心』团队根据公开信息整理。
01.
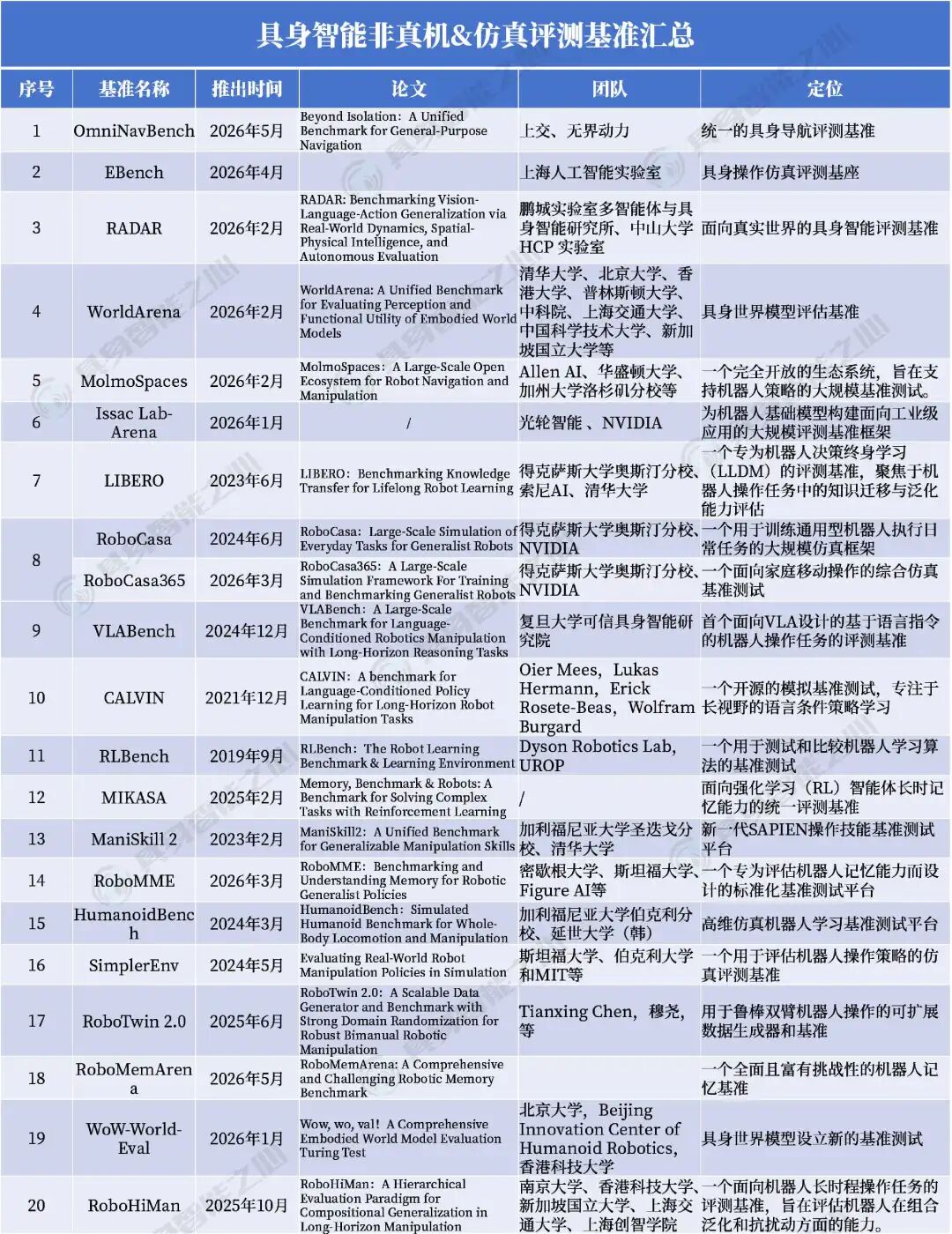
OmniNavBench
http://omninavbench.cloud-ip.cc
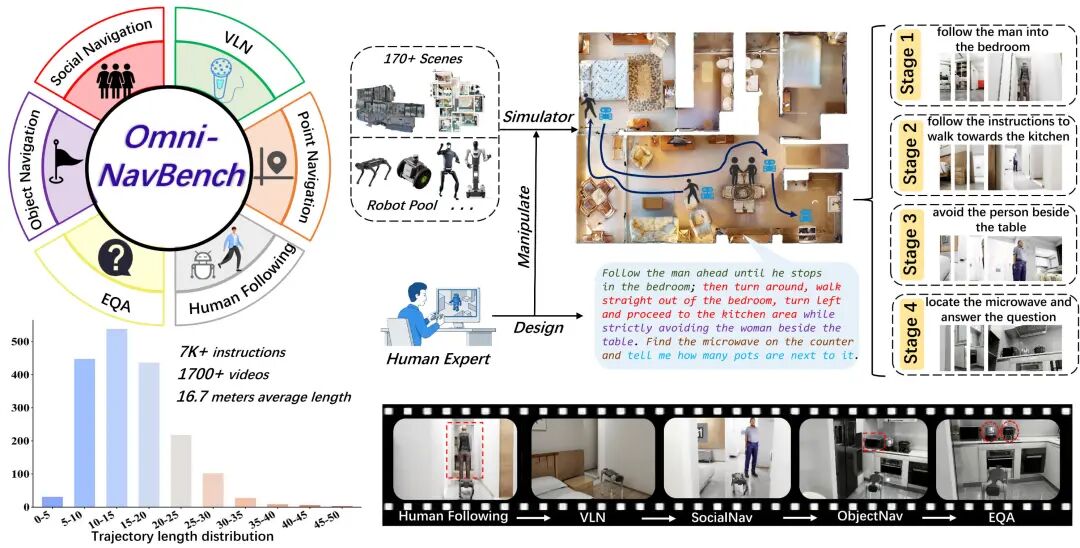
推出时间:2026年5月
论文:《Beyond Isolation:A Unified Benchmark for General-Purpose Navigation》
推出团队:上交、无界动力
简介:
OmniNavBench 是目前唯一同时覆盖六种任务、支持跨构型评测、并基于人类专家轨迹构建的统一导航基准。其核心理念可以用三个关键词概括:跨技能协同、跨构型泛化、人类级行为监督。
02.
EBench
https://internrobotics.shlab.org.cn/eval
推出时间:2026年4月29日
推出团队:上海人工智能实验室
定位:具身操作仿真评测基座
简介:
EBench 共包含 26 种任务,并为每个任务标注了场景、原子技能、时长、精度、移动能力五个维度标签;同时在验证集和测试集中覆盖物体、背景、指令、组合四类泛化维度,共构建 794 条测试任务,用于支撑更细粒度的能力诊断与泛化评估。
03.
RADAR
推出时间:2026年2月
定位:面向真实世界的具身智能评测基准
全称:Real-world Autonomous Dynamics And Reasoning
论文:《RADAR: Benchmarking Vision-Language-Action Generalization via Real-World Dynamics, Spatial-Physical Intelligence, and Autonomous Evaluation》
推出机构:鹏城实验室多智能体与具身智能研究所、中山大学 HCP 实验室
简介:
RADAR是专为具身智能领域设计的全新一代评测基准,系统性地解决了现有评测体系的三大核心缺陷(忽视真实世界动态性、缺乏空间-物理智能测试、评估方法不可扩展),为 VLA 模型提供真实可靠的泛化能力评估。
04.
WorldArena
https://worldarena.github.io/

2026-05-15榜单截图
推出时间:2026年2月
定位:WorldArena是旨在从感知与功能两大维度全面、系统地评估具身世界模型的统一基准。
论文:《WorldArena: A Unified Benchmark for Evaluating Perception and Functional Utility of Embodied World Models》
推出机构:清华大学、北京大学、香港大学、普林斯顿大学、中科院、上海交通大学、中国科学技术大学、新加坡国立大学等顶尖机构联合推出。
简介:
WorldArena从以下维度评估模型:
视频感知质量:通过六个子维度上的十六个指标进行衡量;
具身任务功能:评估世界模型作为合成数据引擎、策略评估器和行动规划器的能力。
此外,该团队还提出了一种名为 EWMScore 的综合性指标,旨在将多维度的性能表现整合为一个单一且易于解读的指数。
05.
MolmoSpaces
https://molmospaces.allen.ai/
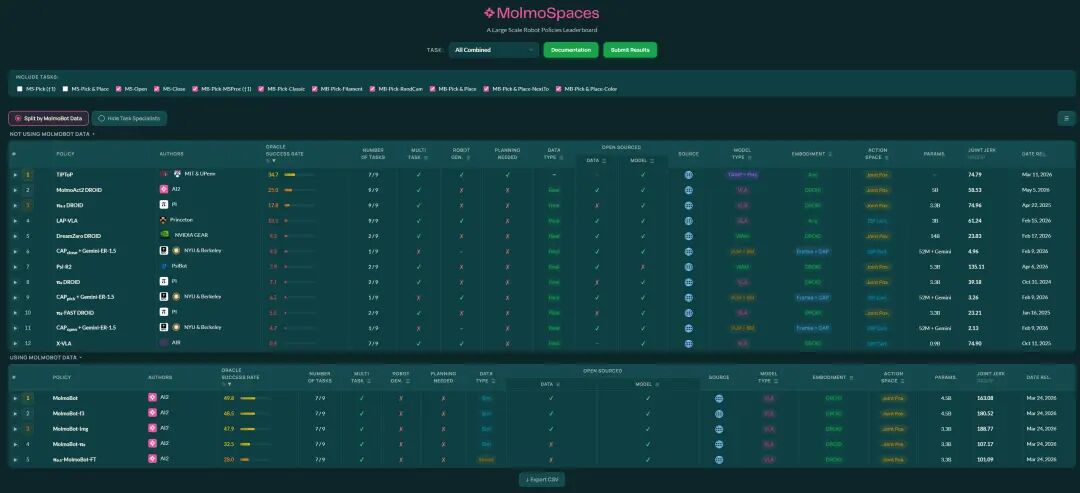
2026-05-15榜单截图
推出时间:2026年2月
论文:《MolmoSpaces:A Large-Scale Open Ecosystem for Robot Navigation and Manipulation》
推出机构:Allen AI、华盛顿大学、加州大学洛杉矶分校等联合出品。
简介:
大规模部署机器人需要对日常情况的长尾效应具备鲁棒性。实际环境中无数的变化,包括场景布局、物体几何形状和任务规范等特征是广泛存在但现有机器人基准测试中却鲜有体现的。要衡量这种程度的泛化能力,仅依靠物理评估无法提供所需规模和多样性的基础设施。MolmoSpaces是一个完全开放的生态系统,旨在支持机器人策略的大规模基准测试。
06.
Issac Lab-Arena
https://isaac-sim.github.io/IsaacLab-Arena/main/index.html
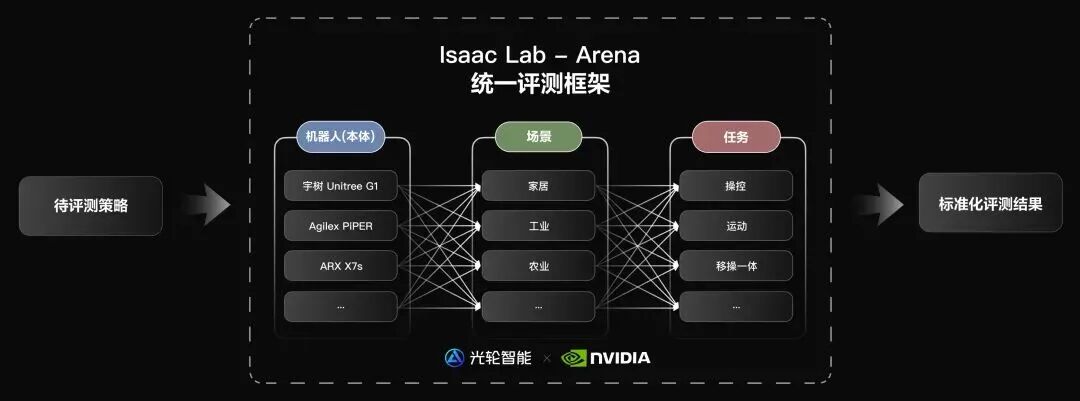
推出时间:2026年1月
定位:大规模开源机器人策略评测基准框架
推出机构:光轮智能 、NVIDIA 联合开源。
简介:
Issac Lab-Arena是一个为机器人基础模型构建面向工业级应用的大规模评测基准框架,推动具身智能从“训练驱动”迈向“评测驱动”的新阶段。
Isaac Lab-Arena采用标准化的三层评测结构,实现对机器人策略能力的系统性覆盖:
机器人本体层:支持宇树G1、Agilex PIPER、ARX X7s等主流平台,实现跨本体的统一评测。
场景层:覆盖家居、工业、农业等多样化应用环境。
任务层:涵盖操控、运动、移动操作一体化等核心能力维度。
07.
LIBERO
https://libero-project.github.io/datasets
全称:Lifelong Learning Benchmark for Robot Manipulation
推出时间:2023年6月
论文:《LIBERO:Benchmarking Knowledge Transfer for Lifelong Robot Learning》
推出机构:得克萨斯大学奥斯汀分校、索尼AI、清华大学
简介:
LIBERO是一个专为机器人纵任务设计的终身学习基准环境,旨在推动决策终身学习(Lifelong Learning in Decision Making, LLDM)的研究。
基准包括四个任务套件(总计 130 个任务):LIBERO-Spatial(空间布局变化,10 任务)、LIBERO-Object(物体类型变化,10 任务)、LIBERO-Goal(目标变化,10 任务)和 LIBERO-100(混合 100 任务)。这些任务基于人类日常活动(如“打开柜子的抽屉”),使用自然语言指令条件化,支持部分可观测 MDP(Markov Decision Process)。
08.
RoboCasa
https://robocasa.ai/
2026-05-15榜单截图
推出时间:2024年6月
论文:《RoboCasa:Large-Scale Simulation of Everyday Tasks for Generalist Robots》
推出团队:得克萨斯大学奥斯汀分校、NVIDIA
简介:
RoboCasa 是一个用于训练通用型机器人执行日常任务的大规模仿真框架。其特点在于拥有以人为中心的真实且多样化的环境,尤其专注于厨房场景。借助生成式人工智能工具(如大语言模型和文本到图像/3D生成模型)创建了这些环境。并提供了覆盖150多个物体类别的2500多个3D资源,以及数十种可交互的家具和电器。作为首次发布的一部分,包含了一套涵盖广泛日常活动的100个任务。与仿真任务一同提供的,还有一个高质量人类示范数据集,并利用自动轨迹生成技术,以极低的额外成本显著扩展了训练数据的规模。
2026年3月,该团队基于 RoboCasa 平台构建了RoboCasa365。RoboCasa365旨在支持针对不同问题设置的系统性评估,包括多任务学习、机器人基础模型训练以及终身学习。
09.
VLABench
https://vlabench.github.io/
推出时间:2024年12月
定位:首个面向VLA设计的基于语言指令的机器人操作任务的评测基准。
论文:《VLABench:A Large-Scale Benchmark for Language-Conditioned Robotics Manipulation with Long-Horizon Reasoning Tasks》
团队:复旦大学可信具身智能研究院
简介:
VLABench的评测同时支持VLA,Agent等控制机器人的Policy方法,以及VLM的多模态理解与任务规划能力。使用VLABench, 你可以方便快速的:
在多种任务组合和难度等级上评测最新的VLA模型的性能与泛化能力。
从视觉、语言、规划、常识等多维度评测VLM在具身场景下的多模态推理能力。
充分评测基于LLM/VLM的Agent方法在机器人操作任务的零样本学习能力。
利用VLABench生成海量高质量仿真数据用于下游任务学习或未来的预训练。
根据个人需求扩展更多的机器人操作任务。
10.
CALVIN
http://calvin.cs.uni-freiburg.de/
2026-05-15榜单截图
推出时间:2021年12月
全称:Composing Actions from Language and Vision
论文:《CALVIN:A benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks》
简介:
CALVIN是一个开源的模拟基准测试,专注于长视野的语言条件策略学习。它旨在开发能够通过人类语言指令解决多种机器人操作任务的智能体,涵盖多模态感知、动态交互与任务泛化能力的综合测试。
11.
RLBench
https://sites.google.com/view/rlbench
推出时间:2019年9月
论文:《RLBench:The Robot Learning Benchmark & Learning Environment》
简介:
RLBench是一个用于测试和比较机器人学习算法的基准测试。面向RL、模仿学习、多任务学习、几何计算机视觉、小样本学习等。
12.
MIKASA
https://sites.google.com/view/memorybenchrobots/
推出时间:2025年02月
全称:Memory-Intensive Skills Assessment Suite for Agents
论文:《Memory, Benchmark & Robots: A Benchmark for Solving Complex Tasks with Reinforcement Learning》
简介:
MIKASA是面向强化学习(RL)智能体长时记忆能力的统一评测基准,核心解决RL记忆评估碎片化、机器人操作无专用记忆基准的问题,包含MIKASA-Base与MIKASA-Robo两部分,形成从通用诊断到机器人实操的完整评估体系。
13.
ManiSkill 2
https://sapien.ucsd.edu/challenges/maniskill/
推出时间:2023年2月
定位:新一代SAPIEN操作技能基准测试平台,旨在解决研究人员在使用通用化操作技能基准时常见的关键痛点。
论文:《ManiSkill2:A Unified Benchmark for Generalizable Manipulation Skills》
简介:
该平台涵盖20类操作任务,包含2000余个物体模型与超400万帧演示数据,支持通过全动态引擎模拟的固定/移动基座、单/双臂、刚体/软体操作任务,兼容2D/3D输入数据。其定义的统一接口与评估协议可广泛支持各类算法(如经典感知-规划-执行、强化学习、模仿学习)、视觉观测(点云、RGBD)及控制器(如动作类型与参数化方案)。
14.
RoboMME
http://omninavbench.cloud-ip.cc
推出时间:2026年3月
论文:《RoboMME:Benchmarking and Understanding Memory for Robotic Generalist Policies》
团队:密歇根大学、斯坦福大学、Figure AI等机构联合推出。
简介:
RoboMME benchmark首次将机器人记忆划分为 temporal(时间)、spatial(空间)、object(物体)、procedural(程序)四大维度,通过16个细分任务和770k高质量训练时序,为记忆增强型机器人策略提供了统一的评估标准。这一突破不仅解决了此前评估碎片化的问题,更通过14种记忆增强型VLA模型的对比实验,揭示了不同记忆表征的适用场景。
15.
HumanoidBench
https://humanoid-bench.github.io/
推出时间:2024年3月
论文:《HumanoidBench:Simulated Humanoid Benchmark for Whole-Body Locomotion and Manipulation》
简介:
高维仿真机器人学习基准测试平台 HumanoidBench,其特色在于配备灵巧手的人形机器人及一系列具有挑战性的全身操控与移动任务。研究发现,当前最先进的强化学习算法在多数任务中表现欠佳,而分层学习基线方法在稳健底层策略(如行走或抓取)支持下能够获得更优性能。通过 HumanoidBench,为机器人学界提供了一个平台,用于识别人形机器人在执行多样化任务时面临的挑战,从而助力算法与构想的快速验证。
16.
SimplerEnv
https://github.com/simpler-env/SimplerEnv
推出时间:2024年5月
定位:面向通用机器人操作策略的real-to-sim仿真评估基准
论文:《Evaluating Real-World Robot Manipulation Policies in Simulation》
推出机构:斯坦福大学、伯克利大学和MIT等机构合作开发。
简介:
SimplerEnv 是一个针对真实机器人设置的模拟操作策略评估环境。该项目旨在解决当前操作策略在现实世界中评估困难的问题。SimplerEnv 利用物理仿真器作为高效、可扩展和有信息量的现实世界评估补充。这些仿真评估提供了有价值的定量指标,用于检查点选择、洞察潜在的真实世界策略行为或故障模式,并提供了标准化设置以增强可重复性。
17.
RoboTwin 2.0
https://robotwin-platform.github.io/
推出时间:2025年6月
定位:用于鲁棒双臂机器人操作的可扩展数据生成器和基准
论文:《RoboTwin 2.0:A Scalable Data Generator and Benchmark with Strong Domain Randomization for Robust Bimanual Robotic Manipulation》
推出团队:Tianxing Chen,穆尧,等
简介:
该框架从任务代码生成模块开始,利用多模态大语言模型(MLLMs)和仿真闭环反馈,从自然语言指令自动合成可执行任务计划。该模块基于大规模物体资产库(RoboTwin-OD)和预定义技能库,支持在广泛物体类别和操作场景中进行可扩展任务实例化。
18.
RoboMemArena
https://robomemarena.github.io/
推出时间:2026年5月
定位:一个全面且富有挑战性的机器人记忆基准
论文:《RoboMemArena: A Comprehensive and Challenging Robotic Memory Benchmark》
推出机构:香港科技大学(广州)牵头,联合浙江大学、西湖大学、清华大学、浙江工业大学、上海交通大学等团队
简介:
RoboMemArena 是一个面向长程机器人操作中 memory 能力 的系统化评测基准,核心目标是解决现有机器人 benchmark 在记忆评测上的几类关键缺口:缺乏支持 memory formation 的多模态标注、任务长度和多样性不足,以及缺少与 simulation 对齐的真实机器人验证。它希望回答的不是“模型能不能做动作”,而是“模型能不能在部分可观测、长时程、多阶段任务中真正记住过去发生了什么”。
19.
WoW-World-Eval
推出时间:2026年1月
定位:具身世界模型设立新的基准测试
论文:《Wow, wo, val!A Comprehensive Embodied World Model Evaluation Turing Test》
推出机构:北京大学,Beijing Innovation Center of Humanoid Robotics,香港科技大学
简介:
针对具身AI领域,WoW-World-Eval设计了首个覆盖感知、规划、预测、泛化、执行五大核心能力的世界模型基准,填补了现有基准缺少规划、执行维度评估的空白,是目前最全面的具身世界模型基准。
20.
RoboHiMan
推出时间:2025年10月
定位:长时程操作中组合泛化的分层评估范式
论文:《RoboHiMan:A Hierarchical Evaluation Paradigm for Compositional Generalization in Long-Horizon Manipulation》
简介:
RoboHiMan是一个面向机器人长时程操作任务的评测基准,旨在评估机器人在组合泛化和抗扰动方面的能力。它包含两大部分:
HiMan-Bench基准测试:基于 DeCoBench 的技能设计和 Colosseum 的扰动设计,构建了114 个原子任务 + 144 个组合任务,并按 “是否含扰动” 分为 4 类任务,实现对 “原子技能掌握→技能组合→抗扰动性” 的分层评估。
分层评估范式:RoboHiMan 设计了3 种评估模式,分别测试 “无规划的执行能力”“规划与执行的独立能力”“规划 + 执行的协同能力”,实现故障定位。
仿真基准的繁荣,本质上是我们在试图用算法去量化“常识”。
无论是考察长时记忆(MIKASA/RoboMME)、终身学习(LIBERO),还是工业级应用(Isaac Lab-Arena)和高维双臂协同(RoboTwin 2.0),硬核评测的最终指向只有一个:让机器人走出“控制变量”的舒适区。
只有在仿真环境中解决了抗扰动、逻辑泛化和多模态指令对齐,我们离那个真正能走进千家万户的通用机器人,才算迈出了实质性的一步。

推荐阅读





×
右键可直接复制图片